StarRocks 物化视图创建与刷新全流程解析
最近在为 StarRocks 的物化视图增加多表达式支持的能力,于是便把物化视图(MV)的创建刷新流程完成的捋了一遍。
之前也写过一篇:StarRocks 物化视图刷新流程和原理,主要分析了刷新的流程,以及刷新的条件。
这次从头开始,从 MV 的创建开始来看看 StarRocks 是如何管理物化视图的。
创建物化视图
1 | |
创建物化视图的时候首先会进入这个函数:com.starrocks.sql.analyzer.MaterializedViewAnalyzer.MaterializedViewAnalyzerVisitor#visitCreateMaterializedViewStatement
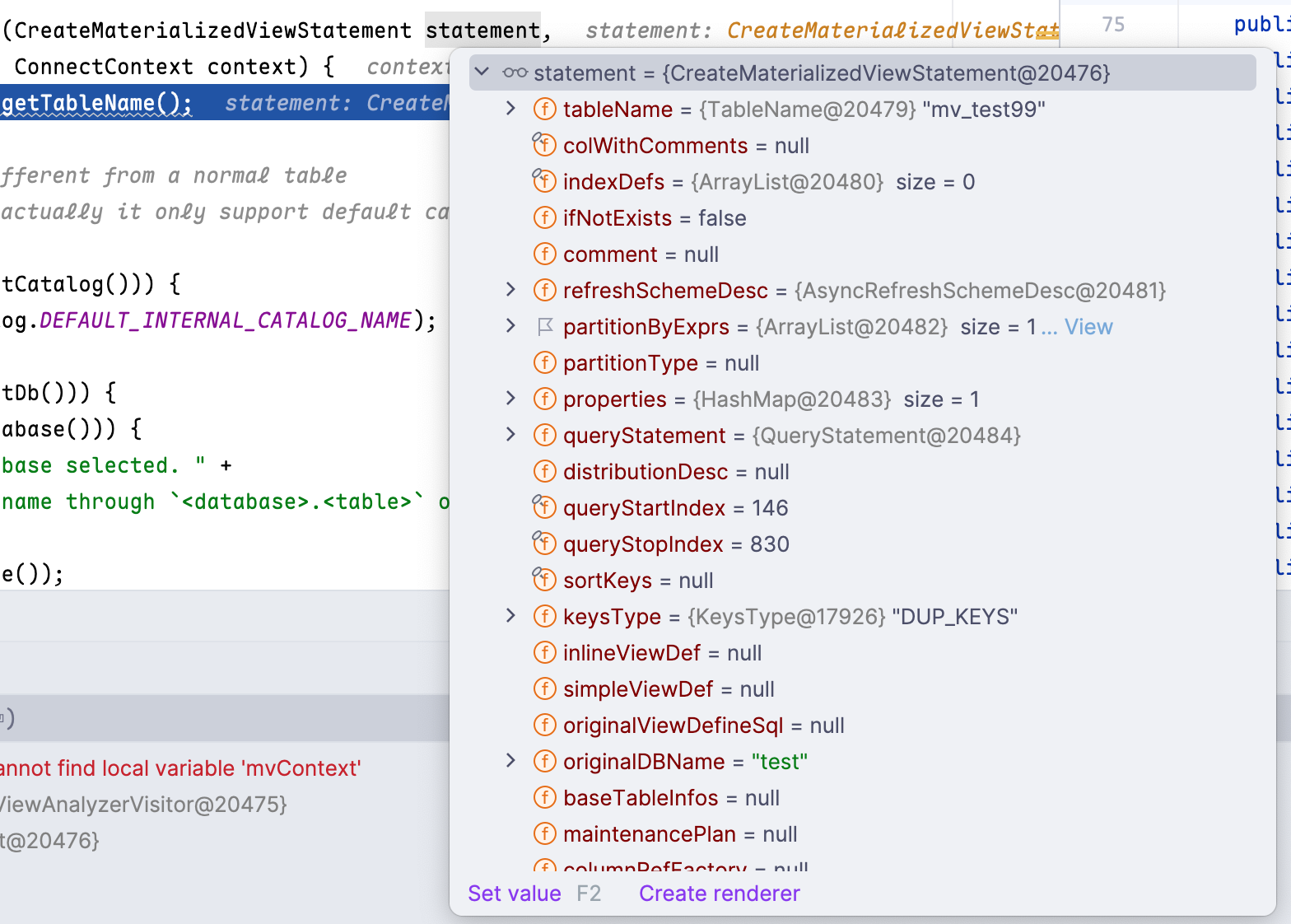
其实就是将我们的创建语句结构化为一个
CreateMaterializedViewStatement对象,这个过程是使用 ANTLR 实现的。
这个函数负责对创建物化视图的 SQL 语句进行语义分析、和基本的校验。
比如:
- 分区表达式是否正确
- 基表、数据库这些的格是否正确

校验分区分区表达式的各种信息。
然后会进入函数:com.starrocks.server.LocalMetastore#createMaterializedView()
这个函数的主要作用如下:
检查数据库和物化视图是否存在。
初始化物化视图的基本信息:
- 获取物化视图的列定义(schema)
- 验证列定义的合法性
- 初始化物化视图的属性(如分区信息)。
处理刷新策略:
- 根据刷新类型(如
ASYNC、SYNC、MANUAL或INCREMENTAL)设置刷新方案。 - 对于异步刷新,设置刷新间隔、开始时间等,并进行参数校验。
- 根据刷新类型(如
创建物化视图对象:
- 根据运行模式(存算分离和存算一体)创建不同类型的物化视图对象
- 设置物化视图的索引、排序键、注释、基础表信息等。
处理分区逻辑:
- 如果物化视图是非分区的,创建单一分区并设置相关属性。
- 如果是分区的,解析分区表达式并生成分区映射关系
绑定存储卷:
- 如果物化视图是云原生类型,绑定存储卷。

- 如果物化视图是云原生类型,绑定存储卷。
序列化关键数据
对于一些核心数据,比如分区表达式、原始的创建 SQL 等,需要再重启的时候可以再次加载到内存里供后续使用时;
就需要将这些数据序列化到元数据里。
这些数据定期保存在 fe/meta 目录中。
我们需要序列化的字段需要使用 @SerializedName注解。
1 | |
同时在 com.starrocks.catalog.MaterializedView#gsonPreProcess/gsonPostProcess 这两个函数中将数据序列化和反序列化。
元数据的同步与加载
当 StarRocks 的 FE 集群部署时,会由 leader 的 FE 启动一个 checkpoint 线程,定时扫描当前的元数据是否需要生成一个 image.${JournalId} 的文件。
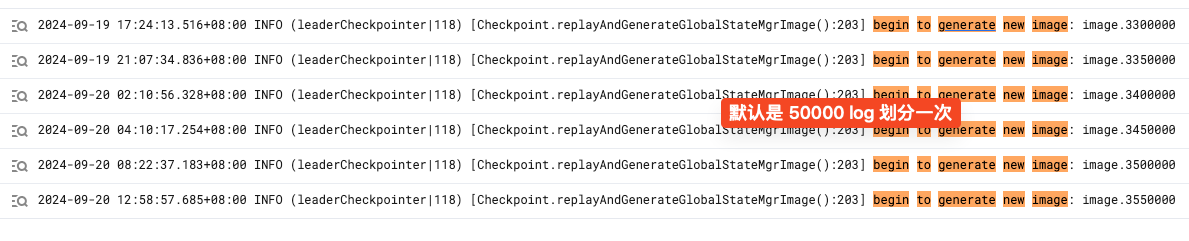
其实就是判断当前日志数量是否达到上限(默认是 5w)生成一次。
具体的流程如下: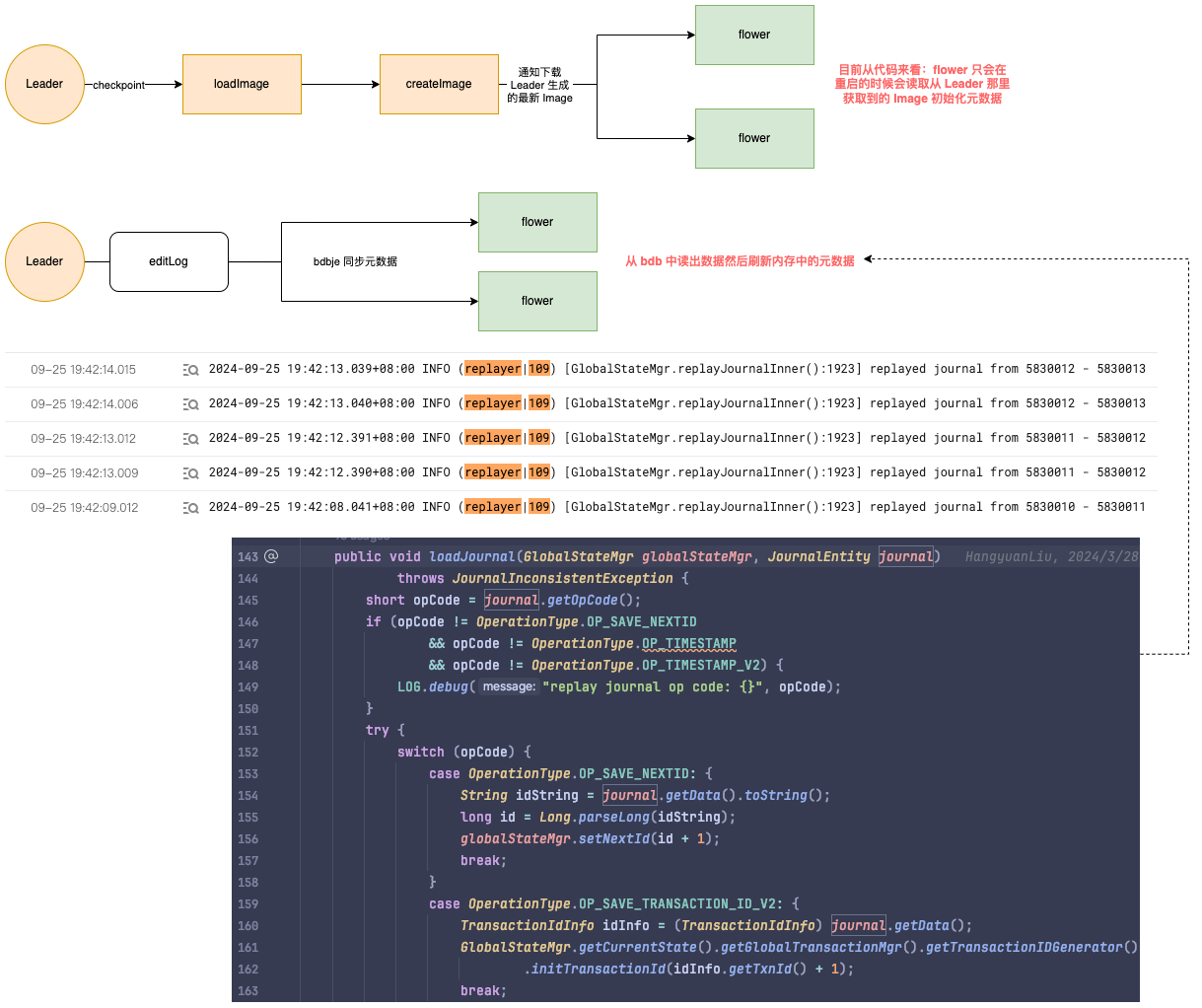
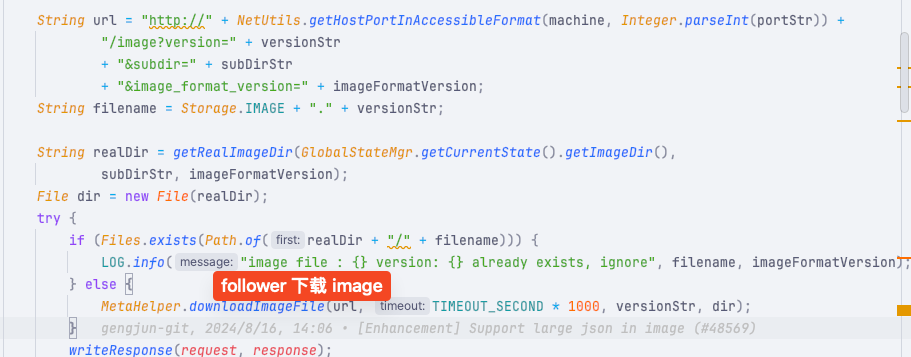

更多元数据同步和加载流程可以查看我之前的文章:深入理解 StarRocks 的元数据管理
刷新物化视图
创建完成后会立即触发一次 MV 的刷新逻辑。
同步分区

刷新 MV 的时候有一个很重要的步骤:同步 MV 和基表的分区。
这个步骤在每次刷新的时候都会做,只是如果基表分区和 MV 相比没有变化的话就会跳过。
这里我们以常用的 Range 分区为例,核心的函数为:com.starrocks.scheduler.mv.MVPCTRefreshRangePartitioner#syncAddOrDropPartitions
它的主要作用是同步物化视图的分区,添加、删除分区来保持 MV 的分区与基础表的分区一致;核心流程:
- 计算分区差异:根据指定的分区范围,计算物化视图与基础表之间的分区差异。
- 同步分区:
- 删除旧分区:删除物化视图中与基础表不再匹配的分区。
- 添加新分区:根据计算出的差异,添加新的分区到物化视图。

分区同步完成之后就可以计算需要刷新的分区了: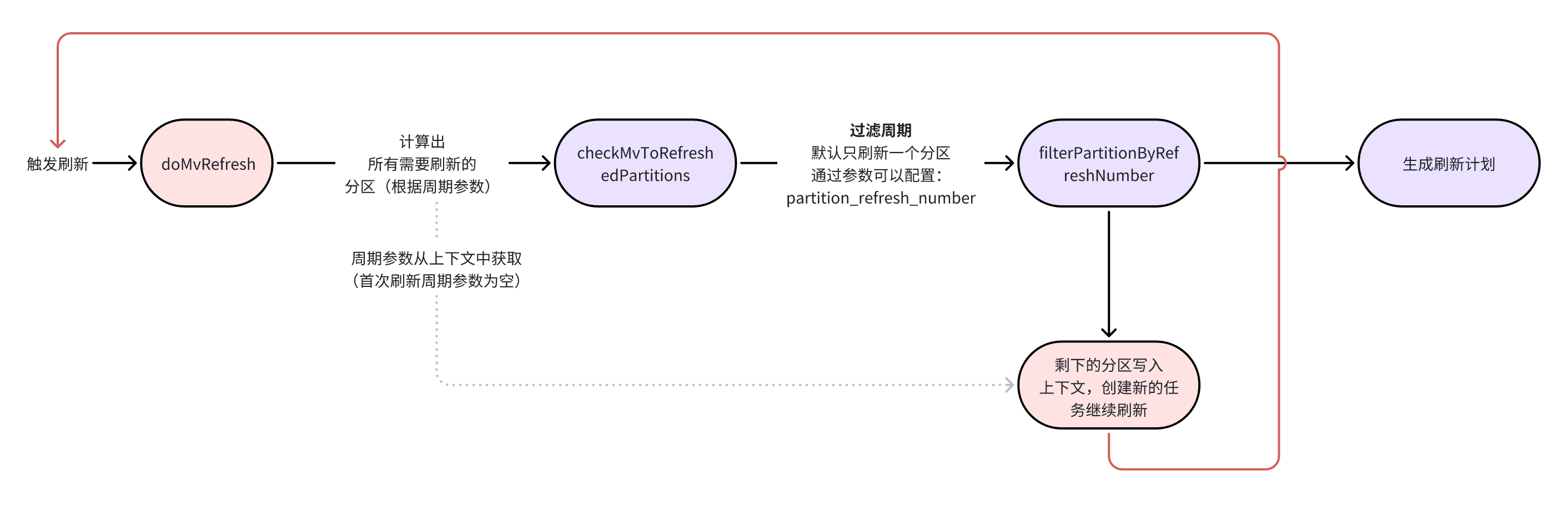
以上内容再结合之前的两篇文章:
就可以将整个物化视图的创建与刷新的核心流程掌握了。
#StarRocks #Blog