StarRocks 监控中有一个很关键的指标,就是针对慢 SQL 的监控。
在 StarRocks 中审计日志记录了所有用户的查询和连接信息,理论上我们只需要对这些日志进行分析就可以得到相关的慢 SQL,高 CPU、高内存的 SQL 信息。
类似于这样的监控界面:
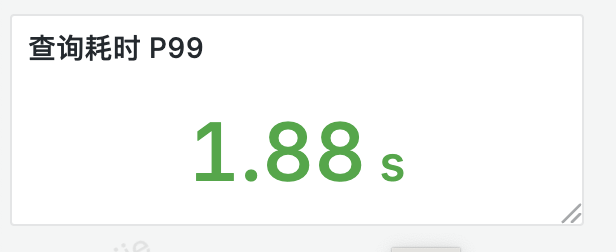



由于这些数据都是存放在日志文件里的我们想把他拿到 grafna 里展示的话得额外处理下。
结构化日志
默认情况下审计日志是以文本格式输出的,当然我们也可以使用一个审计插件,将审计日志写入到一张单独的表里供后续分析,也可以实现类似的效果。
具体使用可以参考官方文档:

这里我们选择一个更简单的方法,我们可以将日志输出为 JSON 格式,然后再将其结构化,为每个字段创建索引,存入到单独的日志服务里。

由于我们使用了云厂商的日志服务能力,只需要为这个日志文件(fe/log/fe.audit.log)配置一个采集服务,然后为其中的字段创建索引即可。
这样我们可以就可以通过云厂商提供的 grafna 插件将这里的日志作为一个数据源集成到 grafna 中。
之后就可以在 grafna 中直接使用云厂商提供的查询语法来查询我们刚才的审计日志了。
1
| IsQuery:"true"|SELECT QueryId,Stmt,Time,CpuCostNs,MemCostBytes,ScanBytes,ScanRows,ReturnRows ORDER BY CpuCostNs DESC LIMIT 10
|
比如这样的查询语句含义是:限制为查询的 SQL(还有其他的 alter delete 等 SQL)、按照 CPU 耗时排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| CREATE TABLE starrocks_audit_db__.starrocks_audit_tbl__ (
`queryId` VARCHAR(64) COMMENT "查询的唯一ID",
`timestamp` DATETIME NOT NULL COMMENT "查询开始时间",
`queryType` VARCHAR(12) COMMENT "查询类型(query, slow_query, connection)",
`clientIp` VARCHAR(32) COMMENT "客户端IP",
`user` VARCHAR(64) COMMENT "查询用户名",
`authorizedUser` VARCHAR(64) COMMENT "用户唯一标识,既user_identity",
`resourceGroup` VARCHAR(64) COMMENT "资源组名",
`catalog` VARCHAR(32) COMMENT "数据目录名",
`db` VARCHAR(96) COMMENT "查询所在数据库",
`state` VARCHAR(8) COMMENT "查询状态(EOF,ERR,OK)",
`errorCode` VARCHAR(512) COMMENT "错误码",
`queryTime` BIGINT COMMENT "查询执行时间(毫秒)",
`scanBytes` BIGINT COMMENT "查询扫描的字节数",
`scanRows` BIGINT COMMENT "查询扫描的记录行数",
`returnRows` BIGINT COMMENT "查询返回的结果行数",
`cpuCostNs` BIGINT COMMENT "查询CPU耗时(纳秒)",
`memCostBytes` BIGINT COMMENT "查询消耗内存(字节)",
`stmtId` INT COMMENT "SQL语句增量ID",
`isQuery` TINYINT COMMENT "SQL是否为查询(1或0)",
`feIp` VARCHAR(128) COMMENT "执行该语句的FE IP",
`stmt` VARCHAR(1048576) COMMENT "SQL原始语句",
`digest` VARCHAR(32) COMMENT "慢SQL指纹",
`planCpuCosts` DOUBLE COMMENT "查询规划阶段CPU占用(纳秒)",
`planMemCosts` DOUBLE COMMENT "查询规划阶段内存占用(字节)",
`pendingTimeMs` BIGINT COMMENT "查询在队列中等待的时间(毫秒)",
`candidateMVs` varchar(65533) NULL COMMENT "候选MV列表",
`hitMvs` varchar(65533) NULL COMMENT "命中MV列表",
`warehouse` VARCHAR(128) NULL COMMENT "仓库名称"
)
|
审计数据里的信息非常丰富,可以组合出各种查询条件。
比如:
- 限制查询时间大于多少,可以只查询慢 SQL
- 根据内存占用排序
- 执行失败的 SQL
大家可以按需选择。
开源替换
如果没有使用云厂商,一些开源组件也能满足以上需求:
- 结构化存储日志
- 根据字段创建索引
- 类 SQL 查询
- 支持 grafna 数据源,方便做可视化
| 服务名称 |
索引能力 |
查询语言 |
Grafana 支持 |
优点 |
缺点 |
适用场景 |
| Elasticsearch |
全文索引、倒排索引 |
Elasticsearch DSL(类 SQL) |
官方插件,集成完善 |
功能强大、生态成熟、搜索能力强 |
资源占用大、运维成本高、JVM 调优复杂 |
大规模日志搜索、全文检索 |
| Loki |
仅索引标签(Label) |
LogQL |
原生支持,集成最佳 |
轻量级、成本低、与 Grafana 生态完美 |
全文搜索能力弱、不适合复杂查询 |
中小规模、成本敏感、Grafana 用户 |
| ClickHouse |
主键索引、二级索引、跳数索引 |
标准 SQL |
官方插件支持 |
查询速度极快、擅长 OLAP、支持复杂聚合 |
不适合高频更新、需要结构化设计 |
结构化日志分析、大数据量聚合查询 |
| OpenSearch |
全文索引、倒排索引 |
OpenSearch DSL(兼容 ES) |
兼容 ES 插件 |
完全开源、无商业限制、功能与 ES 相近 |
社区相对较小、资源占用仍较大 |
ES 的开源替代方案 |
内部日志支持 JSON
StarRocks 还有定期执行的内部 SQL,目前这些 SQL 也是会记录日志,但只是记录的纯文本,无法很好的对其进行监控。
我们就出现过内部 SQL 大量占用了 CN 的 CPU 资源,将它的执行时间控制到 00:00:00~08:00:00 之后就会好很多了,只是不会影响到白天的业务使用。
1
2
3
4
5
6
7
|
@ConfField(mutable = true)
public static String statistic_auto_analyze_start_time = "00:00:00";
@ConfField(mutable = true)
public static String statistic_auto_analyze_end_time = "23:59:59";
|
主要是这两个配置控制的时间范围,修改之后 CN CPU 使用有明显的下降:
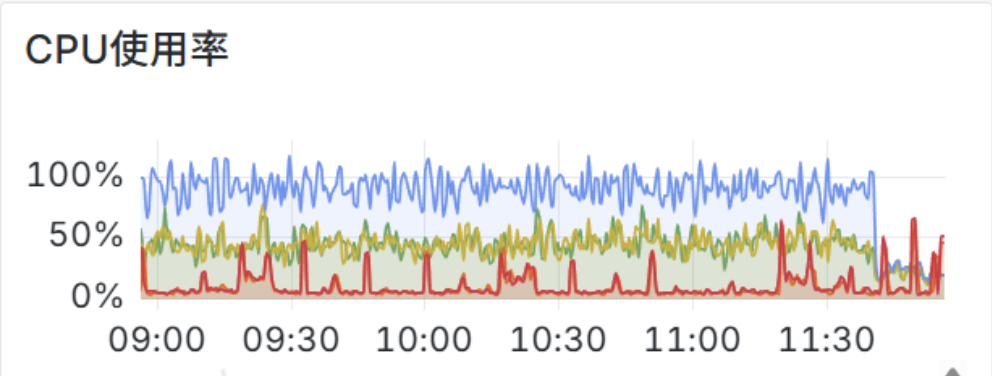
为了方便后续对这部分内部 SQL 进行监控,提交了一个 PR 用于支持内部日志输出 JSON,这样采集日志之后就可以参考上面的审计日志对内部 SQL 进行监控了。
#Blog
){kind=link}