大模型应用开发必需了解的基本概念
背景
AI/LLM 大模型最近几年毋庸置疑的是热度第一,虽然我日常一直在用 AI 提效,但真正使用大模型做一个应用的机会还是少。
最近正好有这么个机会,需要将公司内部的代码 repo 转换为一个 wiki,同时还可以基于项目内容进行对话了解更具体的内容。
实际效果大概和上半年很火的 deepwiki 类似。
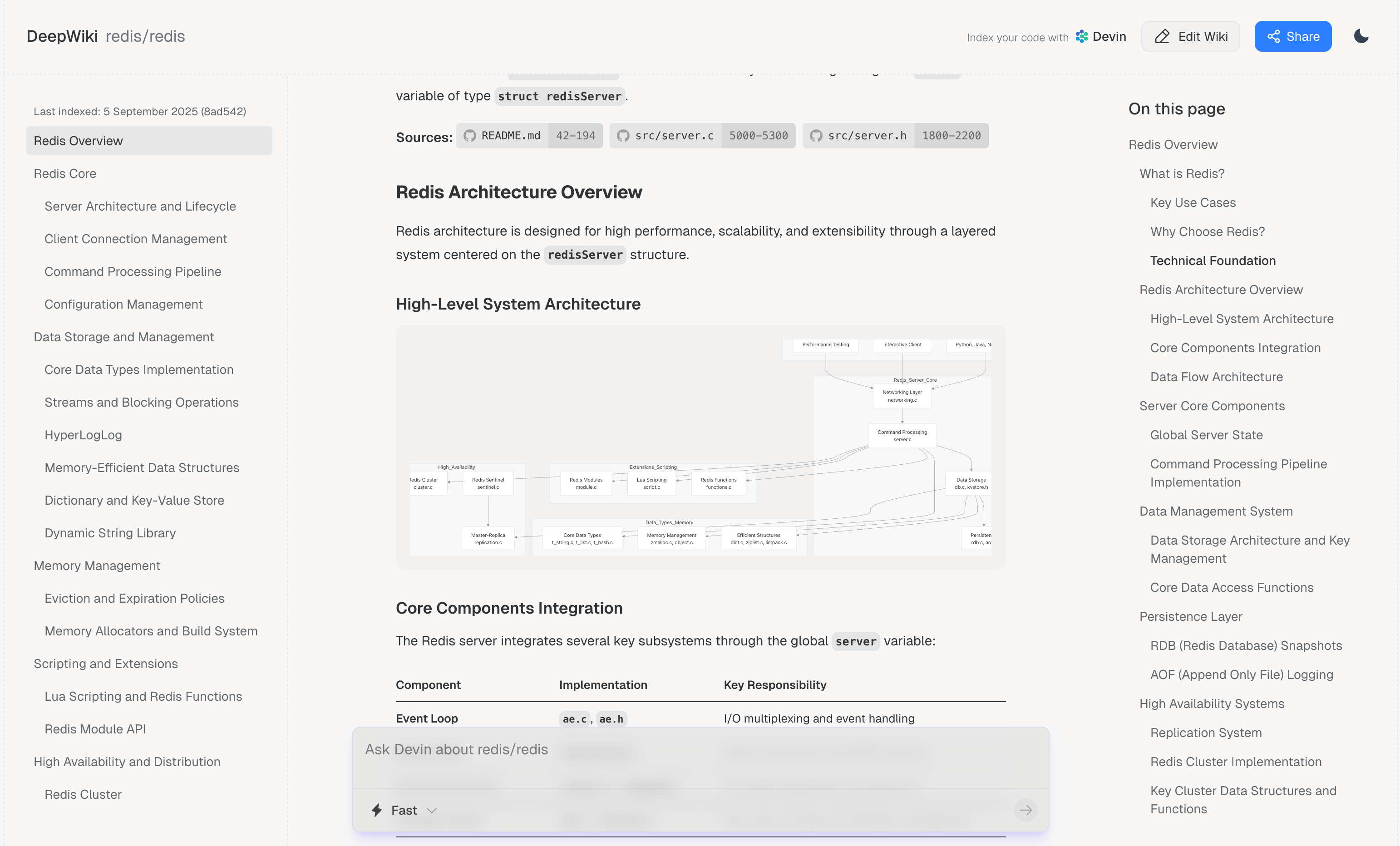
而我们是想基于开源的 deepwiki-open进行开发,提供的功能都是类似的。
在这个过程中我也从一个大模型应用开发的小白逐步理解了其中的一些关键概念,以及了解了一个大模型应用的运行原理。
LLM
LLM(Large Language Model,大语言模型)大家应该都比较熟悉了:
- 本质:一个通过海量文本训练出来的概率模型
- 能力:理解/生成文本、代码,做推理、对话等
- 特点:
- 参数固定:训练完之后“记忆”是固化在参数里的
- 知识有时间点:只知道训练截止前的数据(有知识截止时间)
可以把 LLM 当成一个“通用大脑”,但不一定知道最新的、你的私有数据。
目前的 AI 也就是大模型本质上还是概率预测,当你给它一段话(Prompt)时,它在后台做的事情是:“根据我读过的几万亿字,接在这段话后面,概率最高的下一个字(Token)是什么?”
所以大模型每次回答的内容可能不同,也不能 100% 的告诉你准确答案。
Token
大模型并不直接认识java、Rust 或者“编程”这些词。在模型内部,所有的文字都会先被转换成一系列数字。
- 字/词 ≠ Token:一个 Token 既不是一个字符,也不是一个单纯的单词。
- 灵活切分:
- 常见的词(如
the,apple)通常对应 1 个 Token。 - 罕见的词或长的复合词(如
microservices)可能会被拆分成几个 Token(如micro+services)。 - 中文通常比较特殊:一个常用的汉字可能是 1 个 Token,但不常用的汉字可能会占用 2-3 个 Token。
- 常见的词(如
在做大模型应用开发的时候尤其需要注意 token 的用量,毕竟这是计费的标准。
还有一个是上下文窗口的限制,每个模型都会有最大 token 的限制(如 8k, 32k, 128k)。
如果你的 Prompt 加上模型的回复超过了这个限制,模型就会丢掉前面的记忆或者直接报错。
在日常开发估算中,可以大概估算一下这个比例:
- 英文文本:1000 Tokens ≈ 750 个单词。
- 中文文本:1000 Tokens ≈ 500 到 600 个汉字(随着模型词表的演进,现在的模型处理中文的效率在不断提升。)。
- 代码:代码中的空格、缩进和特殊符号都会消耗 Token。Python 等由于缩进较多,消耗通常比纯文本快。
也有相关的库可以帮我们计算 token:
1 | |
也可以通过 openai 的一个实例网站来可视化查看 token 的计算规则:
RAG
RAG 的全程是Retrieval-Augmented Generation(检索增强生成),他不是类似于 LLM 的模型,而是一种架构模式。
举个例子:
比如你问 ChatGPT 关于你们公司的某一个规章制度,大概率 ChatGPT 的训练语料是你没有你们公司的内部数据的。
所以他回复你的多半是瞎编的内容,或者直接告诉你不知道。
此时就需要 RAG 了,他可以在真正询问 LLM 之前先到内部的资料库里通过用户的问题将相关上下文查询出来,然后再拼接成一个完整的 prompt 发送给 LLM,让 LLM 根据你通过的数据进行回答。
这样能解决一下三个问题:
- 幻觉问题:你问它一个它不知道的事情,它会一本正经地胡说八道。
- 知识过时:大模型的知识停留在它训练结束的那一天。
- 私有数据安全:你不能为了让 AI 懂你的业务代码,就把几百万行私有代码全发给模型提供商训练一个新模型,那太贵且不安全。
使用 RAG 时还需要额外考虑到数据清洗的步骤,比如我们这里的 repo wiki 的场景,我们需要把一些第三方库、编译后产生的 target 目录等不需要的内容排除掉。
避免在查询时带上这些内容,干扰最终的结果。
向量数据库
上文里提到 RAG 模式,需要一个非常关键的组件,那就是向量数据库。
我们先要在 RAG 里检索出相关的上下文就是在向量数据库里做查询,具体流程如下:
- 把文档切块(段落级别)
- 用一个 Embedding 模型 把每个块转成向量
- 把这些向量存进 向量数据库
- 用户提问时,也把问题转成向量
- 用向量相似度检索出最相关的文档块
- 把这些文档块 + 问题喂给 LLM,让它生成答案
简单来说就是将一些非结构化的数据(图片、视频、文字)通过Embedding 模型 转换成一串数字数组,即向量(例如:[0.12, -0.59, 0.88, ...])。
查询的时候也会将查询内容转换为向量,然后返回在向量空间里相近的数据。
Q&A
此时也许你会有以下一些问题:
LLM + RAG + 向量数据库,是不是类似于用 LLM 训练私有化数据?这两者的效果是否类似? 如果不同,区别在哪里?
LLM + RAG + 向量数据库:
本质是:
不改模型参数,用检索到的外部资料来“喂”模型,让它查完再答。
你的数据在外部(向量数据库里),只是当作参考材料塞进 prompt。
在私有数据上训练(微调 / 预训练):
本质是:
用你的数据更新模型参数,让模型“记住”这些模式和知识。
你的数据被“烤进”模型权重里,调用时不需要再查这份数据。
| 维度 | RAG(向量库) | 微调 / 私有训练 |
|---|---|---|
| 知识存放 | 外部向量库 | 模型参数里 |
| 更新成本 | 改文档即可,重建 / 增量向量索引 | 需要重新训练部署 |
| 生效时间 | 几分钟级 | 训练+上线,小时~天级 |
| 支持频繁变更 | 很适合 | 很不适合 |
| 透明度/可解释性 | 高(可以追溯到原文出处) | 低(模型直接给出,无法确切知道来源) |
总的来说使用 RAG 外挂私有化向量数据的成本更低,也更灵活。
对于一些更垂直的场景,可以考虑使用私有数据训练模型。
总结
总体下来的感受是 LLM 应用大部分的代码都是 prompt 提示词,普通 app 的主要内容是代码,而不同大模型应用的主要区别是提示词;反而代码大部分都是趋同的。
区别就是用了什么框架,但是共同的就是调用大模型 API,将传统的 request/reponse 的请求模式换为流式响应(大模型的响应很慢)。
在开发应用时,需要了解 System Prompt(系统预设角色)、User Prompt(用户提问)和 Few-shot(给模型几个例子引导它)。好的 Prompt 是让 RAG 结果准确的关键。
后续还需要更加完善 deepwiki-open:
- 优化 splitter,使用更适合代码分割的 splitter,比如 tree-sitter
- 将存储在本地的向量替换为一个独立的向量数据库
- 持续优化提示词,更加符合我们的项目背景
#Blog