企业大模型应用与 Vibe Coding 实战
背景

上周末参加了一个我们重庆本地的一个 AI 分享会,分享了一些企业大模型与 Vibe Coding 的实战经验,现在把它整理成一篇 blog。
企业大模型应用实践
利用 AI 提高故障排查效率
首先是企业大模型的应用实践,我们利用现在的大模型结合可观测性来实现故障的自动分析。
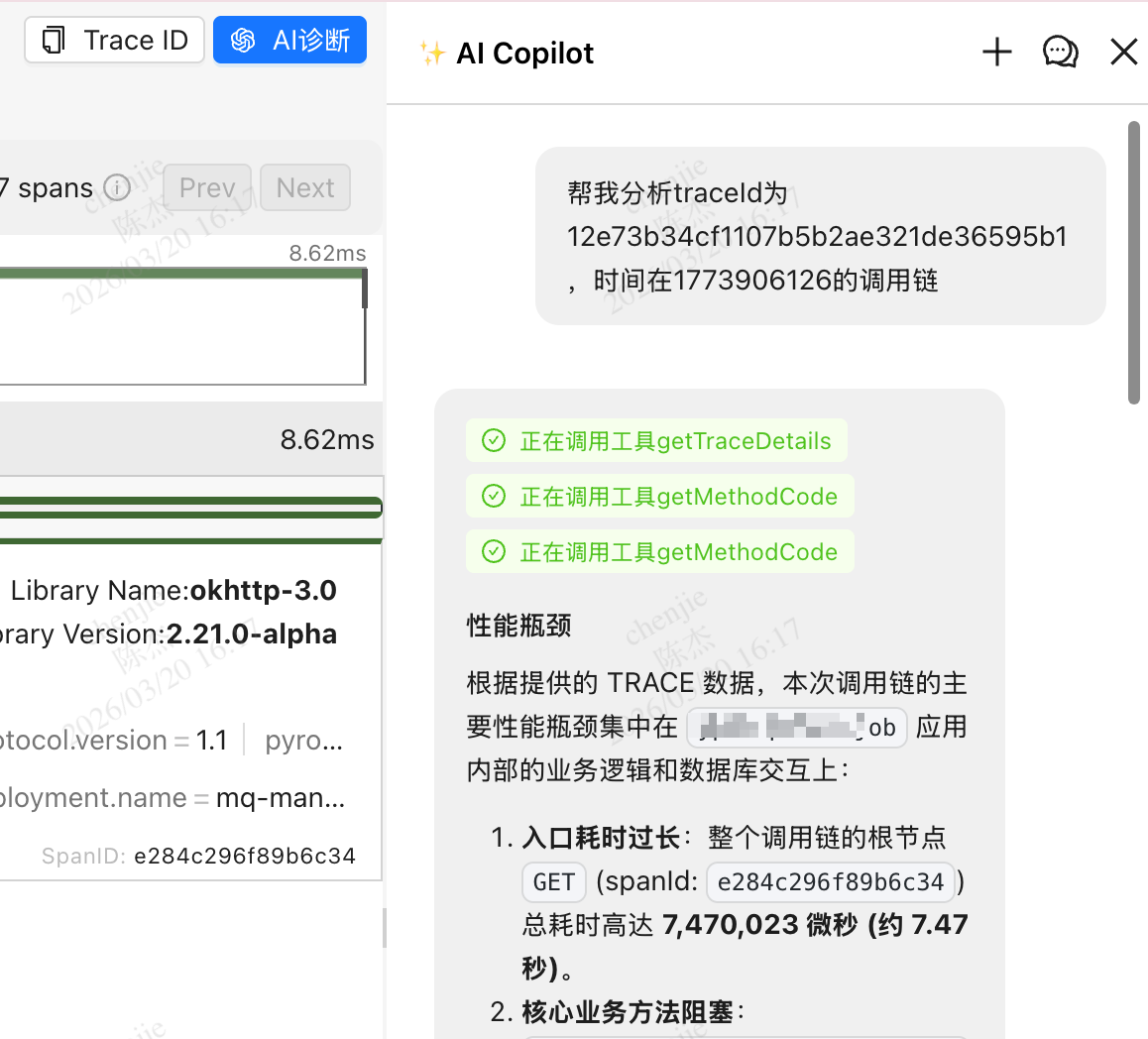
最终可以实现的效果如下图所示,他可以直接分析当前 trace 下的所有链路、日志、指标、profile、内存布局,代码等信息整理在一起发给大模型,由大模型总结整理给出结论。
其实开发日常排查问题也是这样的过程,只是将它自动化了而已。
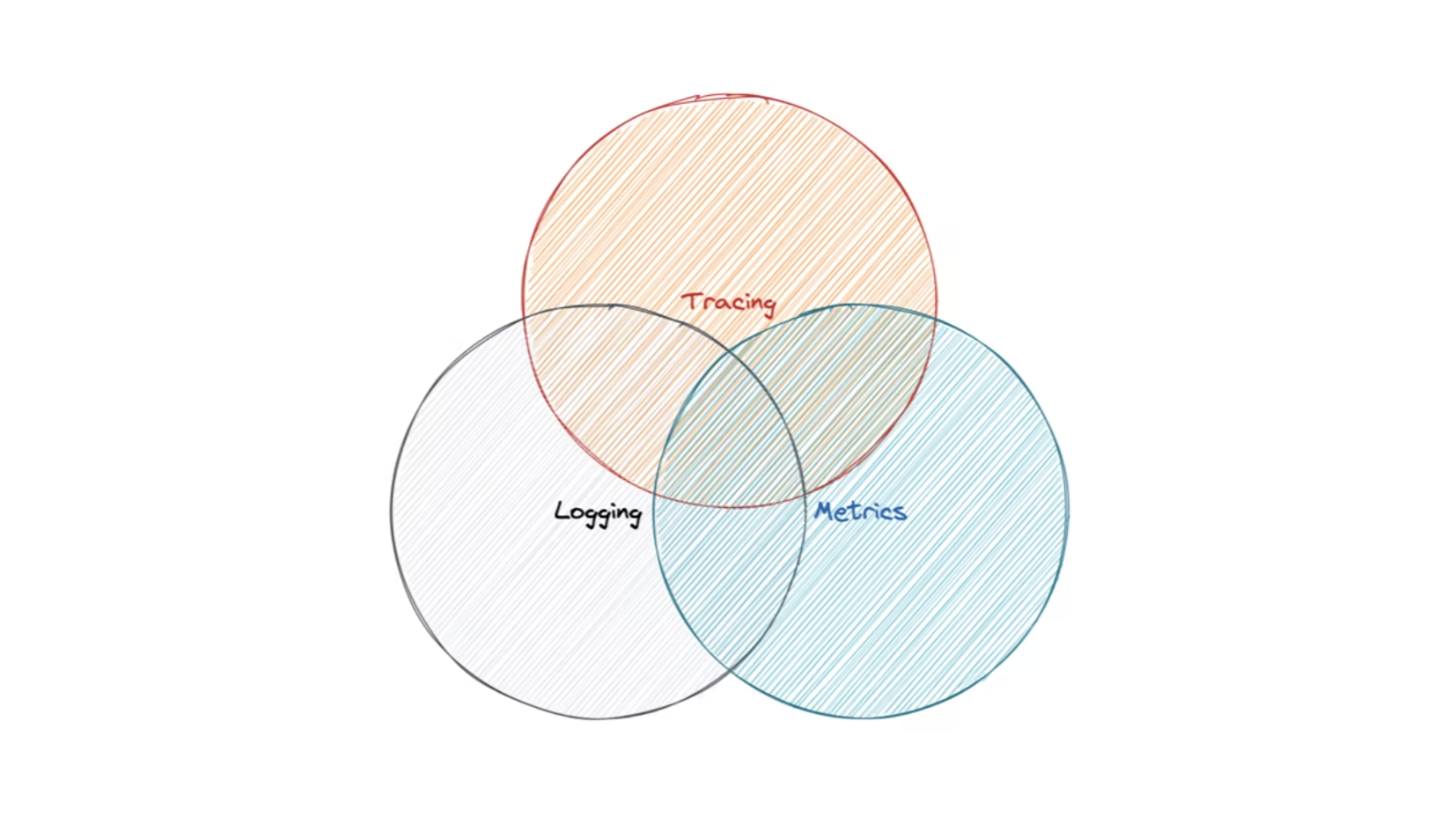
对可观测性有了解的朋友应该对这张图很熟悉,通过 trace_id 可以在日志系统里获取到日志、通过 trace 的时间戳也能获取到一个时间范围的指标监控数据。
本质上都是可以获取到这些结构化的数据,代码也是一样的,gitlab 也有相关的接口可以获取到代码信息。
这里的重点便是上下文可以给多少,给的越相关效果越好,目前我们也还在调试,给的信息多了可能也会导致大模型的幻觉。


重点:
- 尽可能能多的采集应用数据(trace、日志、指标、代码、profile 等信息)
- 上下文内容尽量聚焦
- 数据获取的方式可以直接使用基建数据的接口或者是 MCP(推荐有接口就通过接口获取)
定制属于自己的 deepwiki
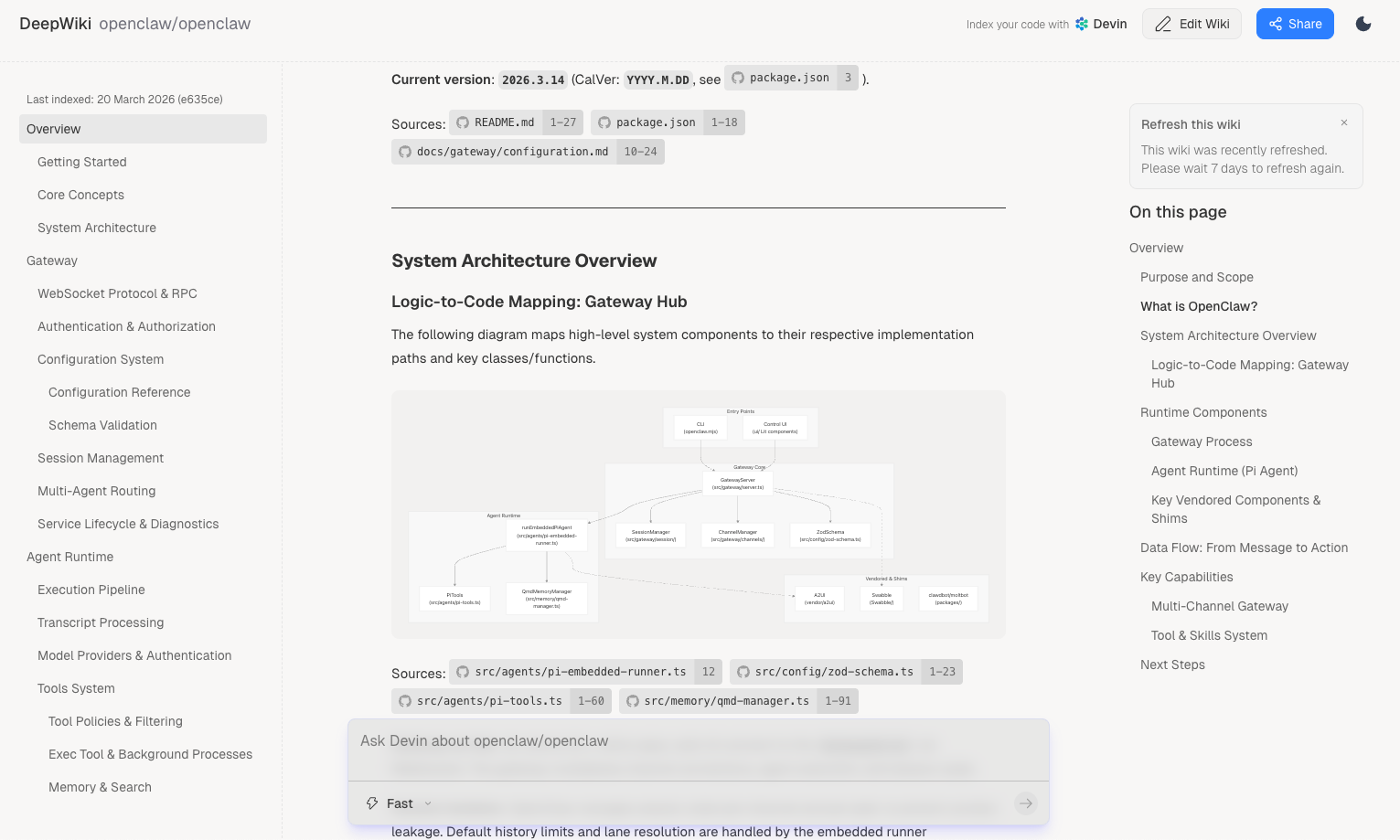
去年下半年火过一段时间的一个项目:deepwiki,利用大模型将 github 上开源的项目做成一个可多次对话的 wiki,方便我们更好的理解项目;下图是 openclaw 的 deepwiki。
我们内部也有类似的需求,需要将所有的代码 repo 做成一个 deepwiki,方便新人或者不熟的同事快速了解一个项目。
可以确定的数据不要交给 AI 生成
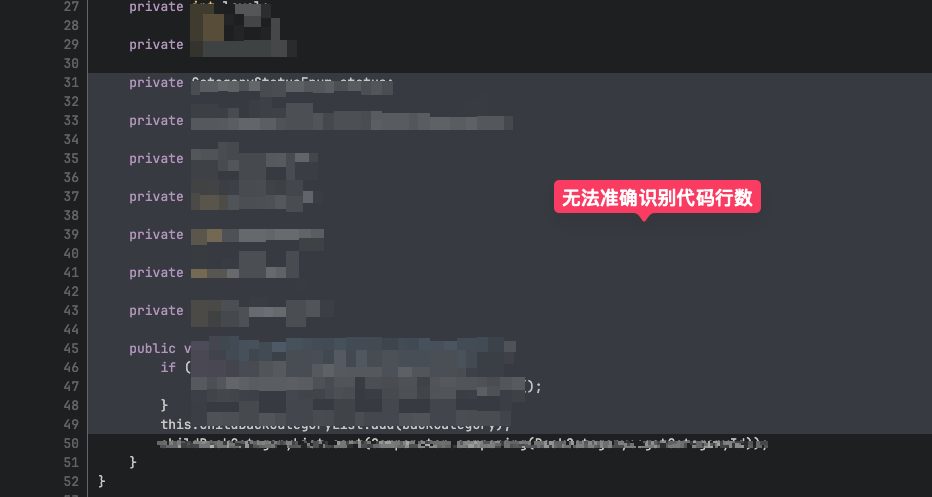
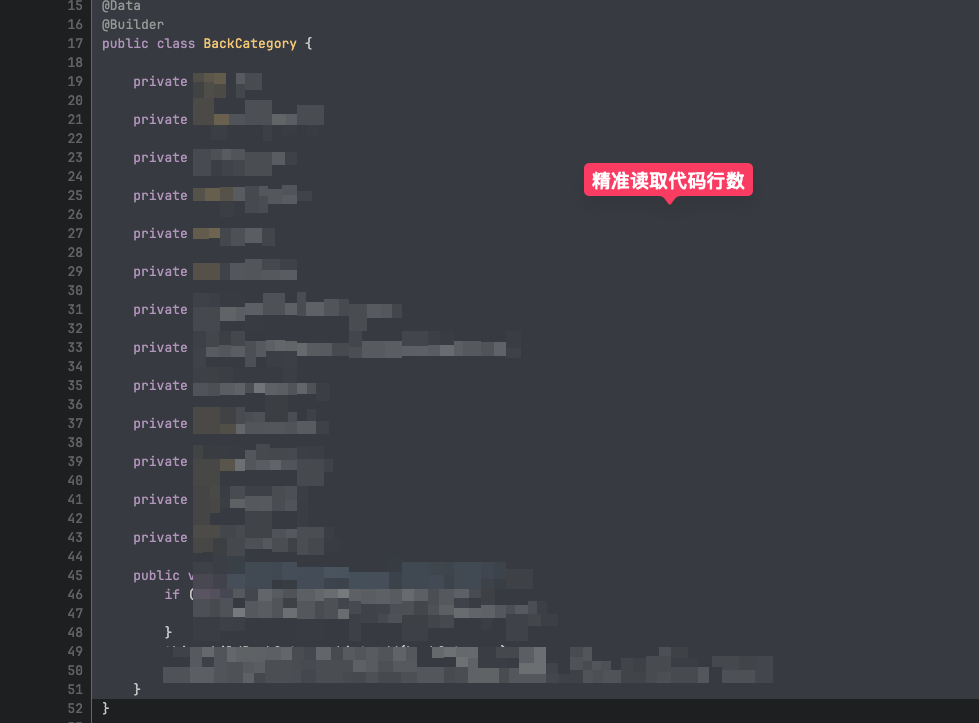
我们是用一个开源的 deepwiki-open 系统来改造的,生成出来的代码行数和业务逻辑基本上对不上,经过分析发现是 LLM 自己估算的。
后续经过优化,我们自己将代码里的行号带上发送给大模型,这个问题就基本上被解决,重点是不要让大模型做逻辑计算,有现成的数据便让他直接读取。



根据自己的业务做定制大模型应用
由于 deepwiki-open 这个项目是一个开源通用的项目,所以他没法根据自己项目的情况做优化。
比如他为了更加通用,默认对代码的分割算法是 text 分割,也就是按照英文单词进行分割,因为有可能你的项目都不是代码,而是内部的纯文本知识库。
但是对于大量代码场景会导致分割的代码片段不连贯,比如一个完整的函数被分割成了多个 chunk,导致大模型理解困难。
而更好的方案应该是根据不同的编程语言选择不同的 AST(抽象语法树)进行分割
通用方案存在的问题:
- 代码分割不够精准,需要使用指定语言的 AST(抽象语法树)进行分割。
- 目录生成太随意,应该根据项目的特征(前端后端、python、Java、Golang)生成目录树。
这是没有经过优化的目录结构,非常通用(重新生成之后就会变化),适合放到任何项目里面。
而相对应的是针对我们项目背景优化的目录结构;这样一样便知道好坏。
至于是如何优化的?那又回到了刚才的提到的:可以确定的内容就不要交给 AI 生成。
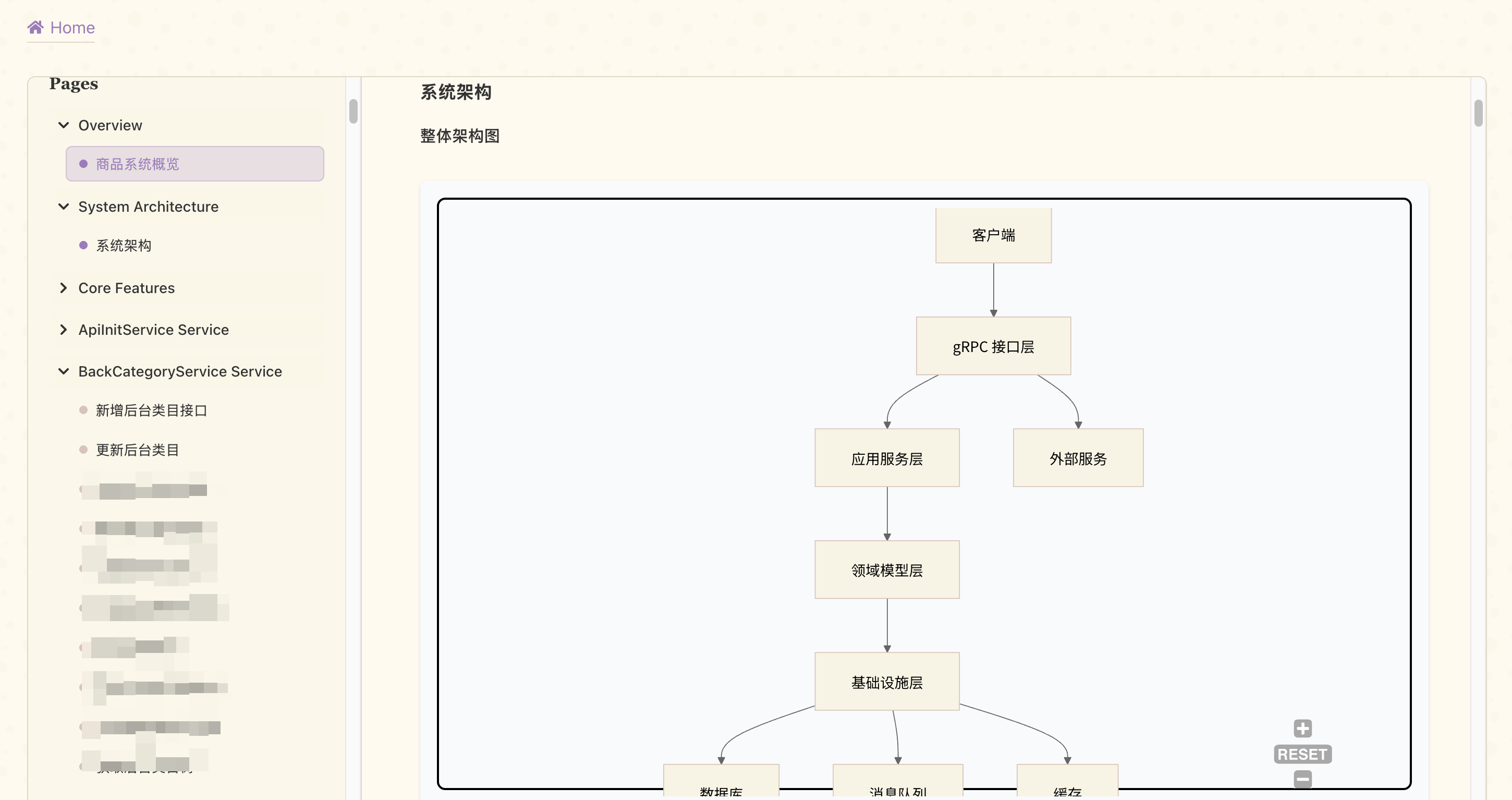
这里的目录结构我们是确定的,无论怎么重复生成都是这个目录机构,对于我们的 Java 项目来说,我们希望目录结构可以根据对外提供的 grpc 生成,这样就可以系统的结构化的来理解整个项目。
至于目录结构是如何生成的,那也很简单,就是解析下 grpc 的 proto 文件,提取出接口声明,然后再遍历生成目录就可以了。
同样的道理,对于前端项目、或者是 Python 你项目,他们的关注点都不太相同,我们需要针对性的优化,不然就只能得到一个可用的玩具。


我的经验:
- 任何可以确认的内容,尽量直接告诉大模型,而不是让他进行推理
- 大模型应用要做定制优化,通用的方案只能作为玩具。
Vibe Coding 实战经验分享
接下来要分享的是我最近 Vibe Coding 的一些经验
首先是工具的推荐,我的工作流是好用的基座大模型+ Code Agent(Claude Code/copolit-cli) + Skills
好的大模型可以节约很多时间,推荐有条件的尽量使用 Claude 的 opus4.6
而 Code Agent 可以直接帮我们编写 编译 调试代码,直接做事情,再也不需要手动复制聊天窗口里的代码到 IDE 里面再手动运行了。
Skill 可以将自己常用的工作流整理成一个可复用的模块,也可以使用行业大佬整理的 Skill,相当于偷师了各种大佬的最佳实践。
以上三者结合起来真的可以将个人打造成以往的产研小团队。
我的常用工具:
- Claude Opus4.6 / Gemini3
- Claude Code / Copilot-CLI
- Skill:偷师行业大佬经验,或者复用自己已有的工作流
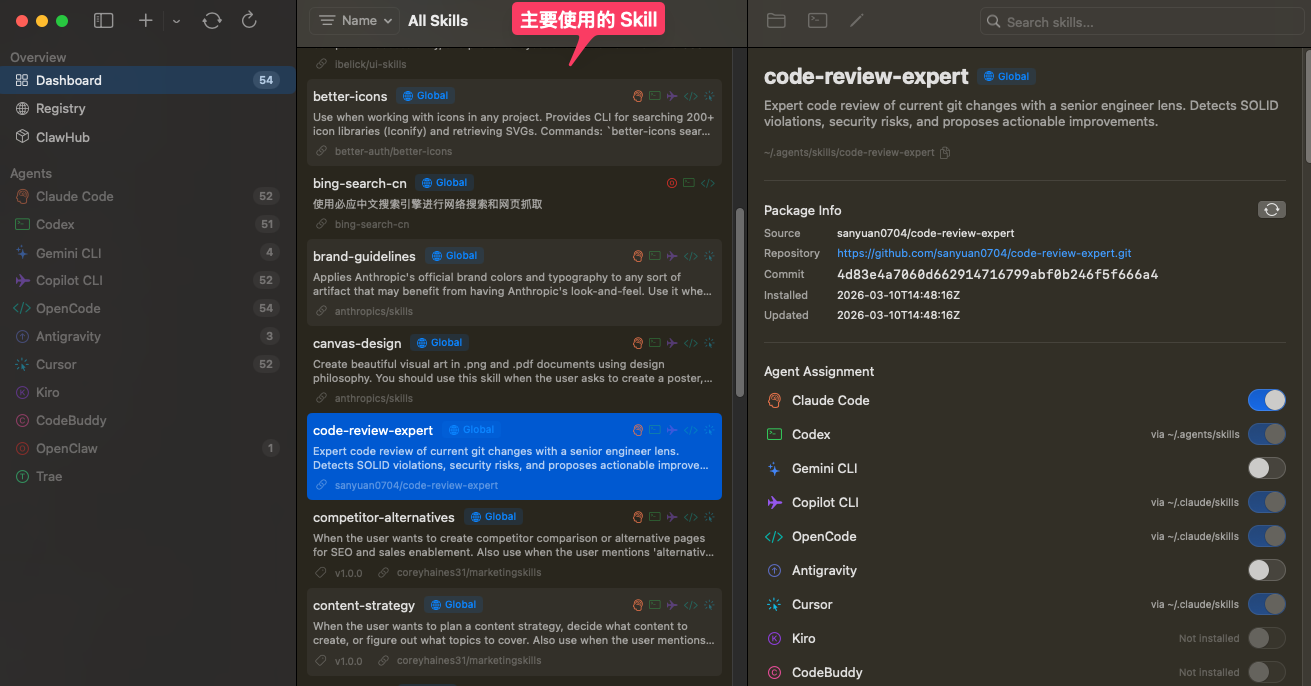
刚才的那个本地 Skill 管理工具就是我用 Claude Code vibe Coding 开发出来的,在 github 上也有一定关注度,也证明纯靠 vibe Coding 也是可以解决问题的。
下面是这段时间总结的一些 VibeCoding 经验:
开发一个具体 feature 的时候尽量聚焦一些,每次都使用独立的 context 以及 分支开发,这样不容易出现幻觉
完成一个功能之后记得提交代码,这样更方便回滚,尽量不要用自然语言让 AI 进行回滚,而是自己操作 git 进行回滚。
这又和刚才提到的,能确定的事情尽量别让 AI 去做。
AI coding 过程中,自己消耗大量 token 总结出来的内容,如果暂时用不上可以让它整理成一个文档,方便自己下次直接加载这份文档恢复上下文,避免再次分析消耗 token。
或者直接使用 claude –resume 恢复上下文
定期使用 /init 命令构建 claude.md,使得 Claude 的上下文更加准确
对于自己不熟的代码和领域,多让大模型写日志,方便他后续排查问题
在 claude.md 里声明单测优先,任何 PR 的创建都需要通过单测,尽可能的保证代码质量
多利用项目记忆以及全局记忆来约束大模型的行为,比如代码风格、输出的标准等。
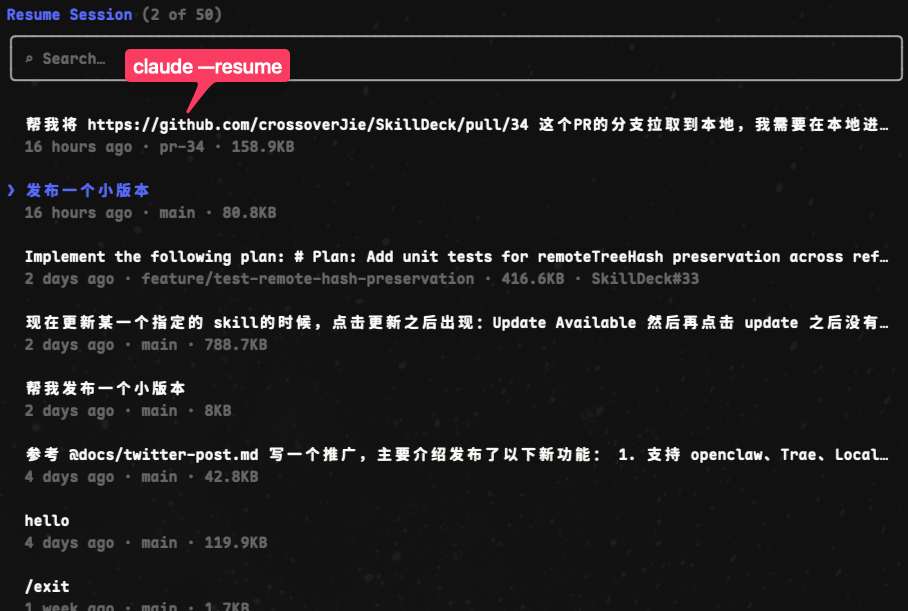
经验总结:
- 一个 feature 一个 context,避免上下文过长
- 一个 feature 一个分支,尽量使用 git 命令回滚,而不是让 AI 进行回滚(容易出错,能确定的事情就尽量确定)
- 保存好消耗大量 token 总结的文档(复杂功能的代码分析),后续可以复用,也可以使用 claude resume 恢复之前的会话
- 定期使用
/init命令初始化 claude.md - 关键逻辑让大模型多写日志,方便后续让他排查问题
- 在 claude.md 里声明单测优先(TDD),任何 PR 的创建都需要通过单测,尽可能的保证代码质量
- 多利用项目记忆以及全局记忆来约束大模型的行为,比如代码风格、输出的标准等。
独立开发工具链
- Gemini 生成产品 PRD 文档
- 将 PRD 导入 https://stitch.withgoogle.com/ & pencil.dev 生成 UI 设计稿
- 将 UI 设计稿导出成 html,或者是 MCP 到 Figma
- 由 Claude Code 读取设计稿实现页面
- app logo 使用 superdesign MCP 生成 SVG
总结
正如 anthropic CEO 在之前的播客里提到:未来 software engineer 这个 title 真的会消失,取而代之的可能是 product manager 或者叫做 builder。
放到前两年我是不太信的,这几个月我充分使用 AI Coding 之后我信了,对大部分开发者来说既是挑战也是机遇。