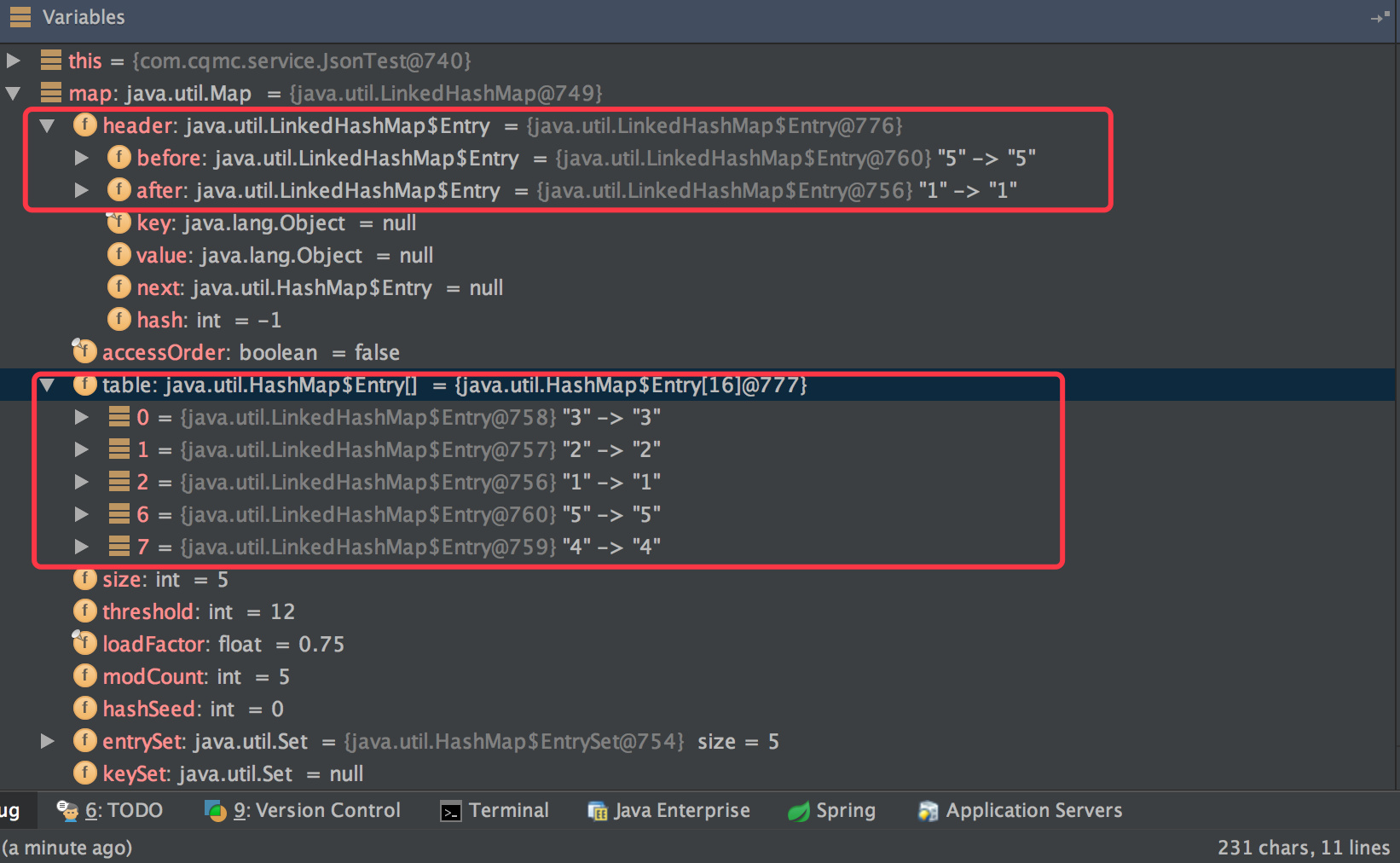
/** * The head of the doubly linked list. */ privatetransient Entry<K,V> header;
/** * The iteration ordering method for this linked hash map: <tt>true</tt> * for access-order, <tt>false</tt> for insertion-order. * * @serial */ privatefinalboolean accessOrder;
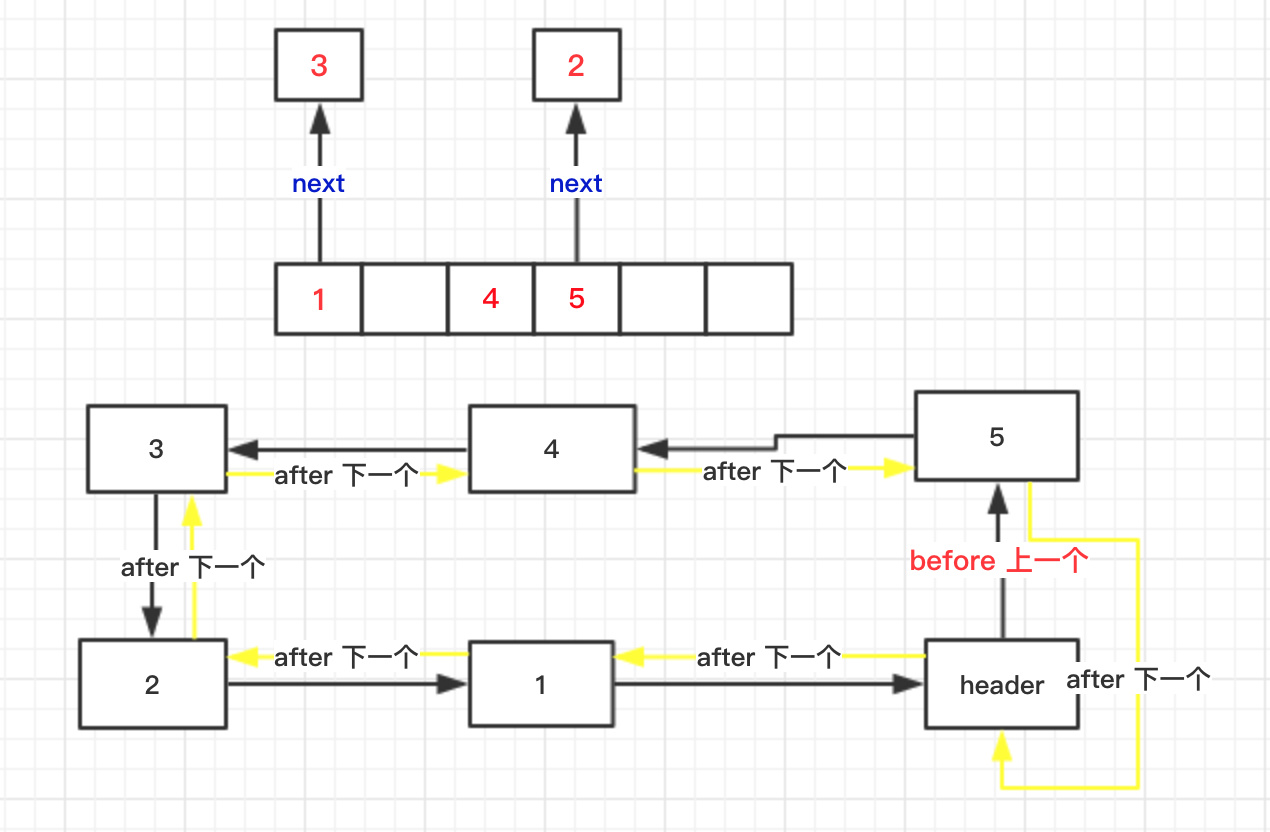
privatestaticclassEntry<K,V> extendsHashMap.Entry<K,V> { // These fields comprise the doubly linked list used for iteration. Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } }
public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) returnputForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; //空实现,交给 LinkedHashMap 自己实现 e.recordAccess(this); return oldValue; } }
// LinkedHashMap 对其重写 voidaddEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
createEntry(hash, key, value, bucketIndex); }
// LinkedHashMap 对其重写 voidcreateEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }