不改一行代码定位线上性能问题

背景
最近时运不佳,几乎天天被线上问题骚扰。前几天刚解决了一个 HashSet 的并发问题,周六又来了一个性能问题。
大致的现象是:
我们提供出去的一个 OpenAPI 反应时快时慢,快的时候几十毫秒,慢的时候几秒钟才响应。
尝试解决
由于这种也不是业务问题,不能直接定位。所以尝试在测试环境复现,但遗憾的测试环境贼快。
没办法只能硬着头皮上了。
中途有抱着侥幸心里让运维查看了 Nginx 里 OpenAPI 的响应时间,想把锅扔给网络。结果果然打脸了;Nginx 里的日志也表明确实响应时间确实有问题。
为了清晰的了解这个问题,我简单梳理了这个调用过程。

整个的流程算是比较常见的分层架构:
- 客户端请求到
Nginx。 Nginx负载了后端的web服务。web服务通过RPC调用后端的Service服务。
日志大法
我们首先想到的是打日志,在可能会慢的方法或接口处记录处理时间来判断哪里有问题。
但通过刚才的调用链来说,这个请求流程不短。加日志涉及的改动较多而且万一加漏了还有可能定位不到问题。
再一个是改动代码之后还会涉及到发版上线。
工具分析
所以最好的方式就是不改动一行代码把这个问题分析出来。
这时就需要一个 agent 工具了。我们选用了阿里以前开源的 Tprofile 来使用。
只需要在启动参数中加入 -javaagent:/xx/tprofiler.jar 即可监控你想要监控的方法耗时,并且可以给你输出报告,非常方便。对代码没有任何侵入性同时性能影响也较小。
工具使用
下面来简单展示下如何使用这个工具。
首先第一步自然是 clone 源码然后打包,可以克隆我修改过的源码。
因为这个项目阿里多年没有维护了,还残留一些
bug,我在它原有的基础上修复了个影响使用的bug,同时做了一些优化。
执行以下脚本即可。
1 | |
到这里之后会在项目的 TProfiler/pkg/TProfiler/lib/tprofiler-1.0.1.jar 中生成好我们要使用的 jar 包。
接下来只需要将这个 jar 包配置到启动参数中,同时再配置一个配置文件路径即可。
这个配置文件我 copy 官方的解释。
1 | |
最终的启动参数如下:
1 | |
为了模拟排查接口响应慢的问题,我用 cicada 实现了一个 HTTP 接口。其中调用了两个耗时方法:
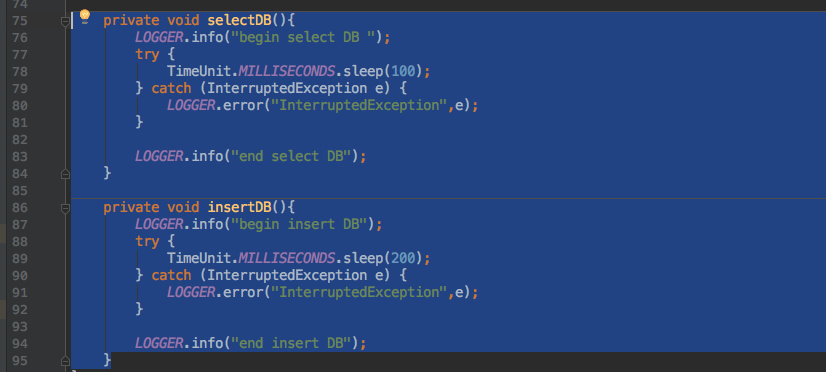
这样当我启动应用时,Tprofile 就会在我配置的目录记录它所收集的方法信息。
我访问接口 http://127.0.0.1:5688/cicada-example/demoAction?name=test&id=10 几次后它就会把每个方法的明细响应写入 tprofile.log。
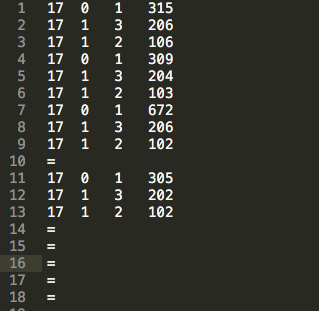
由左到右每列分别代表为:
线程ID、方法栈深度、方法编号、耗时(毫秒)。
但 tmethod.log 还是空的;
这时我们只需要执行这个命令即可把最新的方法采样信息刷到 tmethod.log 文件中。
1 | |
其实就是访问了 Tprofile 暴露出的一个服务,他会读取、解析 tprofile.log 同时写入 tmethod.log.
其中的端口就是配置文件中的 port。
再打开 tmethod.log :
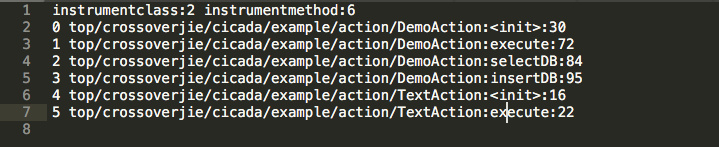
其中会记录方法的信息。
- 第一行数字为方法的编号。可以通过这个编号去
tprofile.log(明细)中查询每次的耗时情况。 - 行末的数字则是这个方法在源码中最后一行的行号。
其实大部分的性能分析都是统计某个方法的平均耗时。
所以还需要执行下面的命令,通过 tmethod.log tprofile.log 来生成每个方法的平均耗时。
1 | |
打开 topmethod.log 就是所有方法的平均耗时。

- 4 为请求次数。
- 205 为平均耗时。
- 818 则为总耗时。
和实际情况是相符的。
方法的明细耗时
这是可能还会有其他需求;比如说我想查询某个方法所有的明细耗时怎么办呢?
官方没有提供,但也是可以的,只是要麻烦一点。
比如我想查看 selectDB() 的耗时明细:
首先得知道这个方法的编号,在 tmethod.log 中可以看查到。
1 | |
编号为 2.
之前我们就知道 tprofile.log 记录的是明细,所以通过下面的命令即可查看。
1 | |
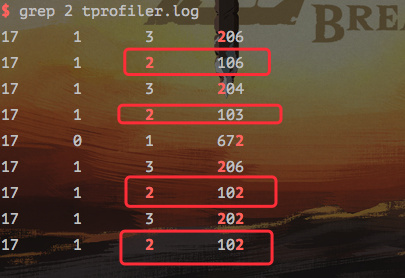
通过第三列方法编号为 2 的来查看每次执行的明细。
但这样的方式显然不够友好,需要人为来过滤干扰,步骤也多;所以我也准备加上这样一个功能。
只需要传入一个方法名称即可查询采集到的所有方法耗时明细。
总结
回到之前的问题;线上通过这个工具分析我们得到了如下结果。
- 有些方法确实执行时快时慢,但都是和数据库相关的。由于目前数据库压力较大,准备在接下来进行冷热数据分离,以及分库分表。
- 在第一步操作还没实施之前将部分写数据库的操作改为异步,减小响应时间。
- 考虑接入
pinpoint这样的APM工具。
类似于 Tprofile 的工具确实挺多的,找到适合自己的就好。
在还没有使用类似于 pinpoint 这样的分布式跟踪工具之前应该会大量依赖于这个工具,所以后续说不定也会做一些定制,比如增加一些可视化界面等,可以提高排查效率。
你的点赞与分享是对我最大的支持