『并发包入坑指北』之向大佬汇报任务

前言
在面试过程中聊到并发相关的内容时,不少面试官都喜欢问这类问题:
当 N 个线程同时完成某项任务时,如何知道他们都已经执行完毕了。
这也是本次讨论的话题之一,所以本篇为『并发包入坑指北』的第二篇;来聊聊常见的并发工具。
自己实现
其实这类问题的核心论点都是:如何在一个线程中得知其他线程是否执行完毕。
假设现在有 3 个线程在运行,需要在主线程中得知他们的运行结果;可以分为以下几步:
- 定义一个计数器为 3。
- 每个线程完成任务后计数减一。
- 一旦计数器减为 0 则通知等待的线程。
所以也很容易想到可以利用等待通知机制来实现,和上文的『并发包入坑指北』之阻塞队列的类似。
按照这个思路自定义了一个 MultipleThreadCountDownKit 工具,构造函数如下:
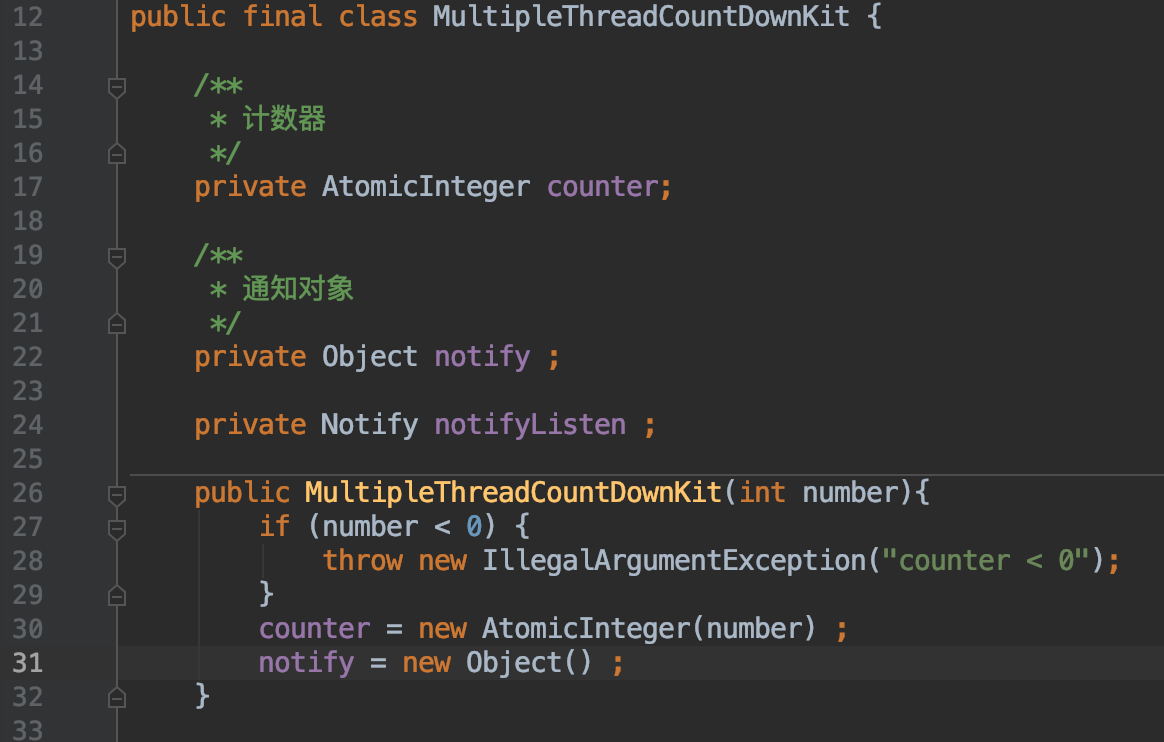
考虑到并发的前提,这个计数器自然需要保证线程安全,所以采用了 AtomicInteger。
所以在初始化时需要根据线程数量来构建对象。
计数器减一
当其中一个业务线程完成后需要将这个计数器减一,直到减为0为止。
1 | |
利用 counter.decrementAndGet() 来保证多线程的原子性,当减为 0 时则利用等待通知机制来 notify 其他线程。
等待所有线程完成
而需要知道业务线程执行完毕的其他线程则需要在未完成之前一直处于等待状态,直到上文提到的在计数器变为 0 时得到通知。
1 | |
原理也很简单,一旦计数器还存在时则会利用 notify 对象进行等待,直到被业务线程唤醒。
同时这里新增了一个通知接口可以自定义实现唤醒后的一些业务逻辑,后文会做演示。
并发测试
主要就是这两个函数,下面来做一个演示。
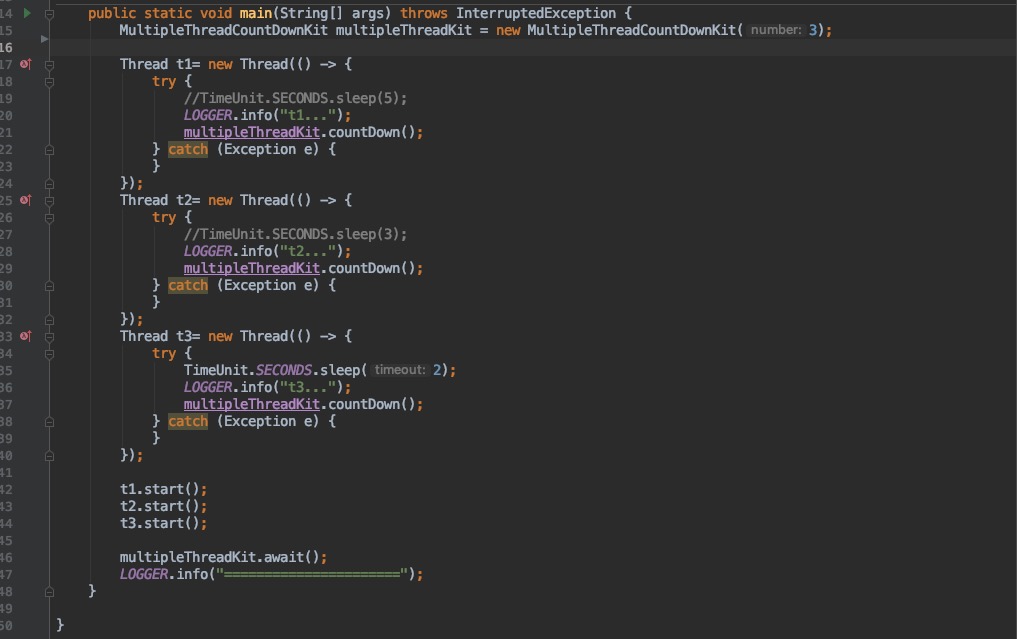
- 初始化了三个计数器的并发工具
MultipleThreadCountDownKit - 创建了三个线程分别执行业务逻辑,完毕后执行
countDown()。 - 线程 3 休眠了 2s 用于模拟业务耗时。
- 主线程执行
await()等待他们三个线程执行完毕。

通过执行结果可以看出主线程会等待最后一个线程完成后才会退出;从而达到了主线程等待其余线程的效果。
1 | |
也可以在初始化的时候指定一个回调接口,用于接收业务线程执行完毕后的通知。

当然和在主线程中执行这段逻辑效果是一样的(和执行 await() 方法处于同一个线程)。
CountDownLatch
当然我们自己实现的代码没有经过大量生产环境的验证,所以主要的目的还是尝试窥探官方的实现原理。
所以我们现在来看看 juc 下的 CountDownLatch 是如何实现的。
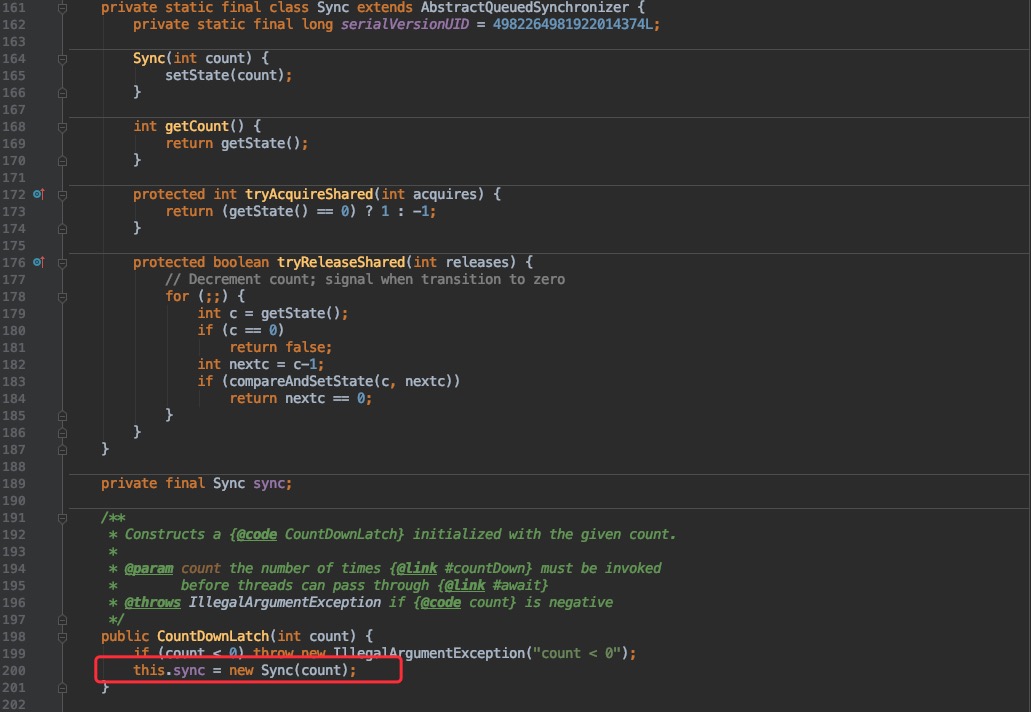
通过构造函数会发现有一个 内部类 Sync,他是继承于 AbstractQueuedSynchronizer ;这是 Java 并发包中的基础框架,都可以单独拿来讲了,所以这次重点不是它,今后我们再着重介绍。
这里就可以把他简单理解为提供了和上文类似的一个计数器及线程通知工具就行了。
countDown
其实他的核心逻辑和我们自己实现的区别不大。
1 | |
利用这个内部类的 releaseShared 方法,我们可以理解为他想要将计数器减一。

看到这里有没有似曾相识的感觉。

没错,在 JDK1.7 中的 AtomicInteger 自减就是这样实现的(利用 CAS 保证了线程安全)。
只是一旦计数器减为 0 时则会执行 doReleaseShared 唤醒其他的线程。
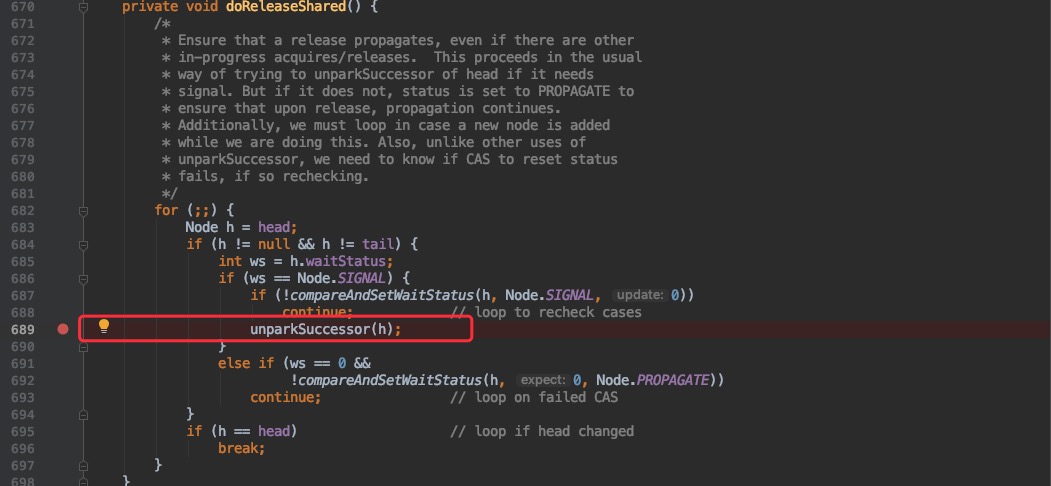
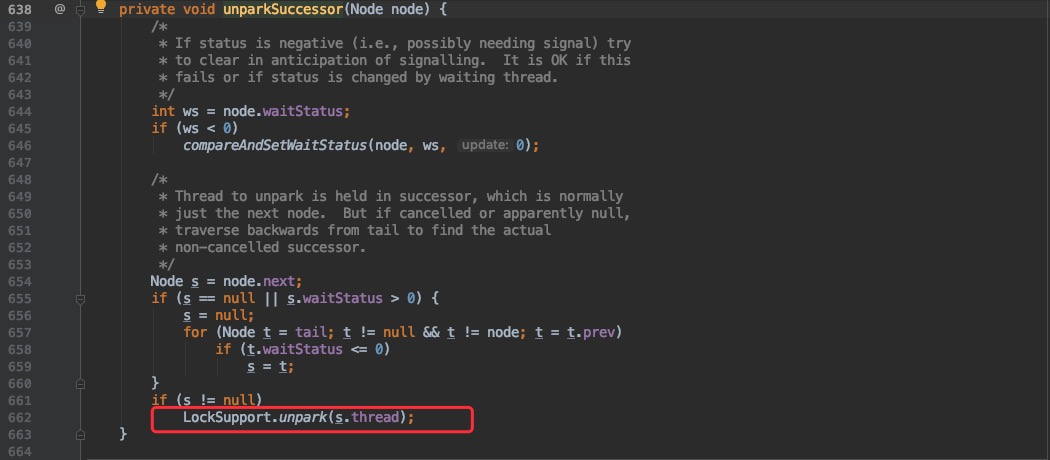
这里我们只需要关心红框部分(其他的暂时不用关心,这里涉及到了 AQS 中的队列相关),最终会调用 LockSupport.unpark 来唤醒线程;就相当于上文调用 object.notify()。
所以其实本质上还是相同的。
await
其中的 await() 也是借用 Sync 对象的方法实现的。
1 | |
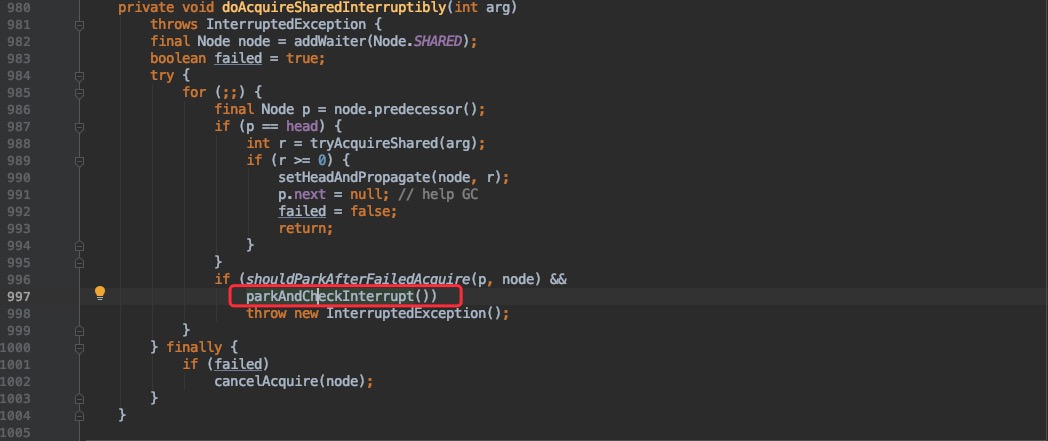
一旦还存在未完成的线程时,则会调用 doAcquireSharedInterruptibly 进入阻塞状态。
1 | |
同样的由于这也是 AQS 中的方法,我们只需要关心红框部分;其实最终就是调用了 LockSupport.park 方法,也就相当于执行了 object.wait() 。
- 所有的业务线程执行完毕后会在计数器减为 0 时调用
LockSupport.unpark来唤醒线程。 - 等待线程一旦计数器 > 0 时则会利用
LockSupport.park来等待唤醒。
这样整个流程也就串起来了,它的使用方法也和上文的类似。
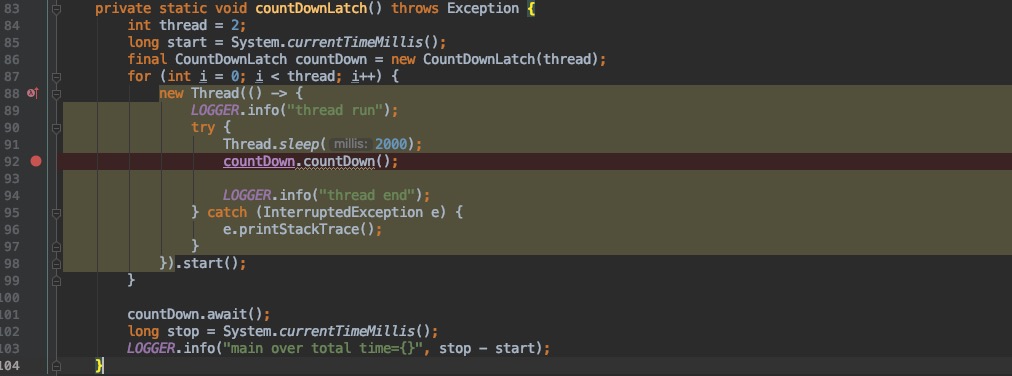
就不做过多介绍了。
实际案例
同样的来看一个实际案例。
在上一篇《一次分表踩坑实践的探讨》提到了对于全表扫描的情况下,需要利用多线程来提高查询效率。
比如我们这里分为了 64 张表,计划利用 8 个线程来分别处理这些表的数据,伪代码如下:
1 | |
这样就可以实现所有数据都查询完毕后再做统一汇总;代码挺简单,也好理解(当然也可以使用线程池的 API)。
总结
CountDownLatch 算是 juc 中一个高频使用的工具,学会和理解他的使用会帮助我们更容易编写并发应用。
文中涉及到的源码:
你的点赞与分享是对我最大的支持