Pulsar负载均衡原理及优化

前言
前段时间我们在升级 Pulsar 版本的时候发现升级后最后一个节点始终没有流量。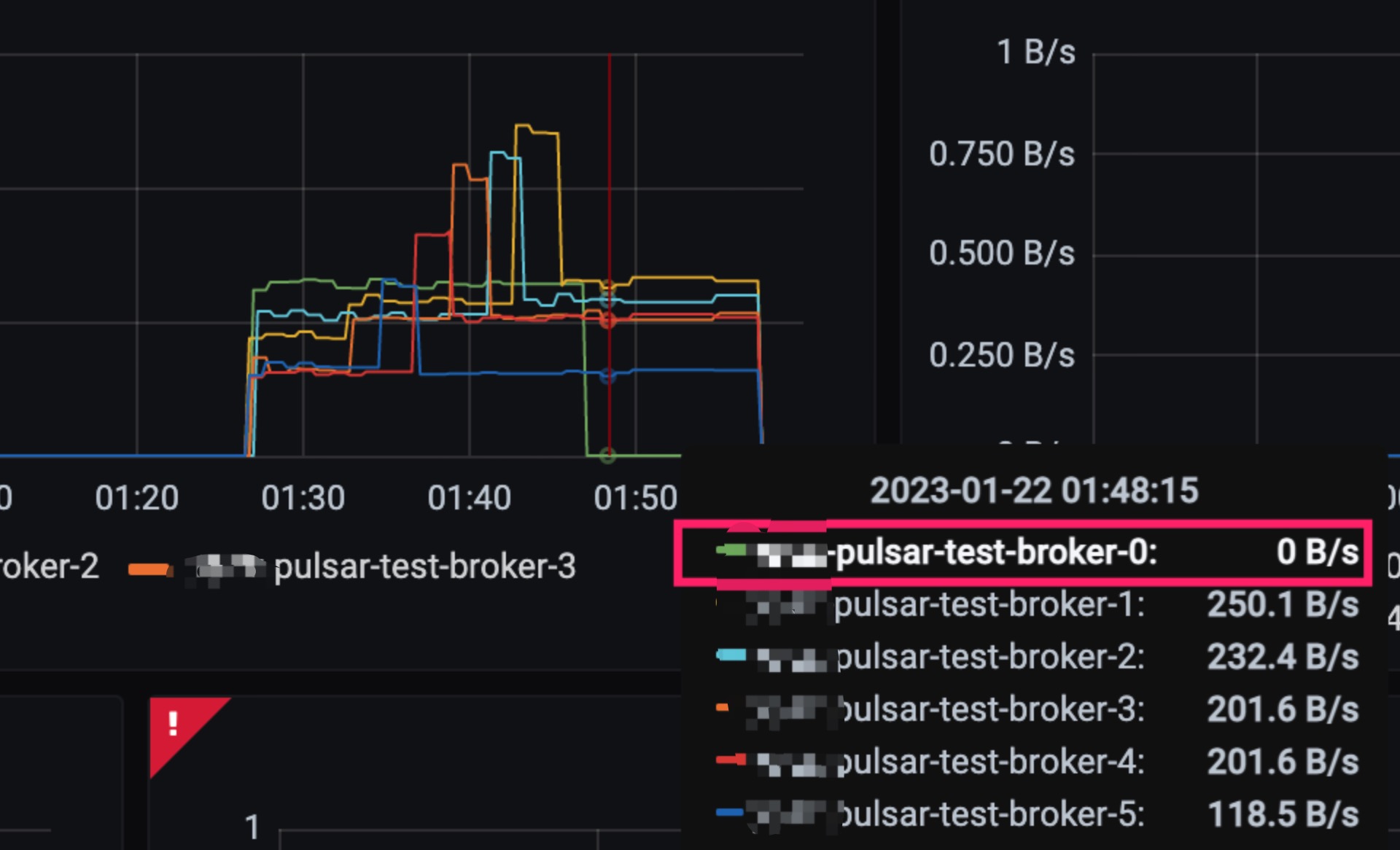
虽然对业务使用没有任何影响,但负载不均会导致资源的浪费。
和同事沟通后得知之前的升级也会出现这样的情况,最终还是人工调用 Pulsar 的 admin API 完成的负载均衡。
这个问题我尝试在 Google 和 Pulsar 社区都没有找到类似的,不知道是大家都没碰到还是很少升级集群。
我之前所在的公司就是一个版本走到黑😂
Pulsar 负载均衡原理
当一个集群可以水平扩展后负载均衡就显得非常重要,根本目的是为了让每个提供服务的节点都能均匀的处理请求,不然扩容就没有意义了。
在分析这个问题的原因之前我们先看看 Pulsar 负载均衡的实现方案。
1 | |
我们可以通过这个 broker 的这个配置来控制负载均衡器的开关,默认是打开。
但具体使用哪个实现类来作为负载均衡器也可以在配置文件中指定:
1 | |
默认使用的是 ModularLoadManagerImpl。
1 | |
当 broker 启动时会从配置文件中读取配置进行加载,如果加载失败会使用 SimpleLoadManagerImpl 作为兜底策略。
当 broker 是一个集群时,只有 leader 节点的 broker 才会执行负载均衡器的逻辑。
Leader 选举是通过 Zookeeper 实现的。
默然情况下成为 Leader 节点的 broker 会每分钟读取各个 broker 的数据来判断是否有节点负载过高需要做重平衡。
而是否重平衡的判断依据是由 org.apache.pulsar.broker.loadbalance.LoadSheddingStrategy 接口提供的,它其实只有一个函数:
1 | |
根据所有 broker 的负载信息计算出一个需要被 unload 的 broker 以及 bundle。
这里解释下 unload 和 bundle 的概念:
bundle是一批topic的抽象,将bundle和broker进行关联后客户端才能知道应当连接哪个 broker;而不是直接将 topic 与broker绑定,这样才能实现海量 topic 的管理。- unload 则是将已经与 broker 绑定的 bundle 手动解绑,从而触发负载均衡器选择一台合适的 broker 重新进行绑定;通常是整个集群负载不均的时候触发。
ThresholdShedder 原理
LoadSheddingStrategy 接口目前有三个实现,这里以官方默认的 ThresholdShedder 为例: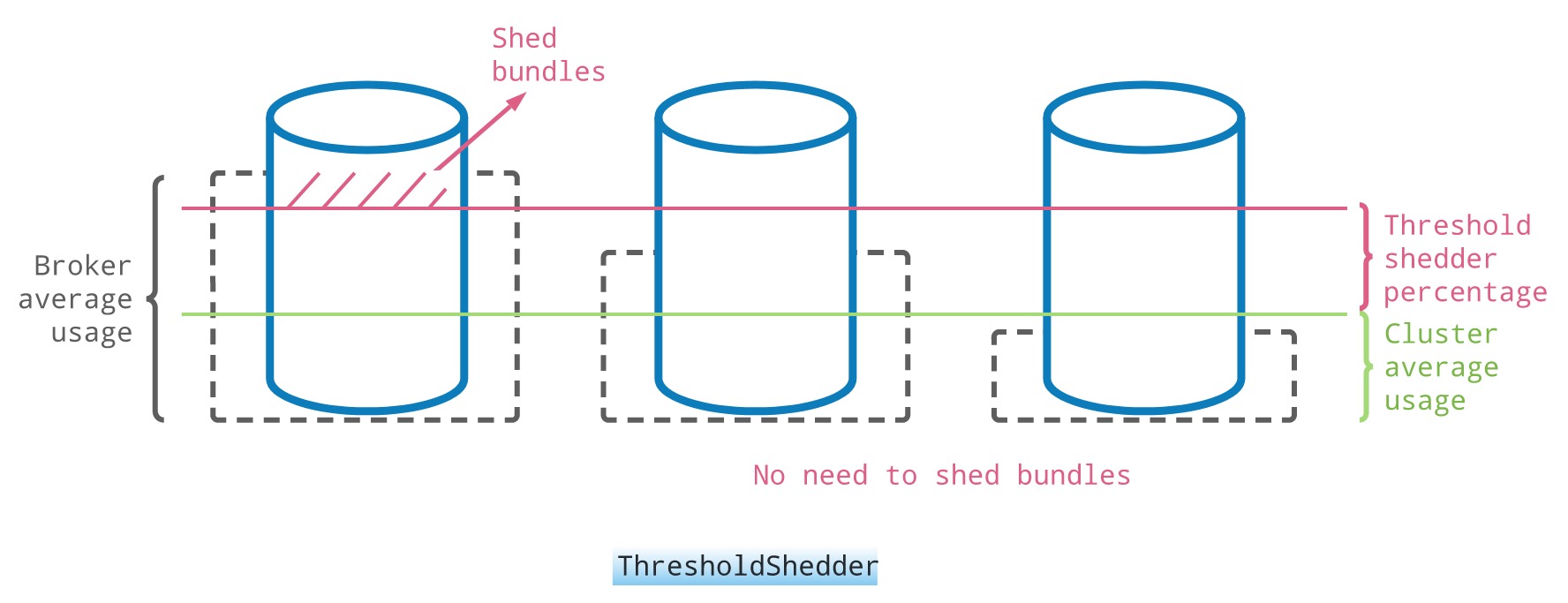
它的实现算法是根据带宽、内存、流量等各个指标的权重算出每个节点的负载值,之后为整个集群计算出一个平均负载值。
1 | |
当集群中有某个节点的负载值超过平均负载值达到一定程度(可配置的阈值)时,就会触发 unload,以上图为例就会将最左边节点中红色部分的 bundle 卸载掉,然后再重新计算一个合适的 broker 进行绑定。
阈值存在的目的是为了避免频繁的 unload,从而影响客户端的连接。
问题原因
当某些 topic 的流量突然爆增的时候这种负载策略确实可以处理的很好,但在我们集群升级的情况就不一定了。
假设我这里有三个节点:
- broker0
- broker1
- broker2
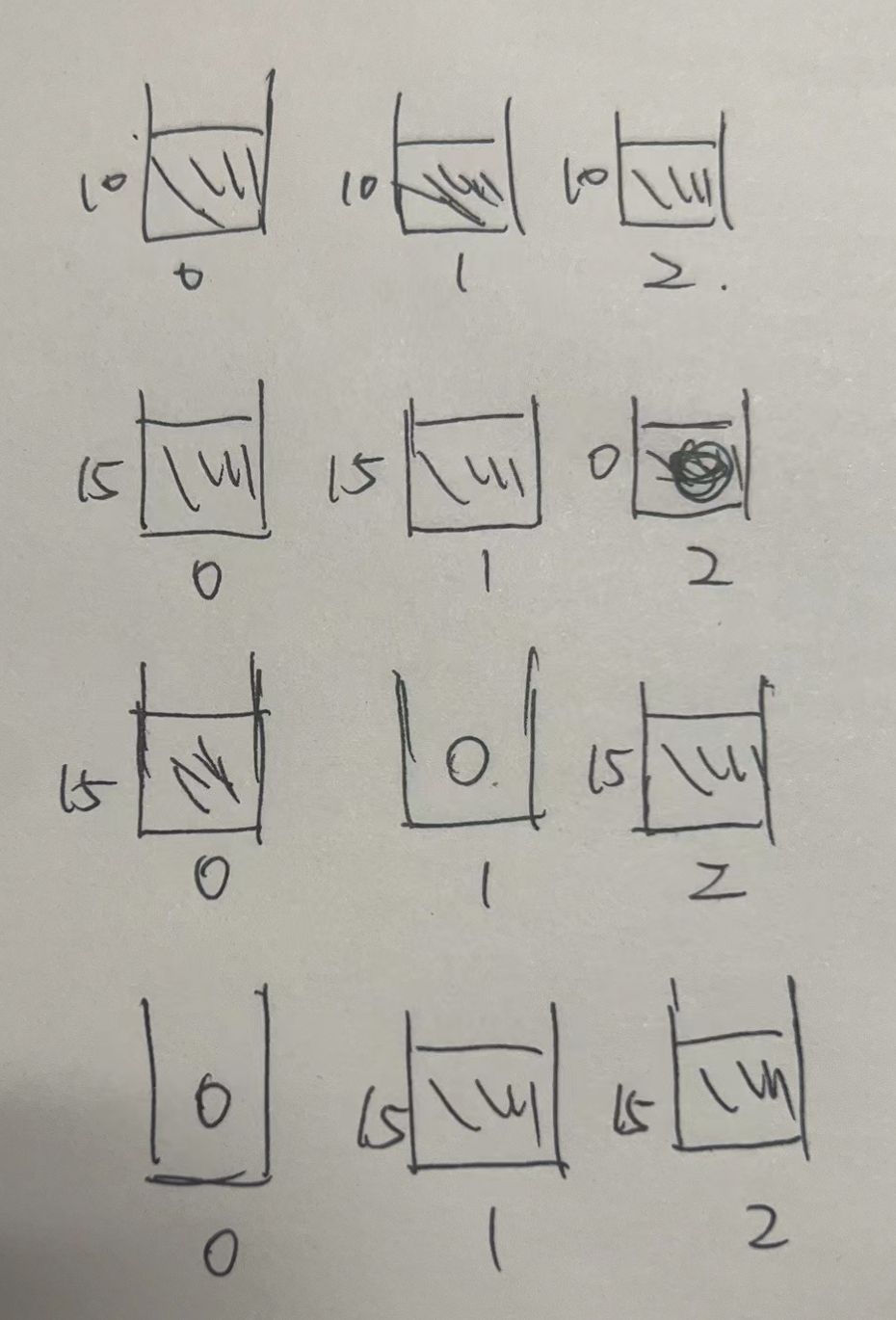
集群升级时会从 broker2->0 进行镜像替换重启,假设在升级前每个 broker 的负载值都是 10。
- 重启 broker2 时,它所绑定的 bundle 被 broker0/1 接管。
- 升级 broker1 时,它所绑定的 bundle 又被 broker0/2 接管。
- 最后升级 broker0, 它所绑定的 bundle 会被broker1/2 接管。
只要在这之后没有发生流量激增到触发负载的阈值,那么当前的负载情况就会一直保留下去,也就是 broker0 会一直没有流量。
经过我反复测试,现象也确实如此。
1 | |
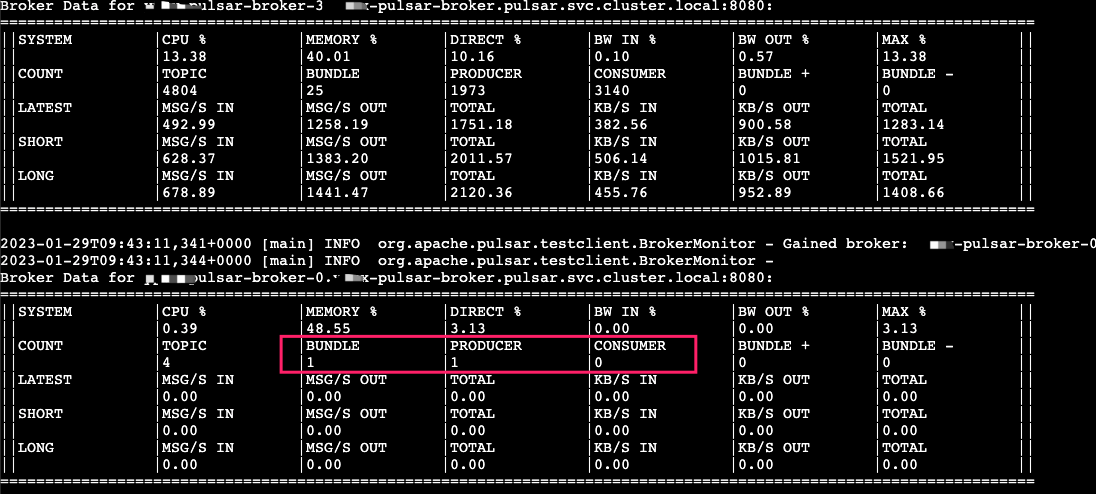
通过这个工具也可以查看各个节点的负载情况
优化方案
这种场景是当前 ThresholdShedder 所没有考虑到的,于是我在我们所使用的版本 2.10.3 的基础上做了简单的优化: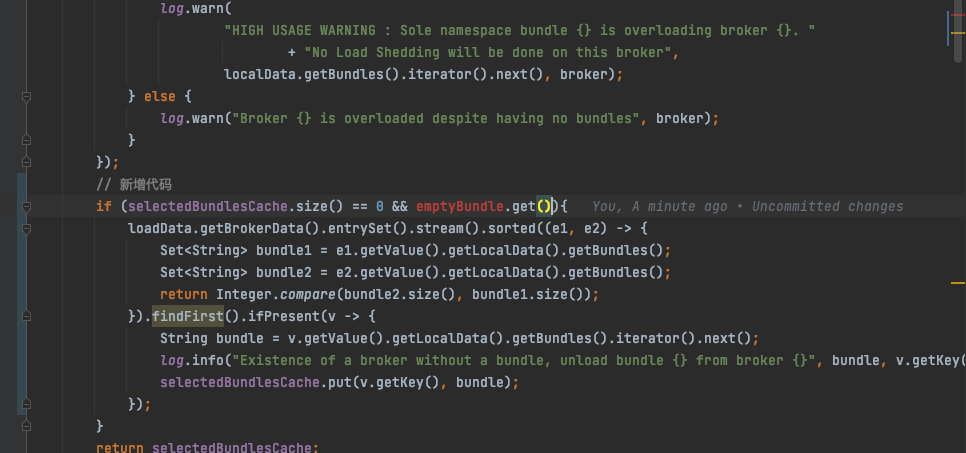
- 当原有逻辑走完之后也没有获取需要需要卸载的 bundle,同时也存在一个负载极低的 broker 时(
emptyBundle),再触发一次 bundle 查询。 - 按照 broker 所绑定的数量排序,选择一个数量最多的 broker 的 第一个 bundle 进行卸载。
修改后打包发布,再走一遍升级流程后整个集群负载就是均衡的了。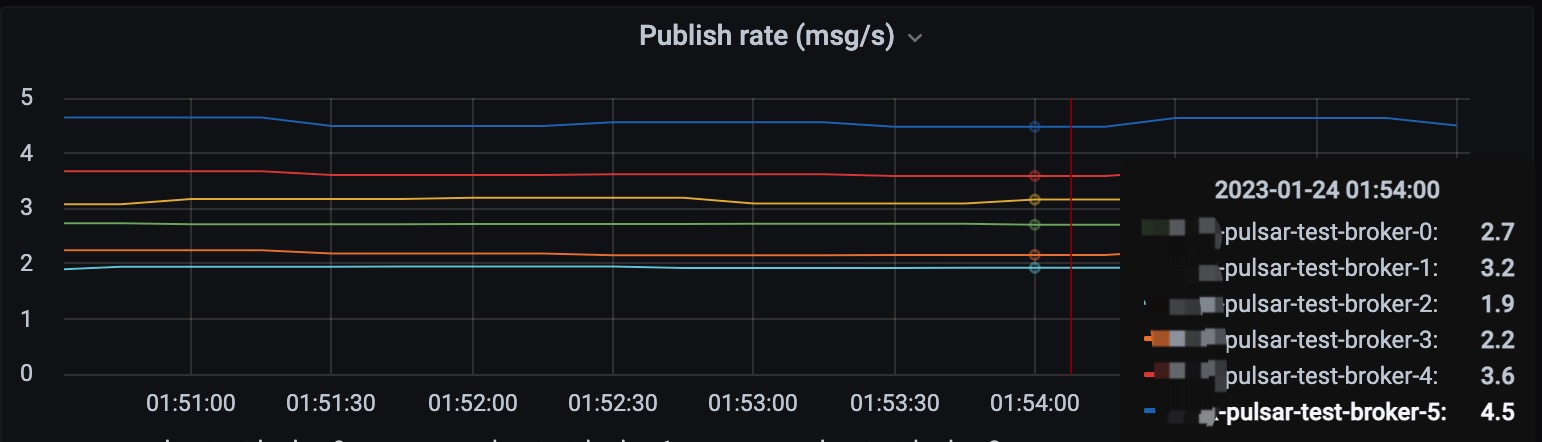
但其实这个方案并不严谨,第二步选择的重点是筛选出负载最高的集群中负载最高的 bundle;这里只是简单的根据数量来判断,并不够准确。
正当我准备持续优化时,鬼使神差的我想看看 master 上有人修复这个问题没,结果一看还真有人修复了;只是还没正式发版。
https://github.com/apache/pulsar/pull/17456
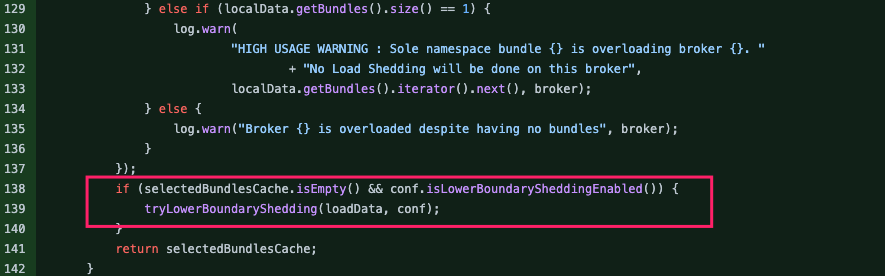
整体思路是类似的,只是筛选负载需要卸载 bundle 时是根据 bundle 自身的流量来的,这样会更加精准。
总结
不过看社区的进度等这个优化最终能用还不知道得多久,于是我们就自己参考这个思路在管理台做了类似的功能,当升级后出现负载不均衡时人工触发一个逻辑:
- 系统根据各个节点的负载情况计算出一个负载最高的节点和 bundle 在页面上展示。
- 人工二次确认是否要卸载,确认无误后进行卸载。
本质上只是将上述优化的自动负载流程改为人工处理了,经过测试效果是一样的。
Pulsar 整个项目其实非常庞大,有着几十上百个模块,哪怕每次我只改动一行代码准备发布测试时都得经过漫长的编译+ Docker镜像打包+上传私服这些流程,通常需要1~2个小时;但总的来说收获还是很大的,最近也在提一些 issue 和 PR,希望后面能更深入的参与进社区。