请注意,你的 Pulsar 集群可能有删除数据的风险
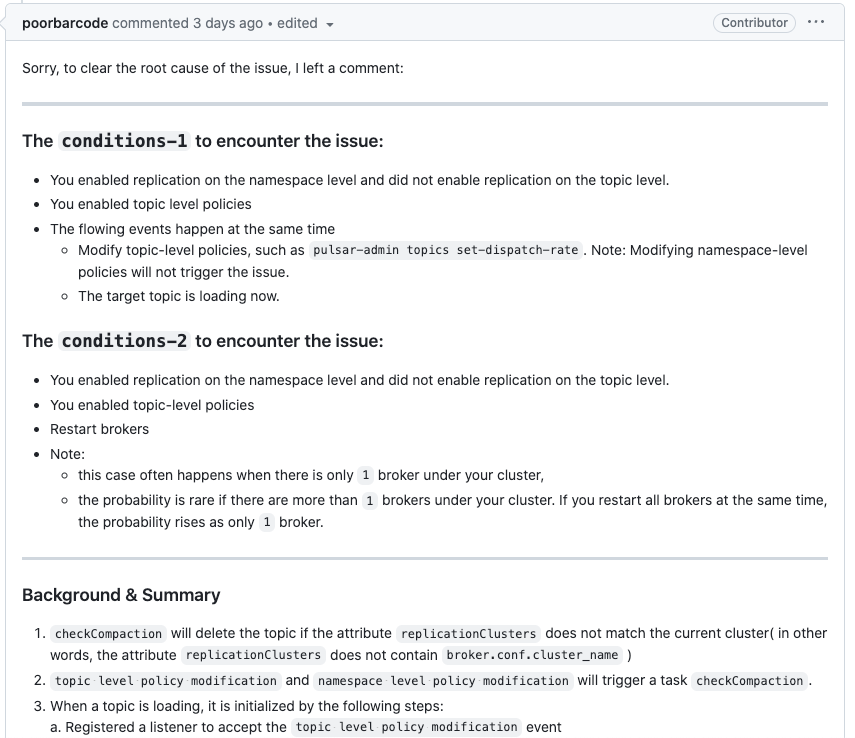
在上一篇 Pulsar3.0新功能介绍中提到,在升级到 3.0 的过程中碰到一个致命的问题,就是升级之后 topic 被删除了。
正好最近社区也补充了相关细节,本次也接着这个机会再次复盘一下,毕竟这是一个非常致命的 Bug。
现象
先来回顾下当时的情况:升级当晚没有出现啥问题,各个流量指标、生产者、消费者数量都是在正常范围内波动。
事后才知道,因为只是删除了很少一部分的 topic,所以从监控中反应不出来。
早上上班后陆续有部分业务反馈应用连不上 topic,提示 topic nof found.
1 | |
因为只是部分应用在反馈,所以起初怀疑是 broker 升级之后导致老版本的 pulsar-client 存在兼容性问题。
所以我就拿了平时测试用的 topic 再配合多个老版本的 sdk 进行测试,发现没有问题。
直到这一步还好,至少证明是小范故障。
因为提示的是 topic 不存在,所以就准备查一下 topic 的元数据是否正常。
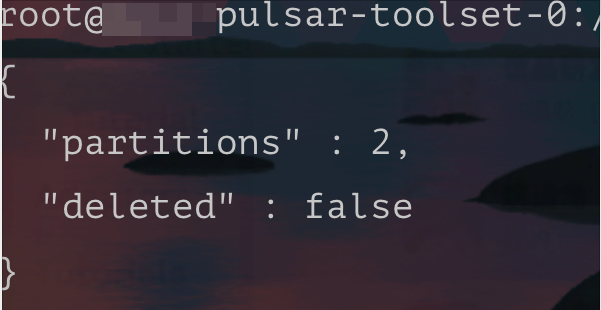
查询后发现元数据是存在的。
之后我便想看看提示了 topic 不存在的 topic 的归属,然后再看看那个 broker 中是否有异常日志。

发现查看归属的接口也是提示 topic 不存在,此时我便怀疑是 topic 的负载出现了问题,导致这些 topic 没有绑定到具体的 broker。
于是便重启了 broker,结果依然没有解决问题。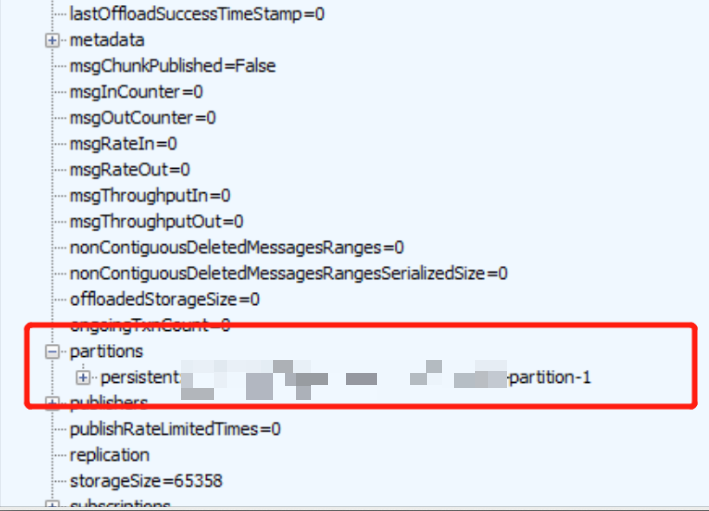
之后我们查询了 topic 的 internal state 发现元数据中会少一个分区。
紧急恢复
我们尝试将这个分区数恢复后,发现这个 topic 就可以正常连接了。
于是再挑选了几个异常的 topic 发现都是同样的问题,恢复分区数之后也可以正常连接了。
所以我写了一个工具遍历了所有的 topic,检测分区数是否正常,不正常时便修复。
1 | |
排查
修复好所有 topic 之后便开始排查根因,因为看到的是元数据不一致所以怀疑是 zk 里的数据和 broker 内存中的数据不同导致的这个问题。
但我们查看了 zookeeper 中的数据发现一切又是正常的,所以只能转变思路。
之后我们通过有问题的 topic 在日志中找到了一个关键日志:
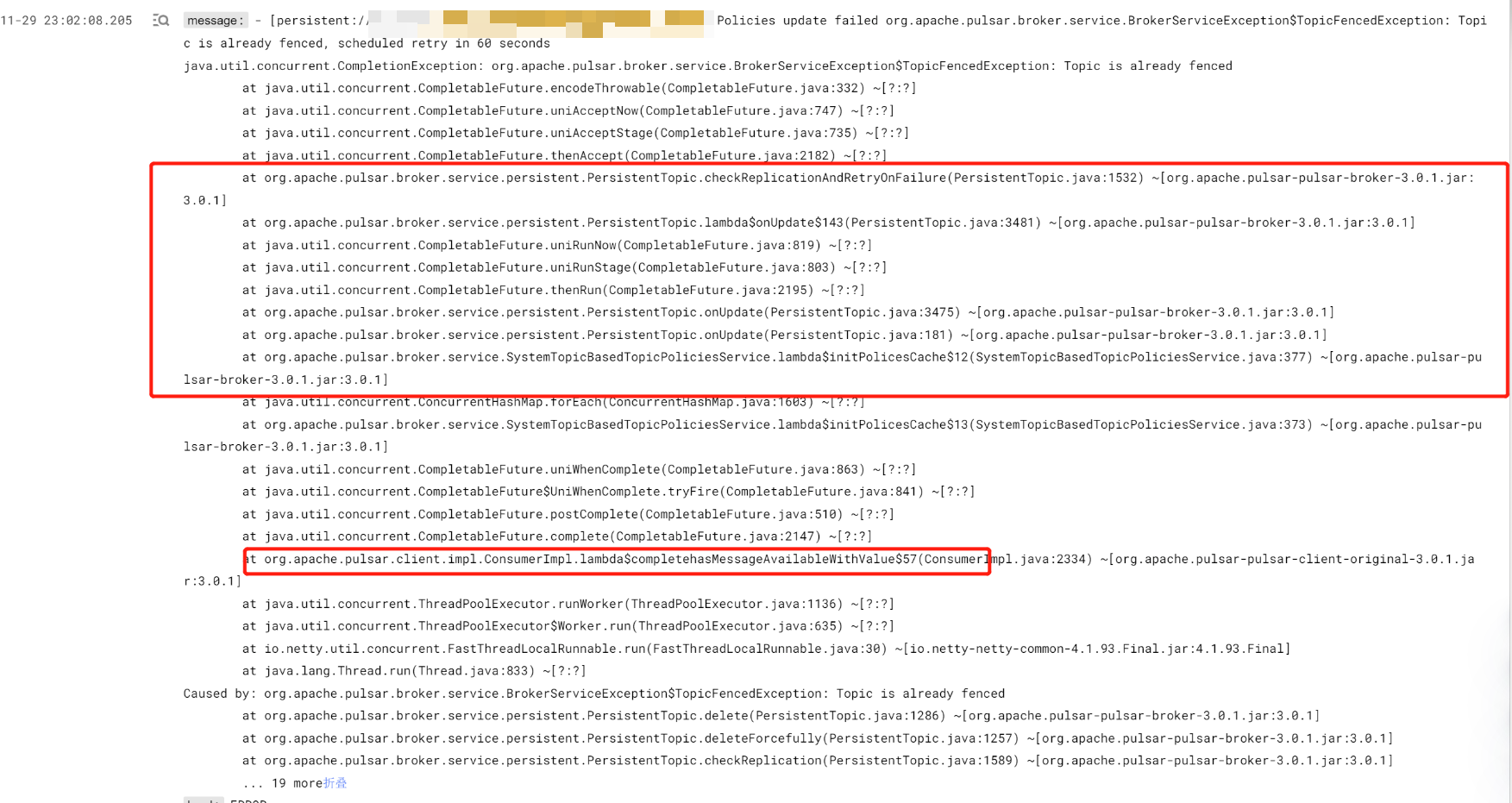
以及具体的堆栈。
此时具体的原因已经很明显了,元数据这些自然是没问题;根本原因是 topic 被删除了,但被删除的 topic 只是某个分区,所以我们在查询 internalState 时才发发现少一个 topic。
通过这个删除日志定位到具体的删除代码:
1 | |
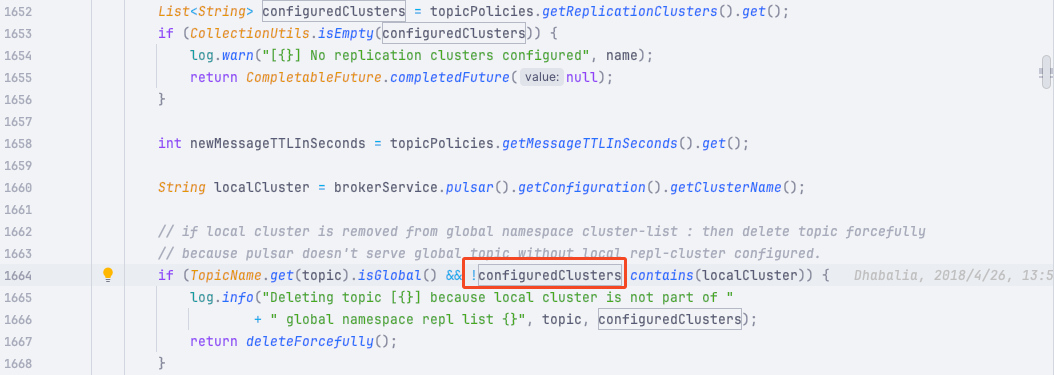
原来是这里的 configuredClusters 值为空才导致的 topic 调用了 deleteForcefully()被删除。
而这个值是从 topic 的 Policy 中获取的。
复现问题
通过上图中的堆栈跟踪,怀疑是重启 broker 导致的 topic unload ,同时 broker 又在构建 topic 导致了对 topicPolicy 的读写。
最终导致 topicPolicy 为空。
只要写个单测可以复现这个问题就好办了:
1 | |
同时还得查询元数据有耗时才能复现: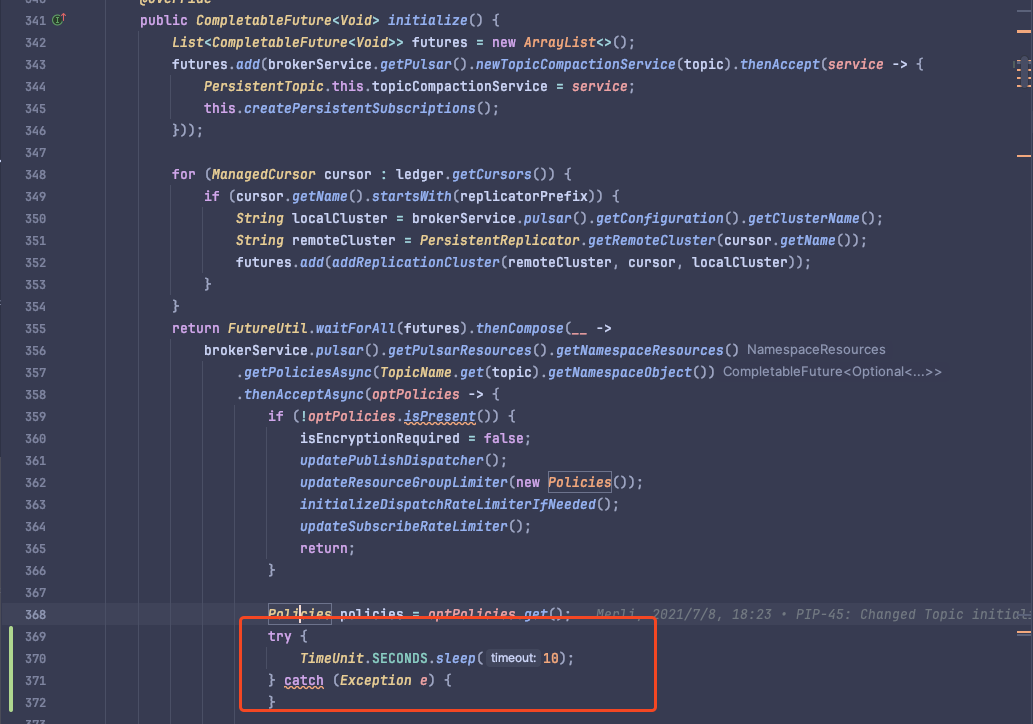
只能手动 sleep 模拟这个耗时
具体也可以参考这个 issue
https://github.com/apache/pulsar/issues/21653#issuecomment-1842962452
此时就会发现有 topic 被删除了,而且是随机删除的,因为出现并发的几率本身也是随机的。
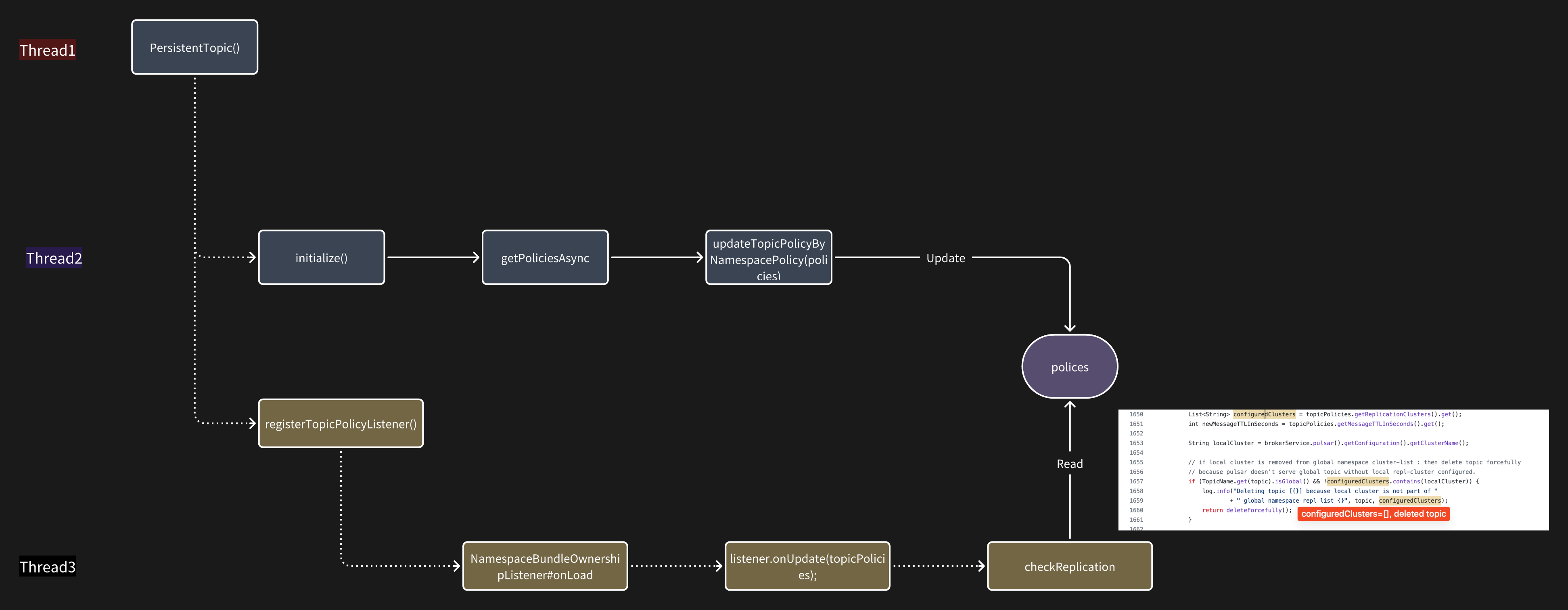
这里画了一个流程图就比较清晰了,在 broker 重启的时候会有两个线程同时topicPolicy 进行操作。
在 thread3 读取 topicPolicy 进行判断时,thread2 可能还没有把数据准备好,所以就导致了 topic 被删除。
修复
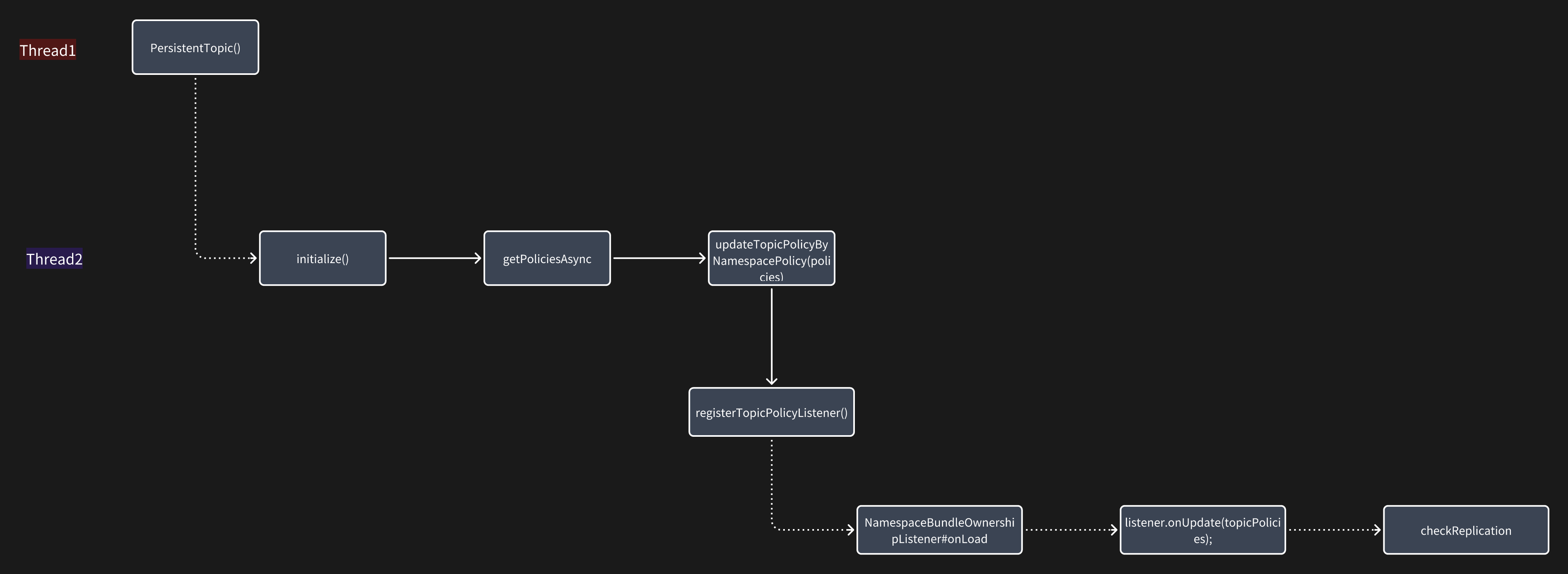
既然知道了问题原因就好修复了,我们只需要把 thread3 和 thread2 修改为串行执行就好了。
这也是处理并发最简单高效的方法,就是直接避免并发;加锁、队列啥的虽然也可以解决,但代码复杂度也高了很多,所以能不并发就尽量不要并发。
但要把这个修复推送到社区上游主分支最好是要加上单测,这样即便是后续有其他的改动也能保证这个 bug 不会再次出现。
之后在社区大佬的帮助下完善了单测,最终合并了这个修复。
再次证明写单测往往比代码更复杂,也更花费时间。
PR:https://github.com/apache/pulsar/pull/21704
使用修复镜像
因为社区合并代码再发版的周期较长,而我们又急于修复该问题;不然都不敢重启 broker,因为每重启一次都可能会导致不知道哪个 topic 就被删除了。
所以我们自己在本地构建了一个修复的镜像,准备在线上进行替换。
此时坑又来了,我们满怀信心的替换了一个镜像再观察日志发现居然还有删除的日志😱。
冷静下来一分析,原来是当前替换进行的 broker 没有问题了,但它处理的 topic 被转移到了其他 broker 中,而其他的 broker 并没有替换为我们最新的镜像。
所以导致 topic 在其他 broker 中依然被删除了。
除非我们停机,将所有的镜像都替换之后再一起重启。
但这样的成本太高了,最好是可以平滑发布。
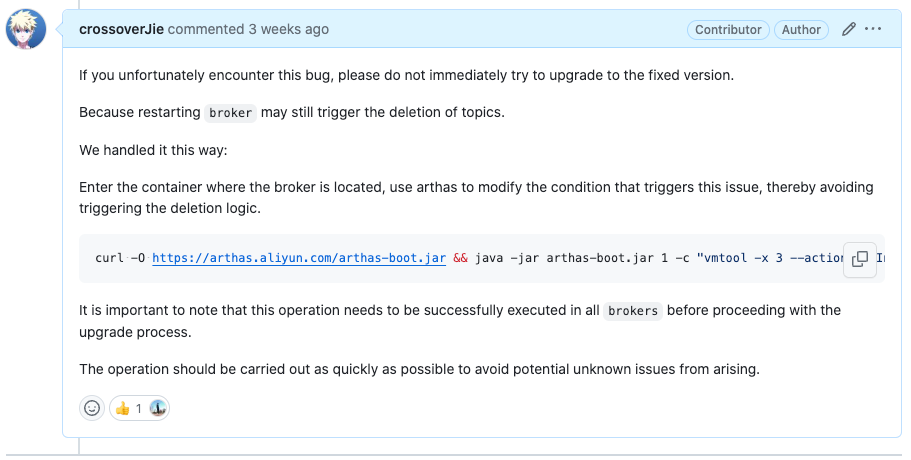
最终我们想到一个办法,使用 arthas 去关闭了一个 broker 的一个选项,之后就不会执行出现 bug 的那段代码了。
1 | |
我也将操作方法贴到了对于 issue 的评论区。
https://github.com/apache/pulsar/issues/21653#issuecomment-1857548997
如果不幸碰到了这个 bug,可以参考修复。
总结
删除的这些 topic 的同时它的订阅者也被删除了,所以我们还需要修复订阅者:
1 | |
之所以说这个 bug 非常致命,是因为这样会导致 topic 的数据丢失,同时这些 topic 上的数据也会被删除。
后续 https://github.com/apache/pulsar/pull/21704#issuecomment-1878315926社区也补充了一些场景。
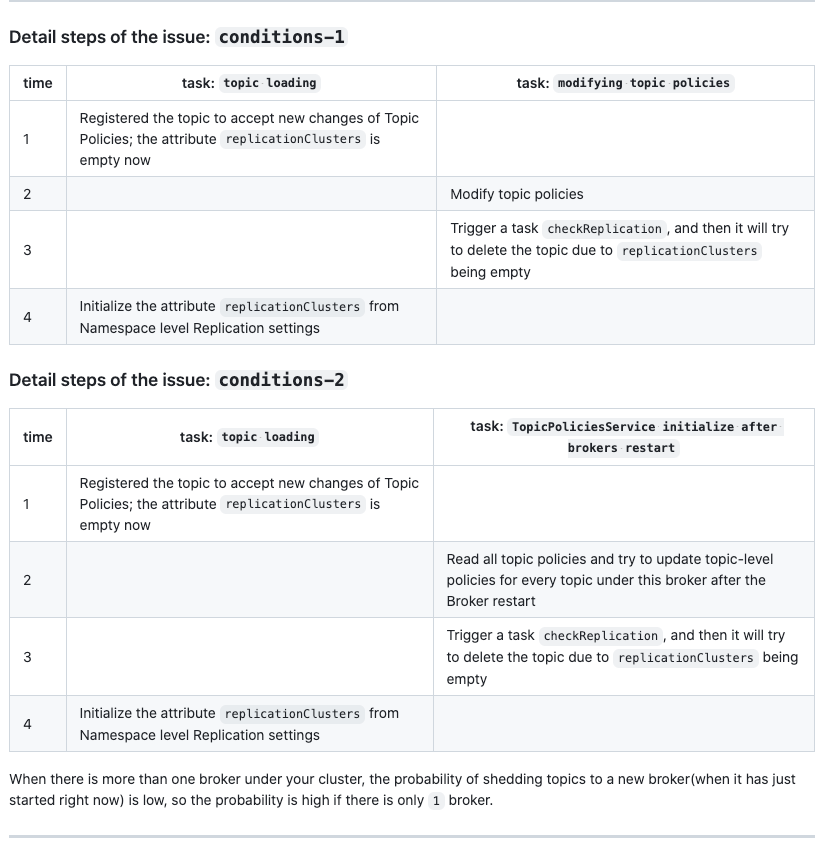
其实场景 2 更容易出现复现,毕竟更容易出现并发;也就是我们碰到的场景
说来也奇怪,结合社区的 issue 和其他大佬的反馈,这个问题只有我们碰到了,估计也是这个问题的触发条件也比较苛刻:
- 开启
systemTopic/topicLevelPolices
systemTopicEnabled: “true”
topicLevelPoliciesEnabled: “true” - 设置足够多的 topicPolicies
- 重启 broker
- 重启过程中从 zk 中获取数据出现耗时
符合以上条件的集群就需要注意了。
其实这个问题在这个 PR 就已经引入了
https://github.com/apache/pulsar/pull/11021
所以已经存在蛮久了,后续我们也将检测元数据作为升级流程之一了,确保升级后数据依然是完整的。
相关的 issue 和 PR:
https://github.com/apache/pulsar/issues/21653
https://github.com/apache/pulsar/pull/21704
#Blog #Pulsar