背景
因为公司内部在使用 PowerJob 作为我们的分布式调度系统,同时又是使用 OpenTelemetry 作为可观测的底座,但目前 OpenTelemetry 还没有对 PowerJob 提供支持,目前社区只对同类型的 XXL-JOB 有支持。

恰好公司内部也有一些开发同学有类似的需求:
于是在这个背景下我便开始着手开发 PowerJob 的 instrumentation,最终的效果如下:
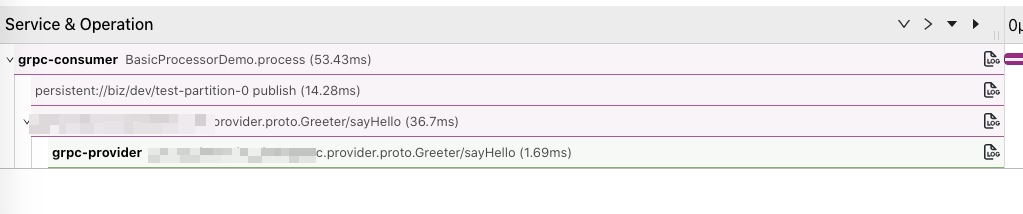
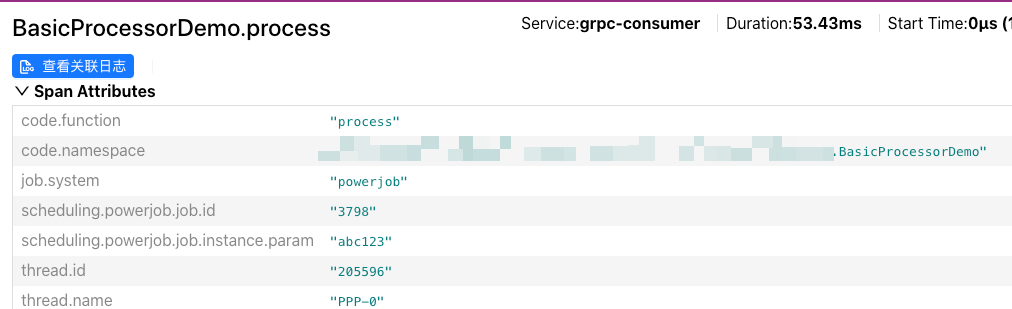
从这个链路图中可以看到 grpc-consumer 提供了调度的入口函数,然后在内部发送了 Pulsar 消息,最终又调用了 grpc-provider 的 gRPC 接口。
这样就可以把整个链路串起来,同时还能查看 PowerJob 调度的 JobId、以及调用参数等数据,这样排查问题时也更加直观。
开发 Instrumentation 的前置知识
在正式开发 Instrumentation 之前还需要了解一些前置知识点。

这里我们以现有的 gRPC 和我编写的 PowerJob instrumentation 为例,可以看到 gRPC 的 instrumentation 中多了一个 library 的模块。
这里就引申出了两种埋点方式:
- Library instrumentation
- Java agent instrumentation
通常我们对一个框架或者一个库进行埋点时,首先需要找到它的埋点入口。
以 grpc 为例,我们首先需要看他是否有提供扩展的 API 可以供我们埋点,恰好 grpc 是有提供客户端和服务端的拦截器的。
1
2
| io.grpc.ClientInterceptor
io.grpc.ServerInterceptor
|
我们便可以在这些拦截中加入埋点逻辑,比如客户端的埋点代码如下 io.opentelemetry.instrumentation.grpc.v1_6.TracingClientInterceptor :

这部分代码便是写在 grpc-1.6/library 模块下的。
这样做有一个好处是:当我们的业务代码不想使用 javaagent 时还可以手动引入 grpc-1.6/library 包,然后使用 TracingClientInterceptor 拦截器也可以实现 trace 埋点的功能。
1
| implementation(project(":instrumentation:grpc-1.6:library"))
|
之后 javaagent 这个模块也会引入 library ,然后直接使用它提供的 API 实现 agent 级别的埋点。
而如果一些库或者中间件并没有提供这种扩展 API 时,我们就只能使用 agent 的方式在字节码层面上进行埋点,这样就不会限制框架了,理论上任何 Java 代码都可以埋点。
所以总的来说一个库可能会没有 library instrumentation,但一定会有 agent instrumentation,我们可以根据当前框架的代码进行选择。
而这里的 PowerJob 因为并没有提供扩展接口,所有只有 agent 的 instrumentation。
找到埋点入口
在开始编码之前我们需要对要埋点的库或者框架有一个清晰的理解,至少得知道它的核心逻辑在哪里。
以 PowerJob 的调度执行逻辑为例:
1
2
3
4
5
6
7
8
9
| public class TestBasicProcessor implements BasicProcessor {
@Override
public ProcessResult process(TaskContext context) throws Exception {
System.out.println("======== BasicProcessor#process ========");
System.out.println("TaskContext: " + JsonUtils.toJSONString(context) + ";time = " + System.currentTimeMillis());
return new ProcessResult(true, System.currentTimeMillis() + "success");
}
}
|
这是一个最简单的调度执行器的实现逻辑。
从这里看出:如果我们想要在执行器中埋点,那最核心的就是这里的 process 函数。
需要在 process 的执行前后拿到 context 数据,写入到 OpenTelemetry 中的 span 即可。
1
2
3
4
5
6
7
| public class SimpleCustomizedHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String s) throws Exception {
return new ReturnT<>("Hello World");
}
}
|
而在 xxl-job 中,它的核心逻辑就是这里的 execute 函数。
选择合适的版本
找到核心的埋点逻辑后还有一个很重要的工作要做:那就是选择你需要支持的版本。
选择版本的原因是有可能框架或库在版本迭代过程中核心 API 发生了变化,比如:
以 xxl-job 为例,它在迭代过程中就发生了几次函数签名的修改,所以我们需要针对不同的版本做兼容处理:

而我这里选择支持 PowerJob:4.0+ 的版本,因为社区在 4.0 之后做了大量重构,导致修改了包名,同时核心逻辑的函数签名也没发生过变化。
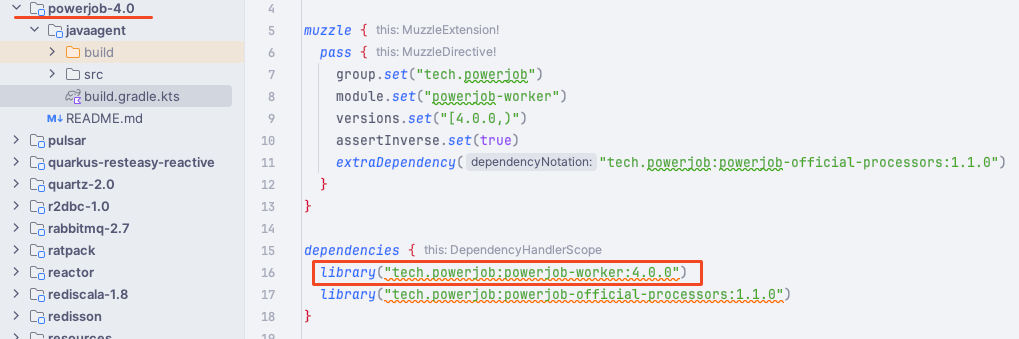
4.0 之前的版本我就没做兼容了,感兴趣的朋友可以自行实现。
逻辑实现
首先第一步需要创建一个 InstrumentationModule:
1
2
3
4
5
6
7
8
9
10
| @AutoService(InstrumentationModule.class)
public class PowerJobInstrumentationModule extends InstrumentationModule {
public PowerJobInstrumentationModule() {
super("powerjob", "powerjob-4.0");
}
@Override
public List<TypeInstrumentation> typeInstrumentations() {
return asList(new BasicProcessorInstrumentation());
}
}
|

这里的 @AutoService 注解,会在代码编译之后生成一份 SPI 文件。
之后便是实现这里最核心的 BasicProcessorInstrumentation。
1
2
3
4
5
6
7
8
9
10
11
12
| public class BasicProcessorInstrumentation implements TypeInstrumentation {
@Override
public ElementMatcher<TypeDescription> typeMatcher() {
return implementsInterface(named("tech.powerjob.worker.core.processor.sdk.BasicProcessor"));
}
@Override
public void transform(TypeTransformer transformer) {
transformer.applyAdviceToMethod(
named("process").and(isPublic()).and(takesArguments(1)),
BasicProcessorInstrumentation.class.getName() + "$ProcessAdvice");
}
}
|
从它的代码也可以看出,这里主要是指定我们需要对哪个方法的哪个函数进行埋点,然后埋点之后的处理逻辑是在哪个类(ProcessAdvice)中实现的。
之后便是 ProcessAdvice 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public static class ProcessAdvice {
@SuppressWarnings("unused")
@Advice.OnMethodEnter(suppress = Throwable.class)
public static void onSchedule(
@Advice.This BasicProcessor handler,
@Advice.Argument(0) TaskContext taskContext,
@Advice.Local("otelRequest") PowerJobProcessRequest request,
@Advice.Local("otelContext") Context context,
@Advice.Local("otelScope") Scope scope) {
Context parentContext = currentContext();
request = PowerJobProcessRequest.createRequest(taskContext.getJobId(), handler, "process");
request.setInstanceParams(taskContext.getInstanceParams());
request.setJobParams(taskContext.getJobParams());
context = helper().startSpan(parentContext, request);
if (context == null) {
return;
} scope = context.makeCurrent();
}
@SuppressWarnings("unused")
@Advice.OnMethodExit(onThrowable = Throwable.class, suppress = Throwable.class)
public static void stopSpan(
@Advice.Return ProcessResult result,
@Advice.Thrown Throwable throwable,
@Advice.Local("otelRequest") PowerJobProcessRequest request,
@Advice.Local("otelContext") Context context,
@Advice.Local("otelScope") Scope scope) {
helper().stopSpan(result, request, throwable, scope, context);
}
}
|
这里最主要的就是使用 OpenTelemetry 提供 SDK 在入口处调用 startSpan 开始一个 span,然后在函数退出时调用 stopSpan 函数。
同时在执行前将一些请求信息存起来:
1
| request = PowerJobProcessRequest.createRequest(taskContext.getJobId(), handler, "process");
|
这样可以根据这些请求信息生成 span 的 attribute,也就是 jobId, jobParam 等数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
| class PowerJobExperimentalAttributeExtractor
implements AttributesExtractor<PowerJobProcessRequest, Void> {
@Override
public void onStart(
AttributesBuilder attributes,
Context parentContext,
PowerJobProcessRequest powerJobProcessRequest) {
attributes.put(POWERJOB_JOB_ID, powerJobProcessRequest.getJobId());
attributes.put(POWERJOB_JOB_PARAM, powerJobProcessRequest.getJobParams());
attributes.put(POWERJOB_JOB_INSTANCE_PARAM, powerJobProcessRequest.getInstanceParams());
attributes.put(POWERJOB_JOB_INSTANCE_TRPE, powerJobProcessRequest.getJobType());
}
|
比如这里的 jobId/ jobParams 数据都是从刚才写入的 PowerJobProcessRequest 中获取的。
1
2
3
4
5
| if (CAPTURE_EXPERIMENTAL_SPAN_ATTRIBUTES) {
builder.addAttributesExtractor(
AttributesExtractor.constant(AttributeKey.stringKey("job.system"), "powerjob"));
builder.addAttributesExtractor(new PowerJobExperimentalAttributeExtractor());
}
|
同时只需要将刚才的 PowerJobExperimentalAttributeExtractor 在初始化 Instrumenter 时进行配置,这样 OpenTelemetry 的 SDK 就会自动回调这个接口,从而获取到 Span 的 attribute。
1
2
3
4
| import static net.bytebuddy.matcher.ElementMatchers.isPublic;
import static net.bytebuddy.matcher.ElementMatchers.named;
import static net.bytebuddy.matcher.ElementMatchers.takesArguments;
import net.bytebuddy.asm.Advice;
|
其实这里大部分的 API 都是 bytebuddy 提供的。
不知道大家是否觉得眼熟,Instrumentation 的写法其实和 spring 的拦截器有异曲同工之妙:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.ProceedingJoinPoint;
@Aspect
public class AroundExample {
@Around("execution(* com.xyz..service.*.*(..))")
public Object doBasicProfiling(ProceedingJoinPoint pjp) throws Throwable {
Object retVal = pjp.proceed();
return retVal;
}
}
|
毕竟 Spring 的拦截器也是使用 bytebuddy 实现的。
一些坑
其实整个埋点过程非常简单,我们可以参考一些现有的 instrumentation 就可以很快实现逻辑;真正麻烦的时候在提交 PR 时需要通过 CI 校验。

我这里大概提交了 8次才把 CI 全部跑通过。
这里面有各种小坑,只有自己提交过才能感受得到,下面我就一一列举一些大家可能会碰到的问题。
创建模块
首先第一个是创建模块的时候记得使用 kotlin 作为 gradle 的 DSL。
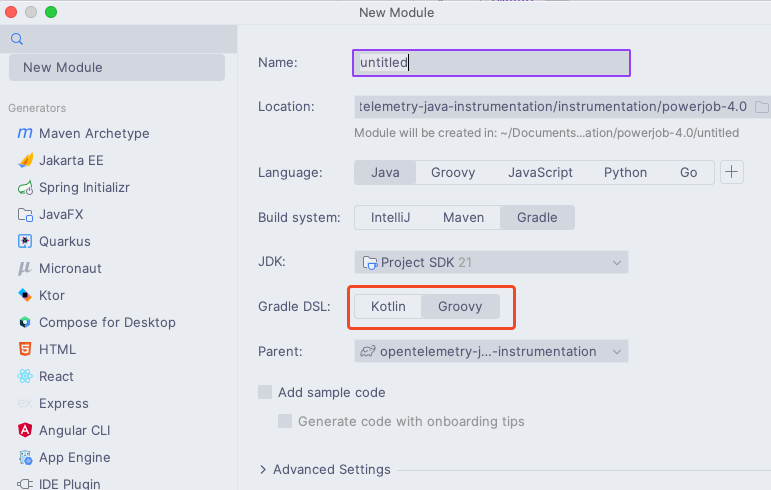
IDEA 这里默认选择的是 Groovy 作为 DSL;我当时没有注意,后面在项目构建过程中一直在报错,仔细核对后发现是 DSL 的问题,修改之后就能编译通过了。
项目构建
第二个是 module 的命名规则。

我们需要遵守 v4_0_0 的规则,同时还得与 PowerJobInstrumentationModule 中定义的名称相同:
1
2
3
| public PowerJobInstrumentationModule() {
super("powerjob", "powerjob-4.0");
}
|
比如如果我们的包名称是 powerjob.v1.1.0 ,那这里的名称也得是 "powerjob-1.1.0"
Muzzle
第三个是 Muzzle 校验,Muzzle 是为了保证 javaagent 在业务代码中使用时和运行时的依赖不发生冲突而定义的一个校验规则。
1
2
3
4
5
6
7
8
9
| muzzle {
pass {
group.set("tech.powerjob")
module.set("powerjob-worker")
versions.set("[4.0.0,)")
assertInverse.set(true)
extraDependency("tech.powerjob:powerjob-official-processors:1.1.0")
}
}
|
以我这个为例,它的含义是兼容 tech.powerjob:powerjob-worker:4.0.0+以上的版本。
assertInverse.set(true): 的作用是与之相反的版本,也就是 4.0.0 以下的版本都不做支持,如果在这些版本中运行 javaagent 是不会生效的。
因为这些低版本的 powerjob 不兼容我们的埋点代码。
extraDependency:的作用是额外需要依赖的包,我这里额外使用了这个包里的一些类,如果不加上的话在做 Muzzle 校验时也会失败。
单元测试
最后便是单元测试了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| @Test
void testBasicProcessor() throws Exception {
long jobId = 1;
String jobParam = "abc";
TaskContext taskContext = genTaskContext(jobId, jobParam);
BasicProcessor testBasicProcessor = new TestBasicProcessor();
testBasicProcessor.process(taskContext);
testing.waitAndAssertTraces(
trace -> {
trace.hasSpansSatisfyingExactly(
span -> {
span.hasName(String.format("%s.process", TestBasicProcessor.class.getSimpleName()));
span.hasKind(SpanKind.INTERNAL);
span.hasStatus(StatusData.unset());
span.hasAttributesSatisfying(
attributeAssertions(
TestBasicProcessor.class.getName(), jobId, jobParam, BASIC_PROCESSOR));
});
});
}
private static List<AttributeAssertion> attributeAssertions(
String codeNamespace, long jobId, String jobParam, String jobType) {
List<AttributeAssertion> attributeAssertions =
new ArrayList<>(
asList(
equalTo(AttributeKey.stringKey("code.namespace"), codeNamespace),
equalTo(AttributeKey.stringKey("code.function"), "process"),
equalTo(AttributeKey.stringKey("job.system"), "powerjob"),
equalTo(AttributeKey.longKey("scheduling.powerjob.job.id"), jobId),
equalTo(AttributeKey.stringKey("scheduling.powerjob.job.type"), jobType)));
if (!StringUtils.isNullOrEmpty(jobParam)) {
attributeAssertions.add(
equalTo(AttributeKey.stringKey("scheduling.powerjob.job.param"), jobParam));
}
return attributeAssertions;
}
|
测试的逻辑很简单,就是模拟一下核心逻辑的调用,然后断言是否存在我们预期的 Span,同时还得校验它的 attribute 是否符合我们的预期。
这个单测当时也调了许久,因为 versions.set("[4.0.0,)") 这个配置,有一个 CI workflow 会校验最新版本的 powerjob 是否也能正常运行。
比如它会拉取目前最新的依赖进行测试:
1
| implementation("tech.powerjob:powerjob-worker:5.1.0")
|
如果我们在单测中依赖了某些版本不存在的类,或者是函数签名发生过变化的函数用于测试,那这个 CI 就会执行失败。
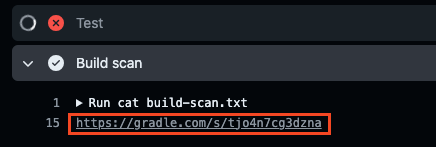
因为这里的构建日志非常多,同时还是并发测试的,如果我们想直接查看日志来定位问题会非常麻烦。
当然社区也考虑到了,可以在 “Build scan” 这个步骤中查看 gradle 的构建日志。

这里会直接输出具体是哪里构建出了问题,通过它我们就能很快定位到原因。
我这里也是因为使用的某些帮助函数在最新的版本中发生了变化,为了测试通过,就不得不调整测试代码了。
如果你发现必须得依赖这些类或者函数来配合测试,那就只有考虑分为多个不同的版本进行测试,类似于 xxl-job:
总结
以上就是整个 instrumentation 的编写过程,其中核心的埋点过程并不复杂,只要我们对需要埋点的库或框架比较熟悉,都可以实现埋点。
真正麻烦的是需要通过社区复杂且严谨的 CI 流程,好在不管是哪一步的 CI 失败都可以查到具体的原因,有点类似于升级打怪,跟着错误信息走,最终都能验证通过。
参考链接: