StarRocks 开发环境搭建踩坑指北
背景
最近这段时间在处理一个 StarRocks 的关于物化视图优化的一个问题,在此之前其实我也没有接触过 StarRocks 这类主要处理数据分析的数据库,就更别提在这上面做优化了。
在解决问题之前我先花了一两天时间熟悉了一下 StarRocks 的一些概念和使用方法,然后又花了一些时间搭建环境然后复现了该问题。
之后便开始阅读源码,大概知道了相关代码的执行流程,但即便是反复阅读了多次代码也没有找到具体出现问题的地方。
所以便考虑在本地 Debug 源码,最终调试半天之后知道了问题所以,也做了相关修改,给社区提交了 PR,目前还在推进过程中。
环境搭建
这里比较麻烦的是如何在本地 debug 代码。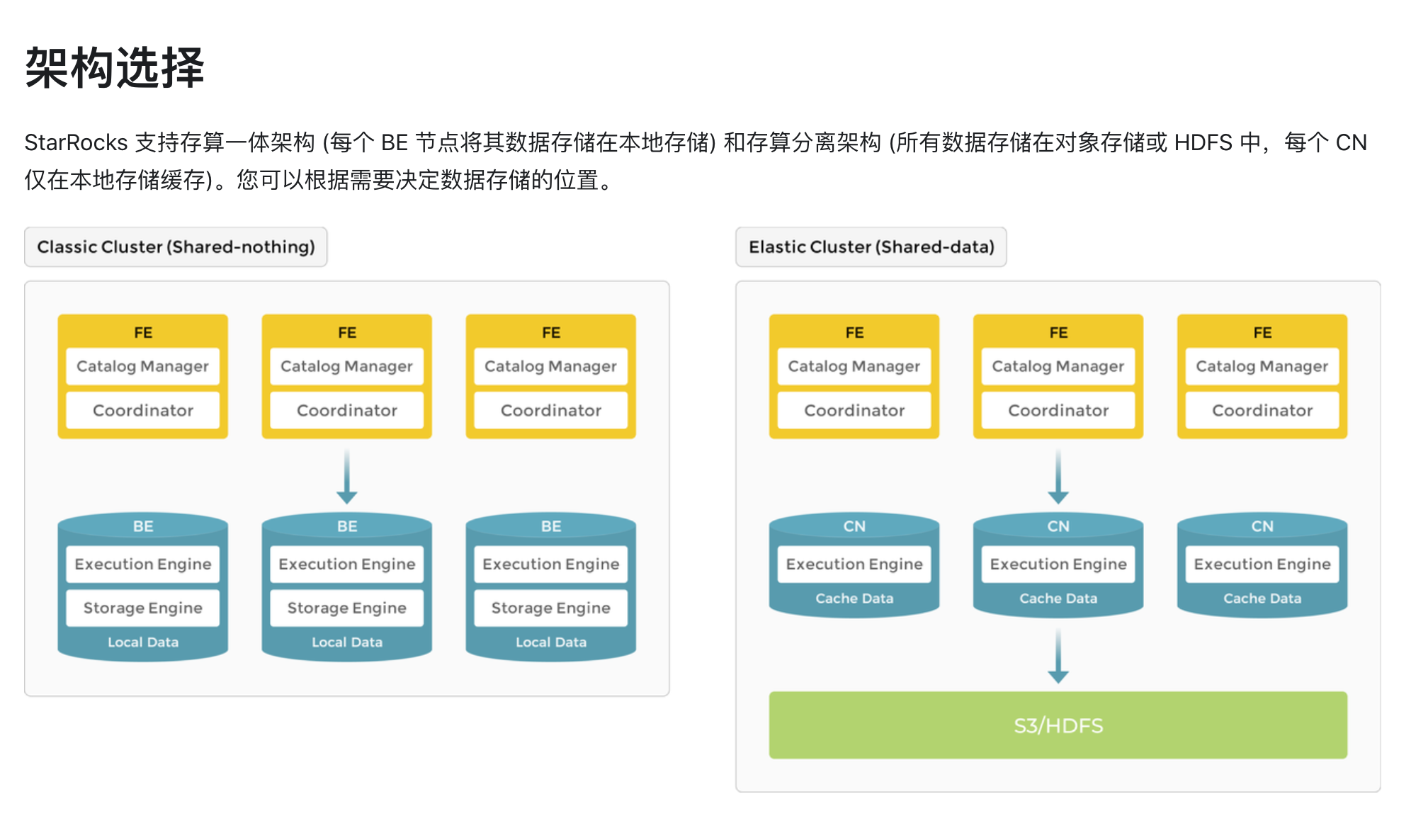
根据官方的架构图会发现 StarRocks 主要分为两个部分:
- FE:也就是常说的前端部分,主要负责元数据管理和构建执行计划。
- BE:后端存储部分,执行查询计划并存储数据。
其中 FE 是 Java 写的,而存储的 BE 则是 C++ 写的,我这次需要修改的是 FE 前端的部分,所以本篇文章主要讨论的是 FE 相关的内容。
好在社区已经有关于如何编译和构建源码的教程,这里我列举一些重点,FE 首先需要安装以下一些工具:
- Thrift
- Protobuf
- Python3
- JDK8+
1 | |
以上默认是在 Mac 平台上安装的流程,所以全程使用 brew 最方便了,如果是其他平台也是同理,只要安装好这些工具即可。
紧接着便是编译 FE,我们需要先下载源码,然后进入 FE 的目录:
1 | |
然后直接使用 maven 编译安装即可。
这里需要注意⚠️,因为编译过程中需要使用 Python3 来执行一些构建任务,新版本的 Mac 都是内置 Python3 的,但如果是老版本的 Mac 内置的则是 Python2。
这时就需要我们将 Python3 的命令手动在构建任务里指定一下:

比如我这里的 Python3 命令为 python3
我们需要在 fe/fe-core/pom.xml 目录里修改下 Python 的命令名称: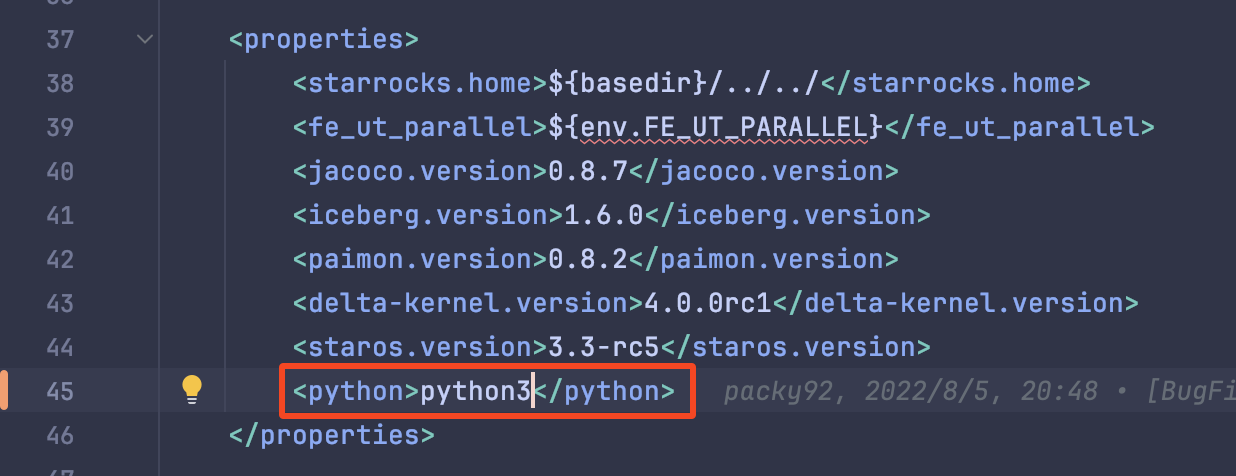
修改之后再 mvn install 编译一次,如果一切顺利的话便会编译成功。
搭建本地集群
启动 FE
我的最终目的是可以在本地 IDEA 中启动 FE 然后再配合启动一个 BE,这样就可以在 IDEA 中调试 FE 的源码了。
在启动 FE 之前还需要创建一些目录:
1 | |
主要就是要在 FE 的目录下创建配置文件、执行脚本、日志、元数据等目录。
接着便可以打开 com.starrocks.StarRocksFE 类在 IDEA 中运行了,在启动之前还需要配置一下环境变量:
1 | |
同时需要配置下 fe.conf 中的 priority_networks 网络配置:
1 | |
这个 IP 得是宿主机的 IP,后续我们使用 docker 启动 BE 的时候也需要用到。
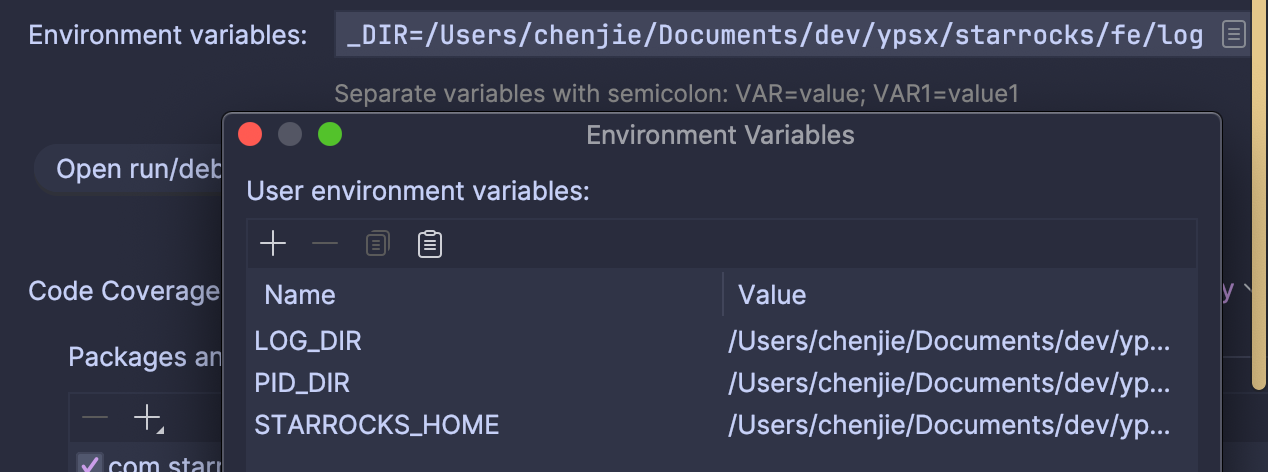
如果启动失败,可以在日志目录下查看日志:
1 | |
碰到这个异常:提示端口被占用,那可以尝试关闭代理之后再试试。
启动成功后我们便可以使用 MySQL 兼容的客户端进行连接了,这里我使用的是 tableplus:
然后我们使用以下 sql 可以查询 fe 的节点状态:
1 | |
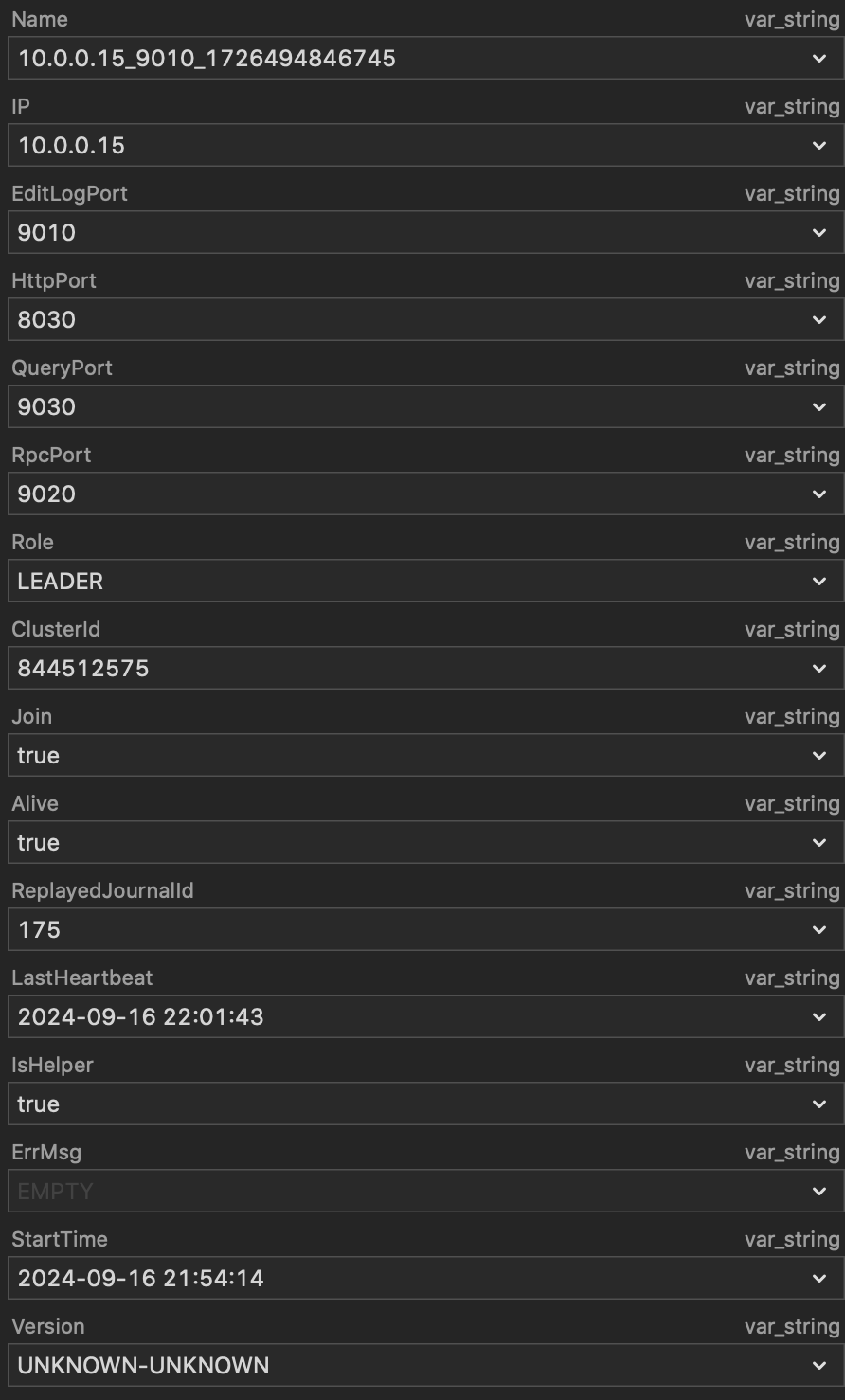
看到类似的输出则代表启动成功了。
启动 BE
之后我们便可以使用 Docker 来启动 BE 了,之所以用 docker 启动,是因为 BE 是 C++ 编写的,想要在 Mac 上运行比较麻烦,最好是得有一台 Ubuntu22 的虚拟机。
如果我们不需要调试 BE 的话,只使用 docker 启动是再合适不过了。
1 | |
我们需要将 FE 需要连接 BE 的端口暴露出来,启动成功后该镜像并不会直接启动 BE,我们需要进入容器手动启动。
1 | |
在启动之前我们依然需要修改下 be.conf 中的 priority_networks 配置:
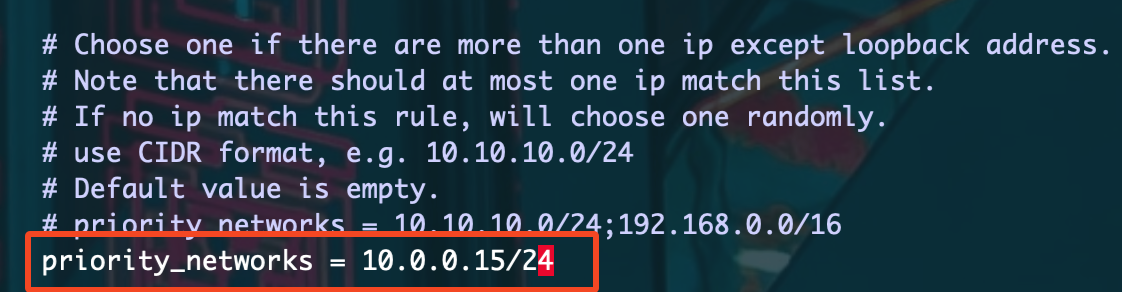
修改为和 fe.conf 中相同的配置。
之后使用以下命令启动 be:
1 | |
启动日志我们可以在 logs 目录中查看。
绑定 FE 和 BE
接下来还有最后一步就是将 FE 和 BE 绑定在一起。
我们在 fe 中执行以下 sql:
1 | |
手动添加一个节点,之后再使用:
1 | |
可以查询到 BE 的节点状态:
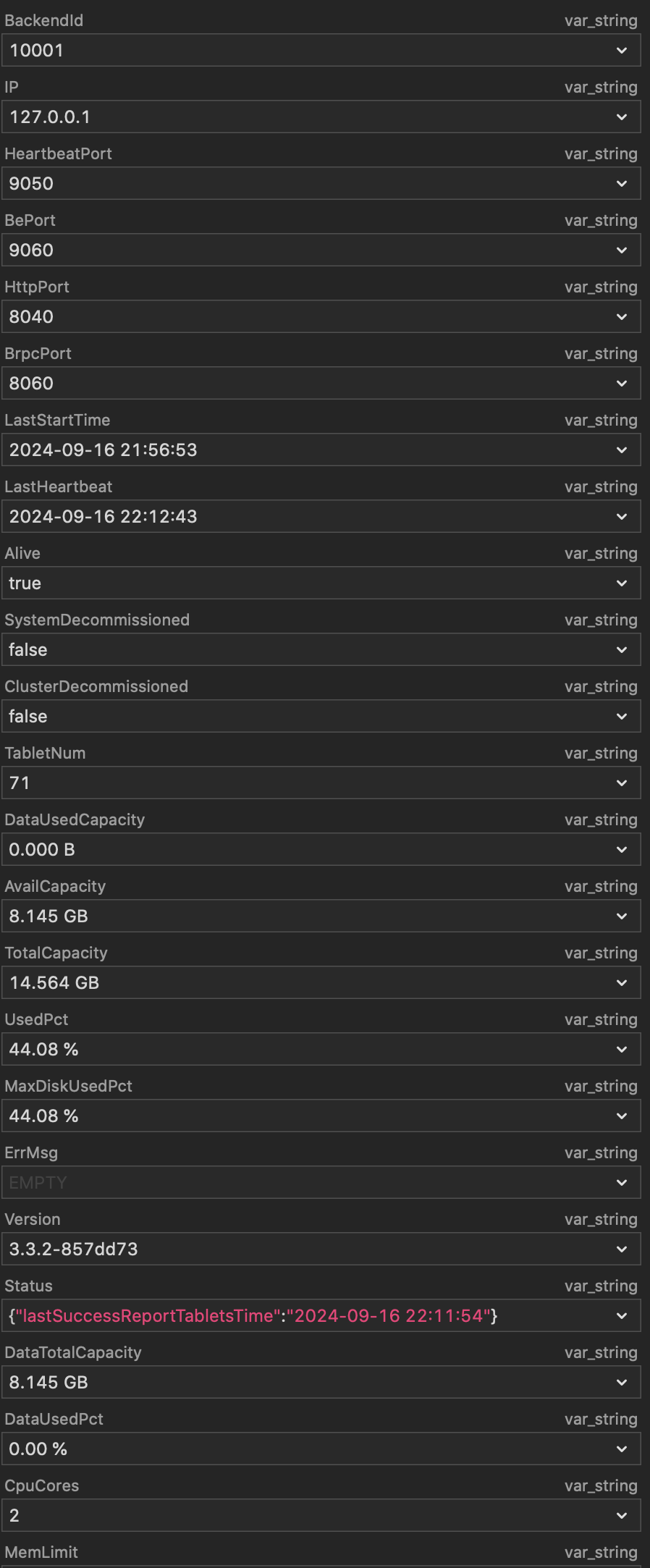
如果出现以下结果代表连接成功,这样我们就可以创建数据库和表了。
总结
这部分内容(本地 FE 联结 docker 里的 FE)官方文档并没有提及,也是我踩了不少坑、同时还咨询了一些大佬才全部调试成功。
还有一点需要注意的事:如果我们网络环境发生了变化,比如从家里的 Wi-Fi 切换到了公司的,需要手动删除下 FE/meta 下的所有文件再次启动,BE 则是需要重启一下容器。
参考链接: