groups: -name:AllInstances rules: -alert:InstanceDown # Condition for alerting expr:up==0 for:1m # Annotation - additional informational labels to store more information annotations: title:'Instance {{ $labels.instance }} down' description:'{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute.' # Labels - additional labels to be attached to the alert labels: severity:'critical'
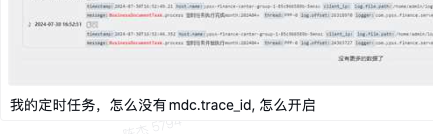
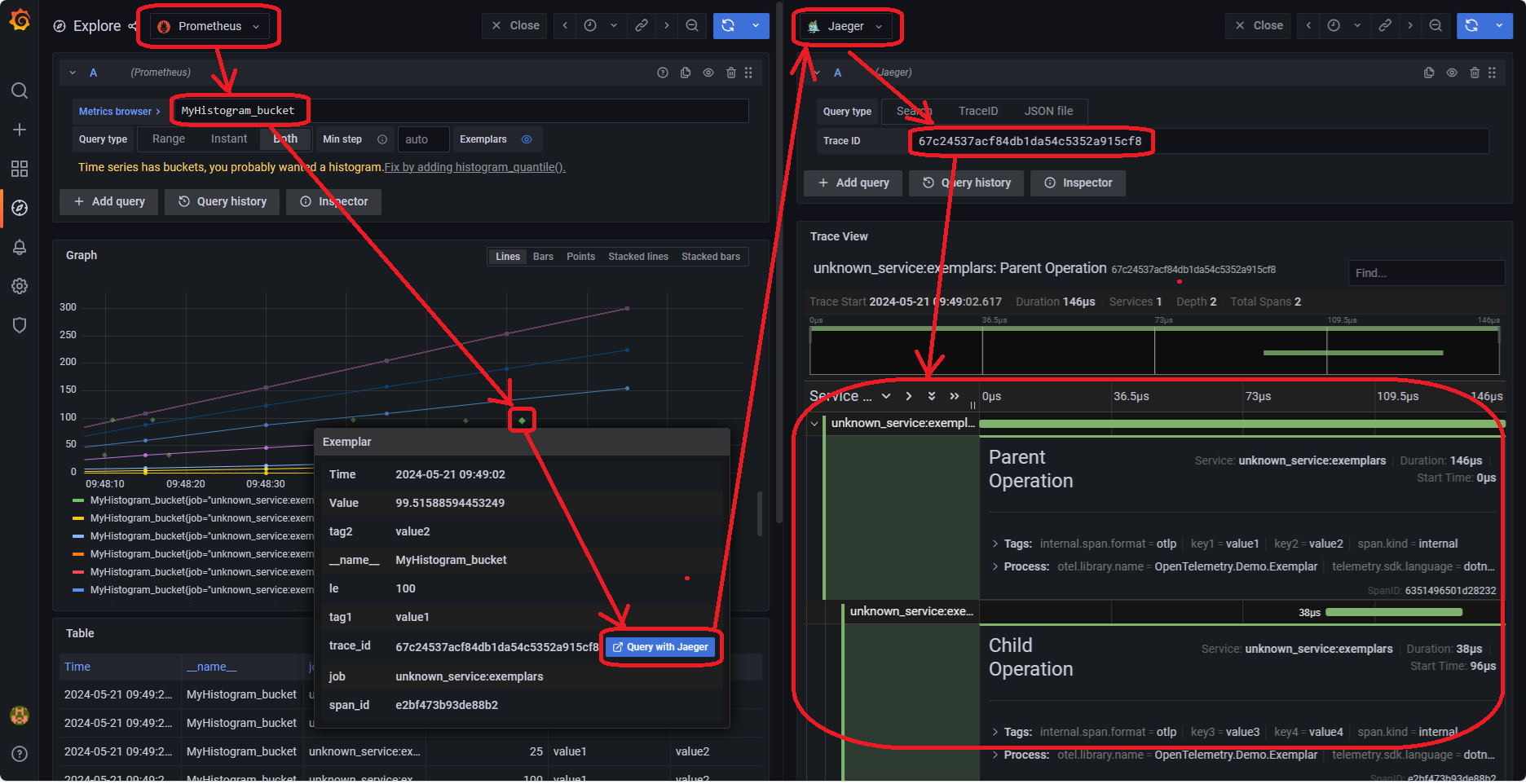
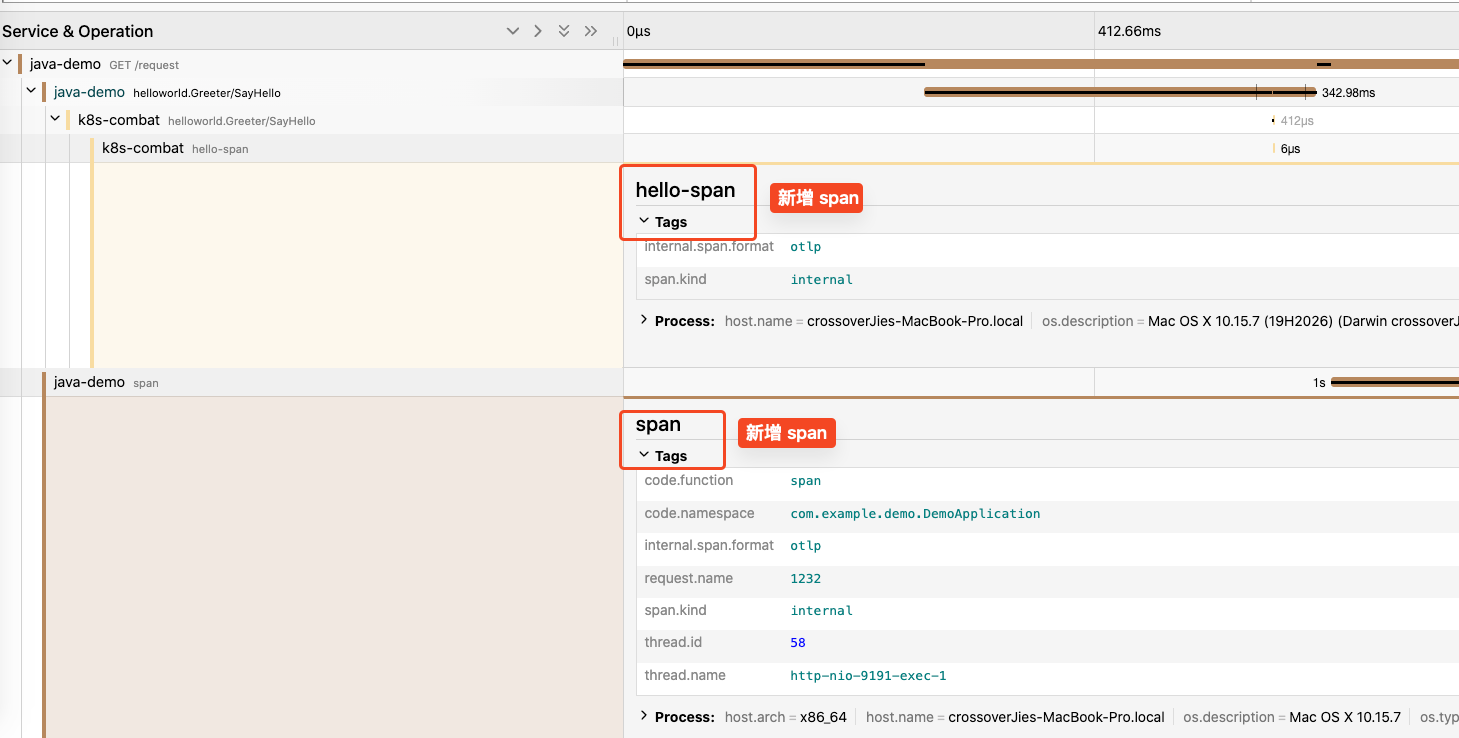
这可以让我们尽早发现故障。
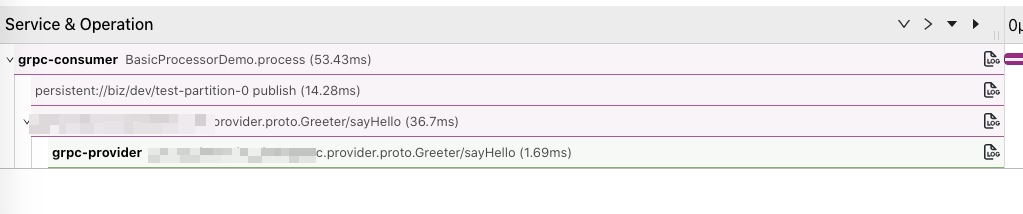
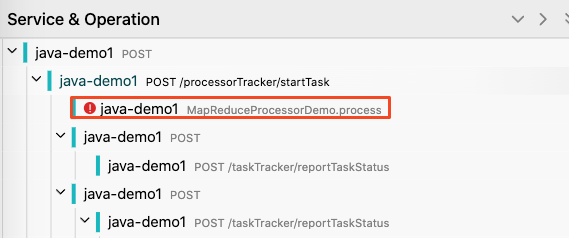
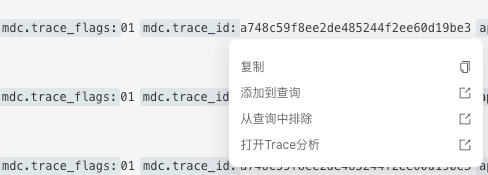
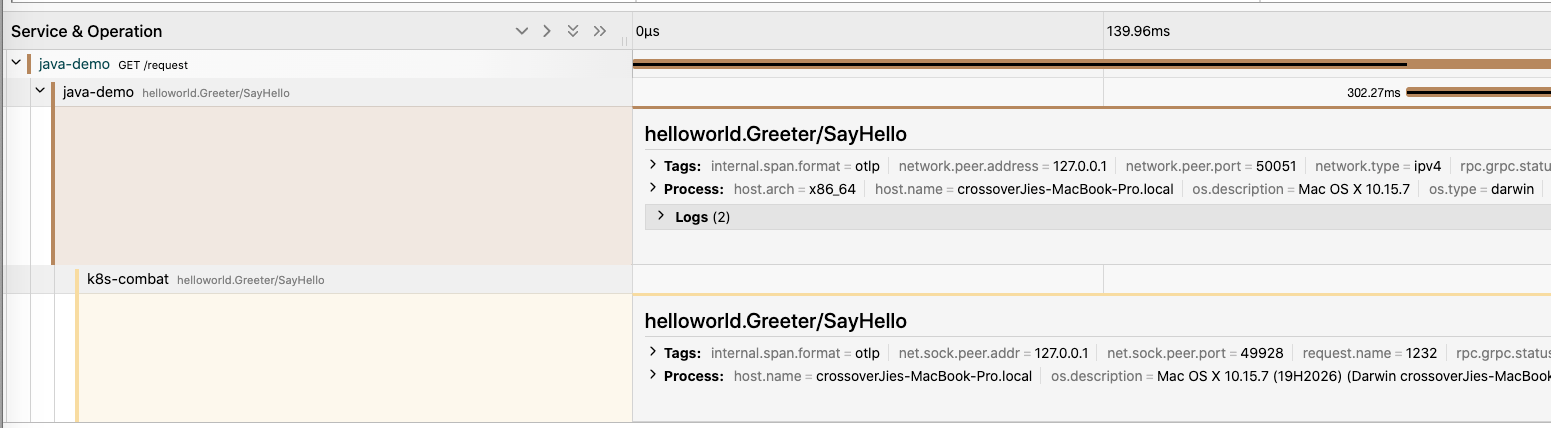
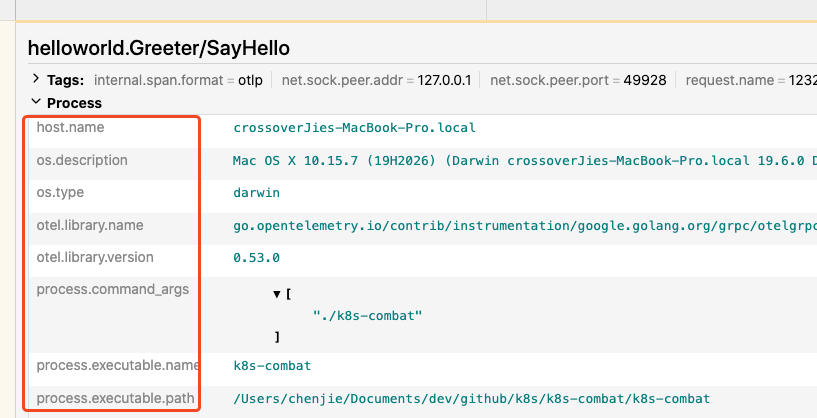
之后我们可以通过链路信息找到发生故障的节点。
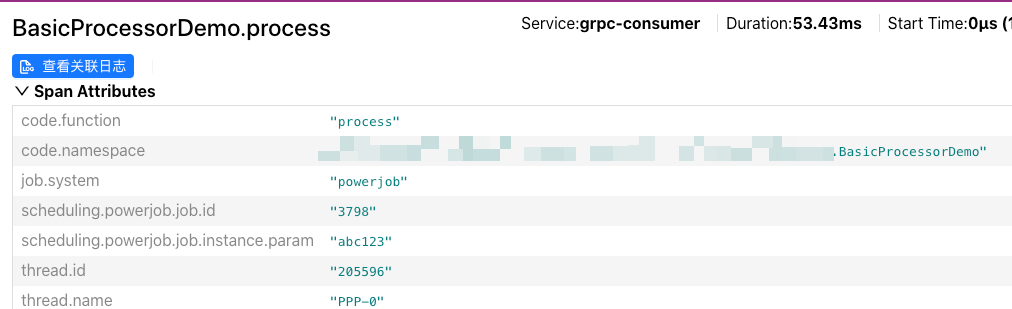
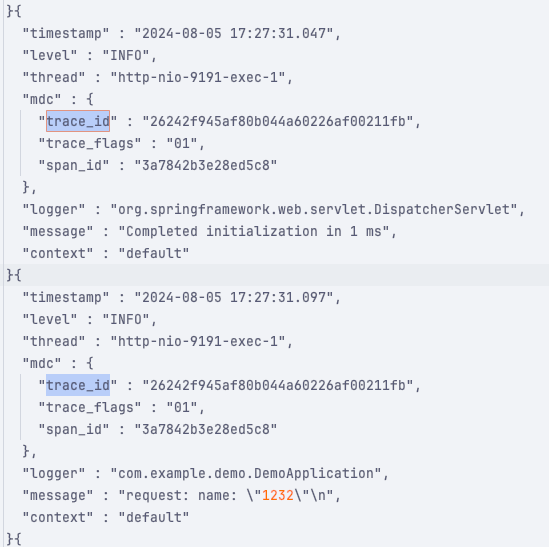
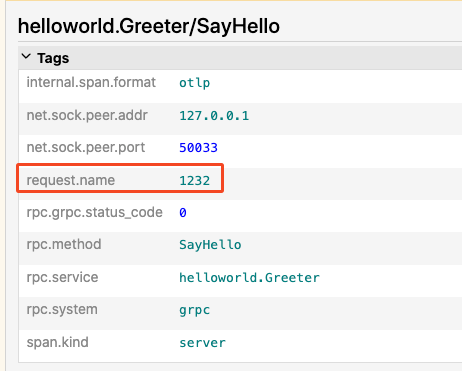
然后通过这里的 trace_id 在应用中找到具体的日志:
1
mdc.trace_id:4a686dedcdf4e95b1a83b36e62563a96
再根据日志中的上下文确定具体的异常原因。
这就是一个完整的排查问题的流程。
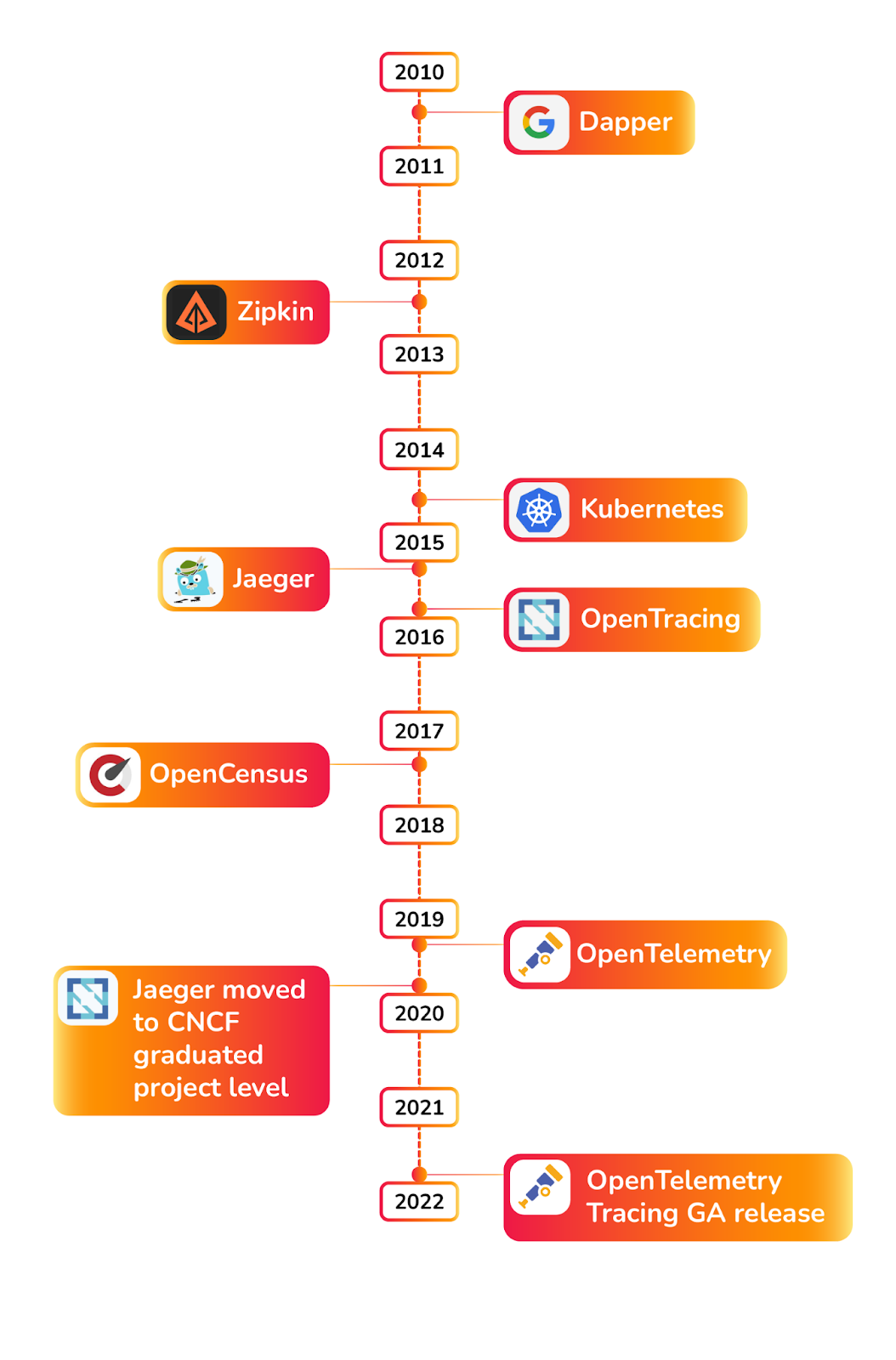
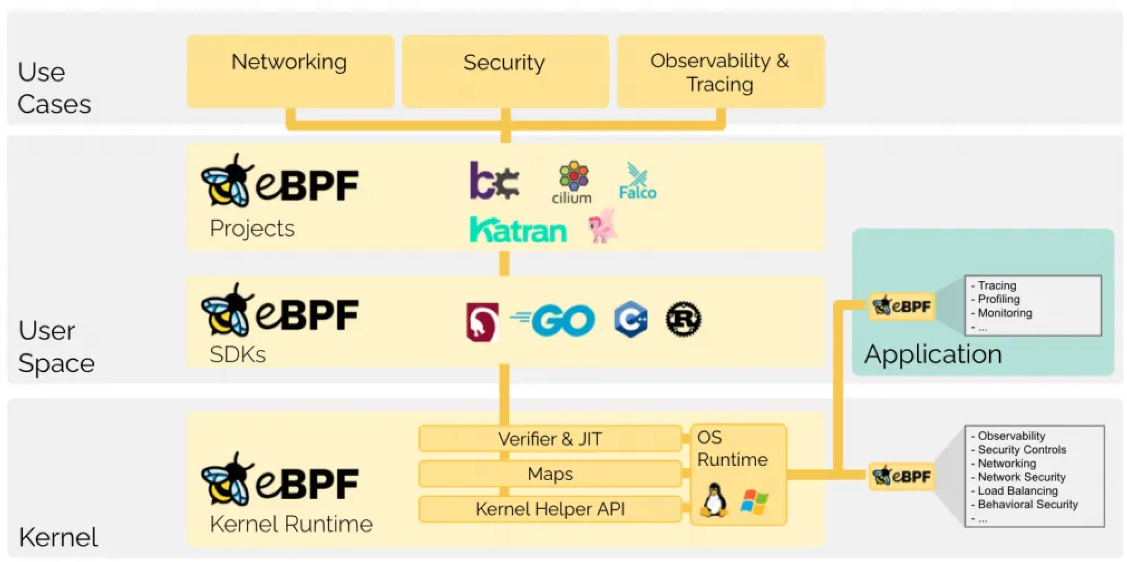
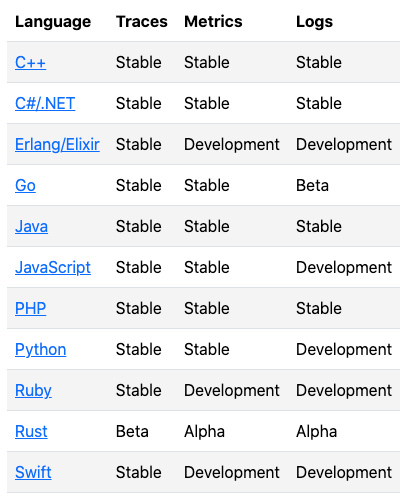
OpenTelemetry 发展历史
在 OpenTelemetry 开始之前还是先回顾下可观测性的发展历史,其中有几个重要时间点:
2010 年 Google 发布了 Dapper 论文,给业界带来了实现分布式追踪的理论支持,之后的许多分布式链路追踪实现都有它的影子
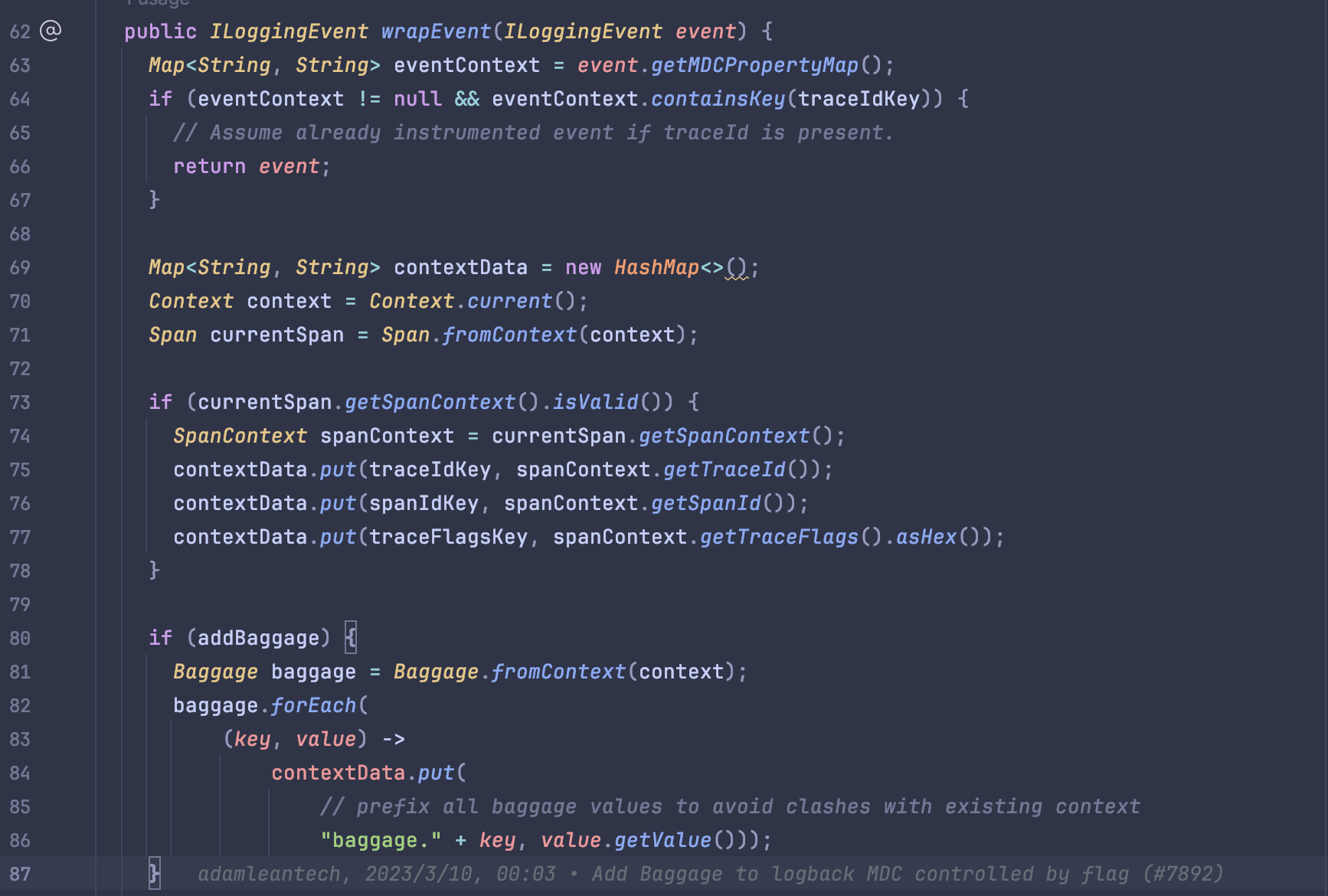
Map<String, String> spanContextData = newHashMap<>(); SpanContextspanContext= Java8BytecodeBridge.spanFromContext(context).getSpanContext(); if (spanContext.isValid()) { spanContextData.put(traceIdKey(), spanContext.getTraceId()); spanContextData.put(spanIdKey(), spanContext.getSpanId()); spanContextData.put(traceFlagsKey(), spanContext.getTraceFlags().asHex()); } spanContextData.putAll(ConfiguredResourceAttributesHolder.getResourceAttributes()); if (LogbackSingletons.addBaggage()) { Baggagebaggage= Java8BytecodeBridge.baggageFromContext(context); // using a lambda here does not play nicely with instrumentation bytecode process // (Java 6 related errors are observed) so relying on for loop instead for (Map.Entry<String, BaggageEntry> entry : baggage.asMap().entrySet()) { spanContextData.put( // prefix all baggage values to avoid clashes with existing context "baggage." + entry.getKey(), entry.getValue().getValue()); }} if (contextData == null) { contextData = spanContextData; } else { contextData = newUnionMap<>(contextData, spanContextData); }
if (operationListeners.length != 0) { // operation listeners run after span start, so that they have access to the current span // for capturing exemplars longstartNanos= getNanos(startTime); for (inti=0; i < operationListeners.length; i++) { context = operationListeners[i].onStart(context, attributes, startNanos); } }
if (operationListeners.length != 0) { longendNanos= getNanos(endTime); for (inti= operationListeners.length - 1; i >= 0; i--) { operationListeners[i].onEnd(context, attributes, endNanos); } }
mp := initMeterProvider() deferfunc() { if err := mp.Shutdown(context.Background()); err != nil { log.Printf("Error shutting down meter provider: %v", err) } }()
和 Tracer 类似,我们首先也得在 main 函数中调用 initMeterProvider() 函数来初始化 Meter,此时它会返回一个 sdkmetric.MeterProvider 对象。
OpenTelemetry Go 的 SDK 中已经提供了对 go runtime 的自动埋点,我们只需要调用相关函数即可:
1 2 3 4
err := runtime.Start(runtime.WithMinimumReadMemStatsInterval(time.Second)) if err != nil { log.Fatal(err) }
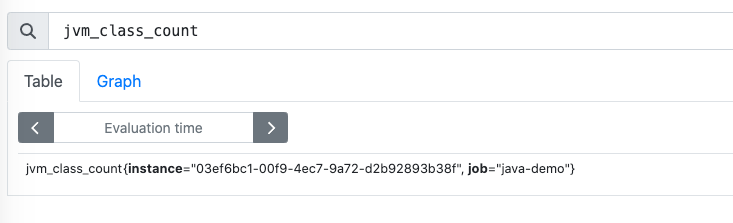
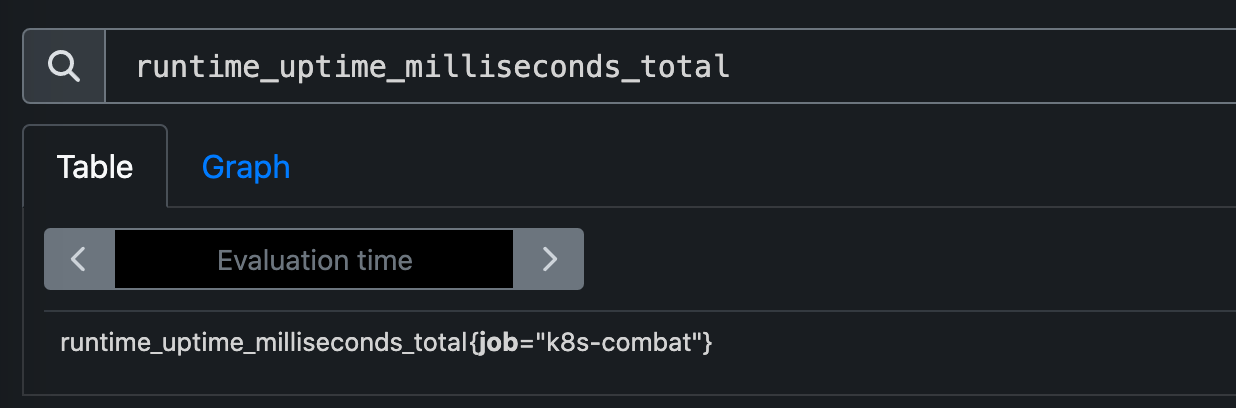
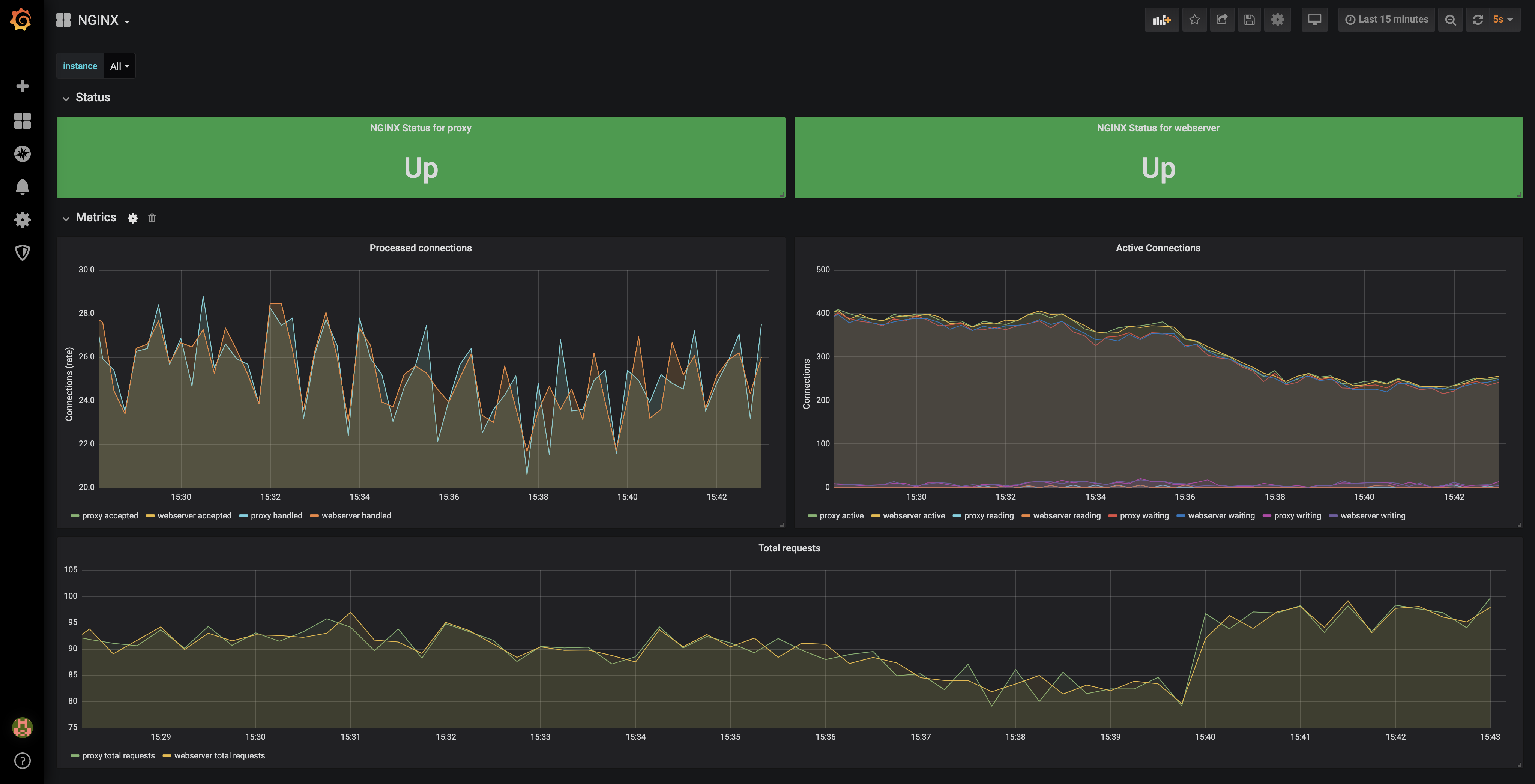
之后我们启动应用,在 Prometheus 中就可以看到 Go 应用上报的相关指标了。
runtime_uptime_milliseconds_total Go 的运行时指标
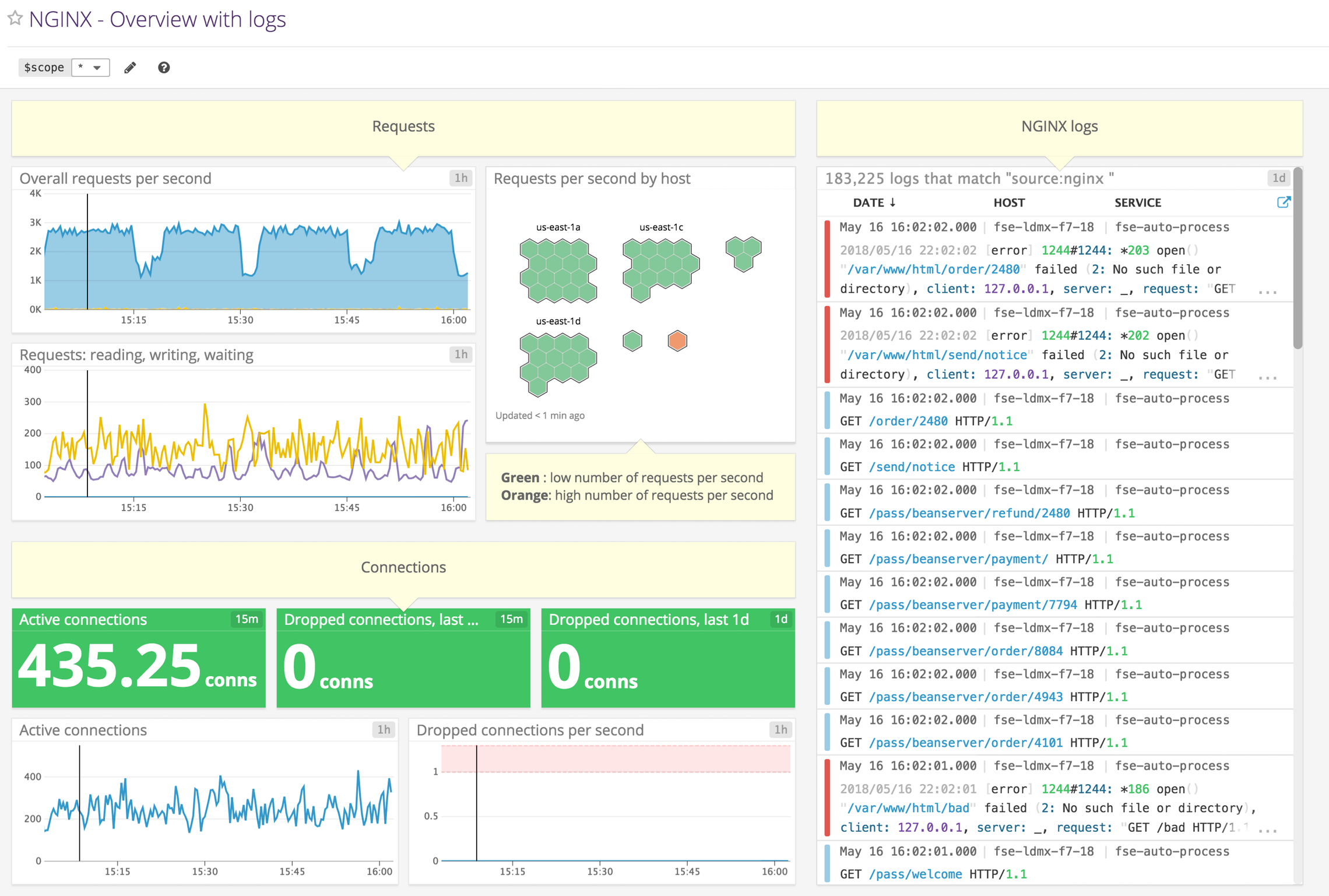
Prometheus 中展示指标的 UI 能力有限,通常我们都是配合 grafana 进行展示的。
手动上报指标
当然除了 SDK 自动上报的指标之外,我们也可以类似于 trace 那样手动上报一些指标;
比如我就想记录某个函数调用的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
var meter = otel.Meter("test.io/k8s/combat") apiCounter, err = meter.Int64Counter( "api.counter", metric.WithDescription("Number of API calls."), metric.WithUnit("{call}"), ) if err != nil { log.Err(err) }
messageInCounter = meter .counterBuilder(MESSAGE_IN_COUNTER) .setUnit("{message}") .setDescription("The total number of messages received for this topic.") .buildObserver();
// AddEvent adds an event with the provided name and options. AddEvent(name string, options ...EventOption) // AddLink adds a link. // Adding links at span creation using WithLinks is preferred to calling AddLink // later, for contexts that are available during span creation, because head // sampling decisions can only consider information present during span creation. AddLink(link Link)
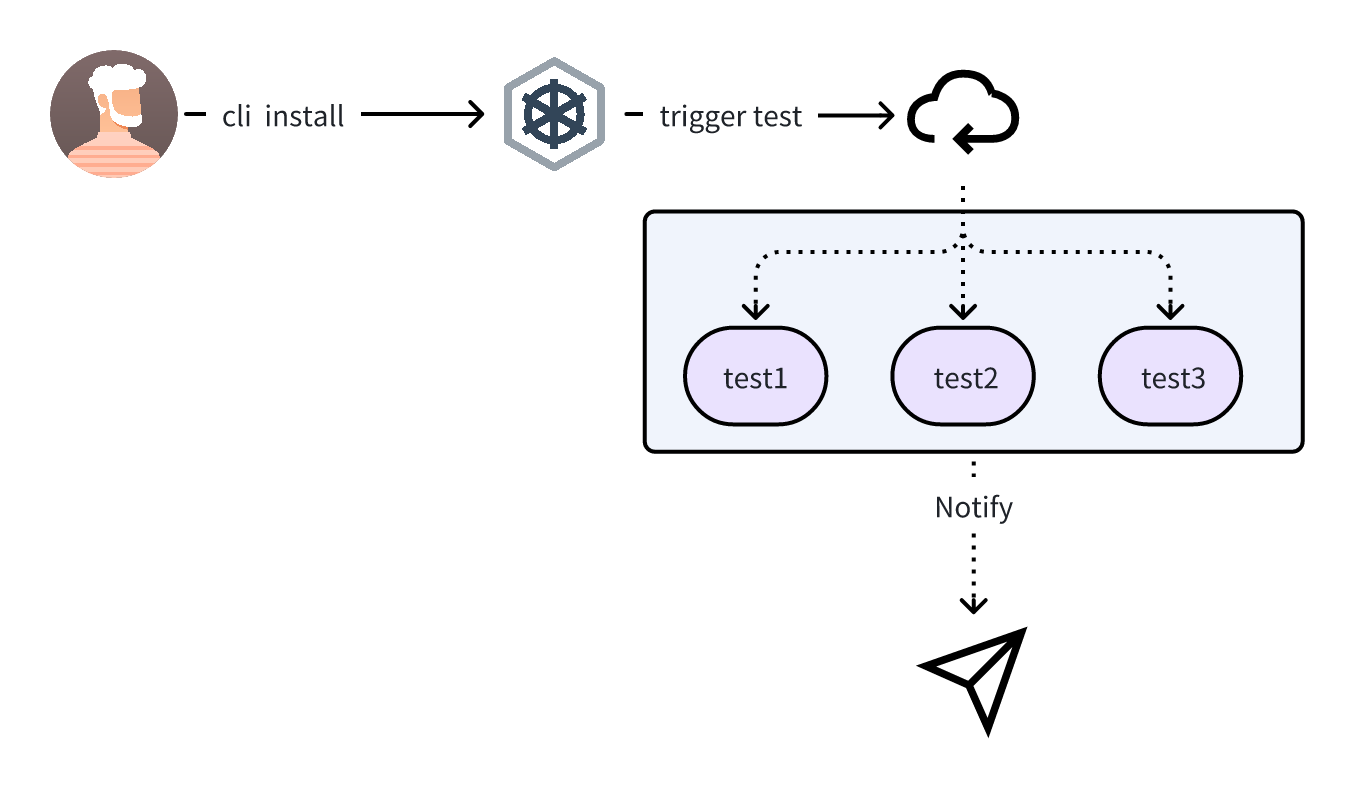
pulsar-upgrade-cli -h ok | at 10:33:18 A cli app for upgrading Pulsar
Usage: pulsar-upgrade-cli [command]
Available Commands: completion Generate the autocompletion script for the specified shell help Help about any command install install a target version scale scale statefulSet of the cluster
Flags: --burst-limit int client-side default throttling limit (default 100) --debug enable verbose output -h, --help help for pulsar-upgrade-cli --kube-apiserver string the address and the port for the Kubernetes API server --kube-as-group stringArray group to impersonate for the operation, this flag can be repeated to specify multiple groups. --kube-as-user string username to impersonate for the operation
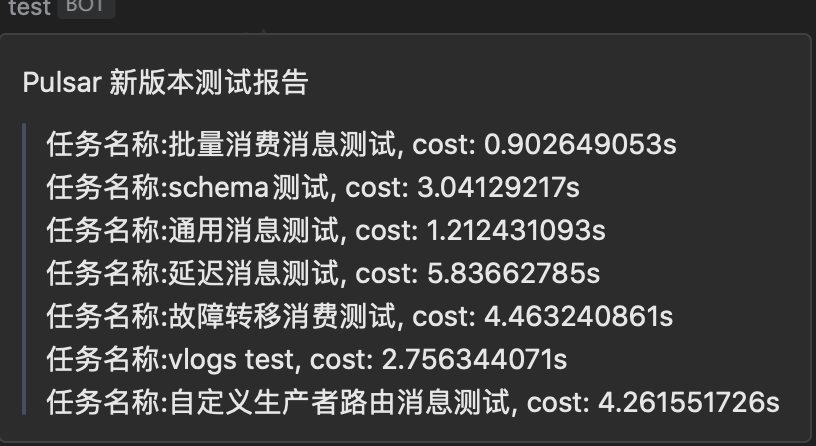
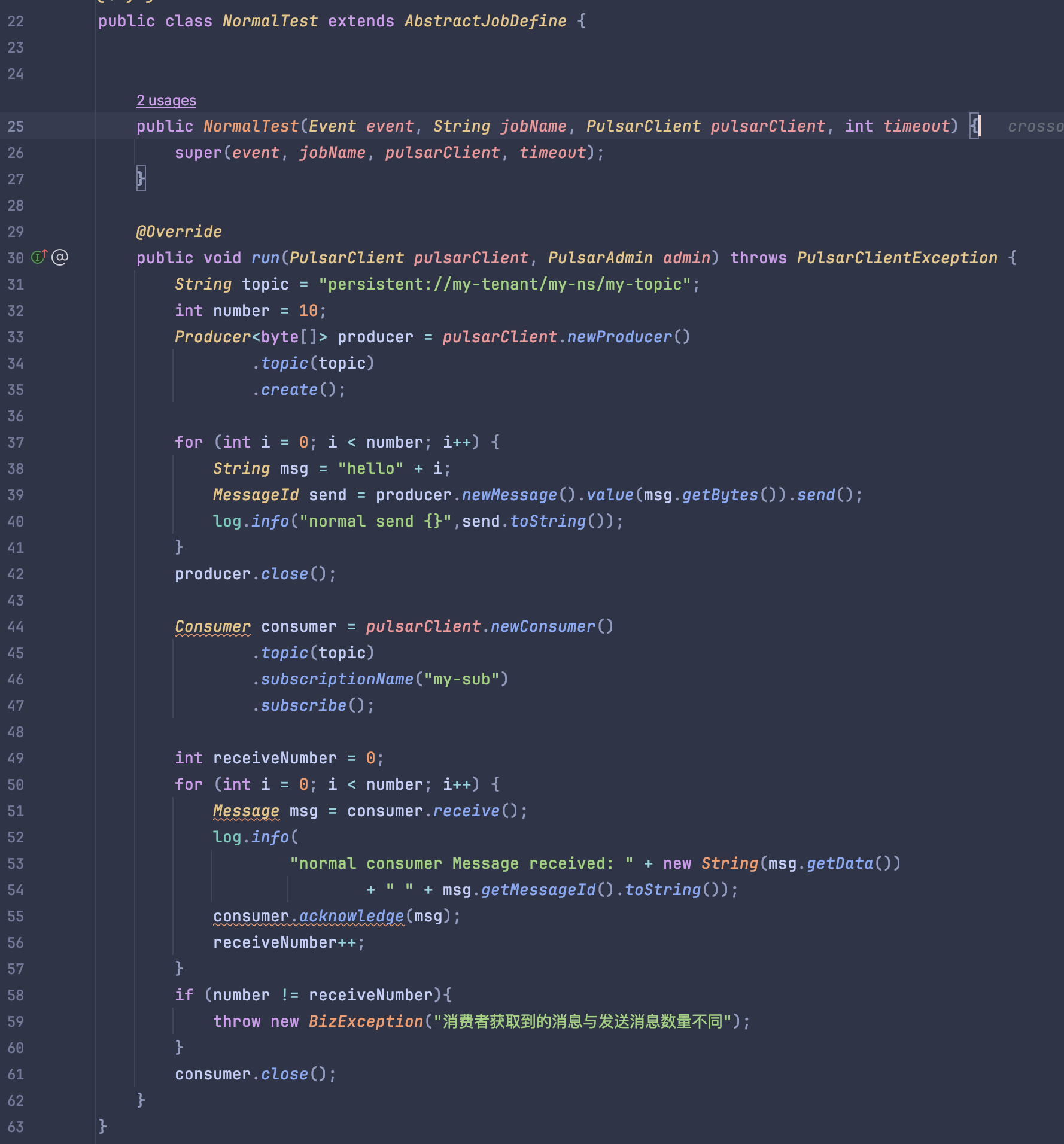
这里我就踩过坑,因为在功能测试里用的是官方的 example 代码进行测试的,自然是没有问题;但业务在实际使用时,使用到了一个 Schema 的场景,并没有在功能测试里覆盖到(官方的测试用例里也没有😂),就导致升级到某个版本后业务功能无法正常使用(虽然用法确实是有问题),但应该在我测试阶段就暴露出来。
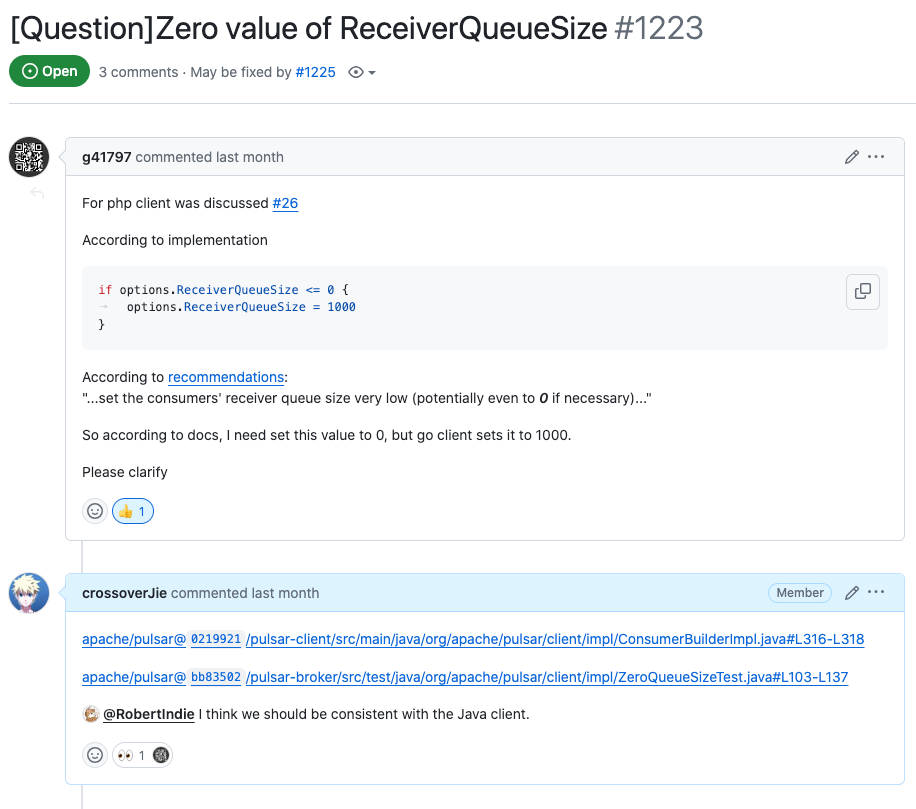
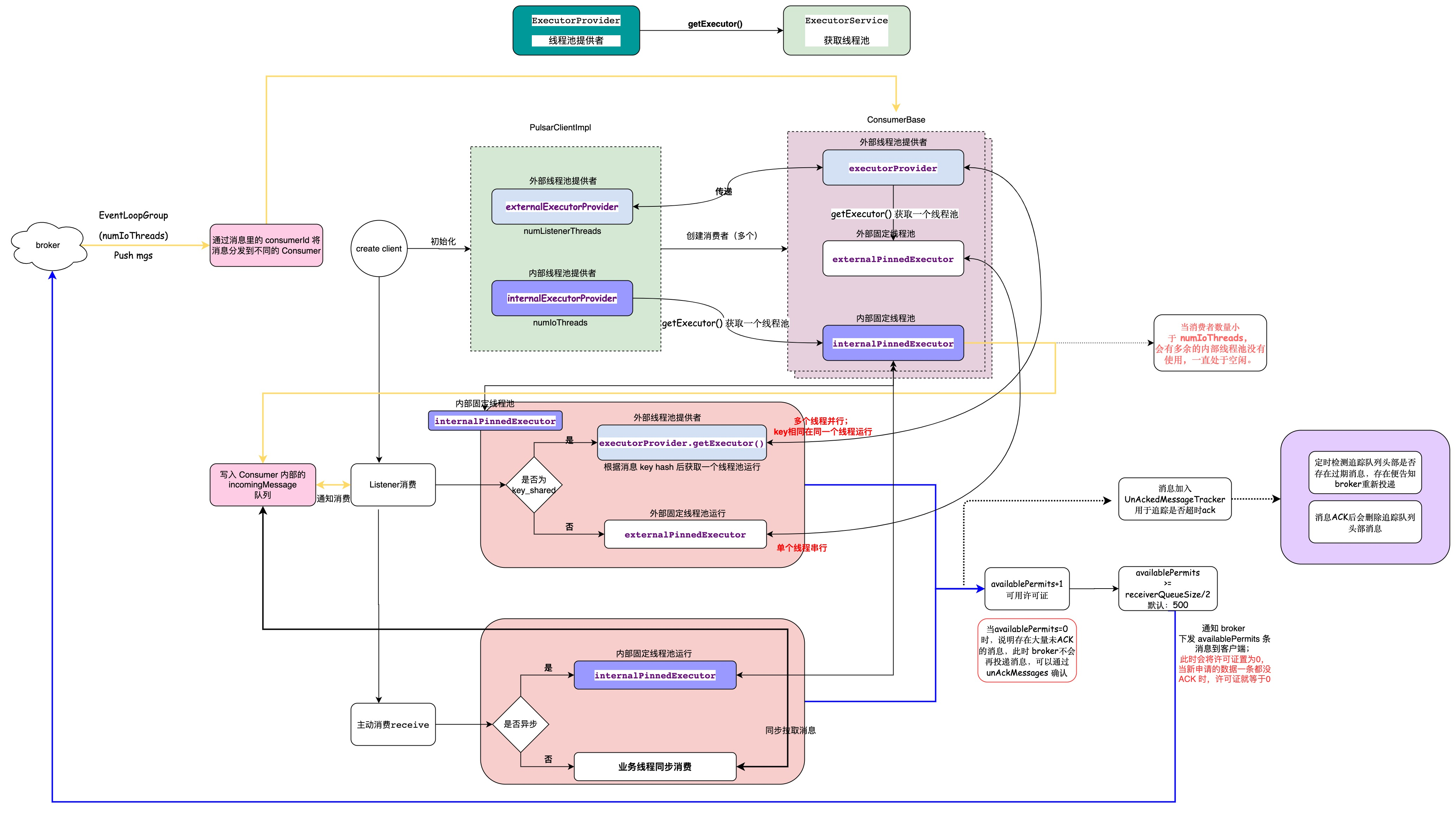
If you’d like to have tight control over message dispatching across consumers, set the consumers’ receiver queue size very low (potentially even to 0 if necessary). Each consumer has a receiver queue that determines how many messages the consumer attempts to fetch at a time. For example, a receiver queue of 1000 (the default) means that the consumer attempts to process 1000 messages from the topic’s backlog upon connection. Setting the receiver queue to 0 essentially means ensuring that each consumer is only doing one thing at a time.
@Override protected CompletableFuture<Message<T>> internalReceiveAsync() { CompletableFuture<Message<T>> future = super.internalReceiveAsync(); if (!future.isDone()) { // We expect the message to be not in the queue yet increaseAvailablePermits(cnx()); } return future; }
// EnableZeroQueueConsumer, if enabled, the ReceiverQueueSize will be 0. // Notice: only non-partitioned topic is supported. // Default is false. EnableZeroQueueConsumer bool
func(z *zeroQueueConsumer) Receive(ctx context.Context) (Message, error) { if state := z.pc.getConsumerState(); state == consumerClosed || state == consumerClosing { z.log.WithField("state", state).Error("Failed to ack by closing or closed consumer") returnnil, errors.New("consumer state is closed") } z.Lock() defer z.Unlock() z.pc.availablePermits.inc() for { select { case <-z.closeCh: returnnil, newError(ConsumerClosed, "consumer closed") case cm, ok := <-z.messageCh: if !ok { returnnil, newError(ConsumerClosed, "consumer closed") } return cm.Message, nil case <-ctx.Done(): returnnil, ctx.Err() } }
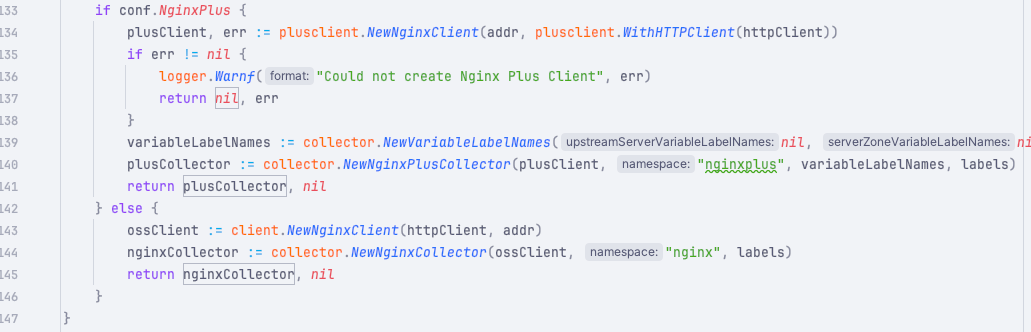
nginx_plus = false # Path to the PEM encoded CA certificate file used to validate the servers SSL certificate. ssl_ca_cert = '' # Path to the PEM encoded client certificate file to use when connecting to the server. ssl_client_cert = '' # Path to the PEM encoded client certificate key file to use when connecting to the server. ssl_client_key = '' # Perform SSL certificate verification. ssl_verify = false timeout = '5s'
然后将这个 toml 里的配置转换为一个 struct。
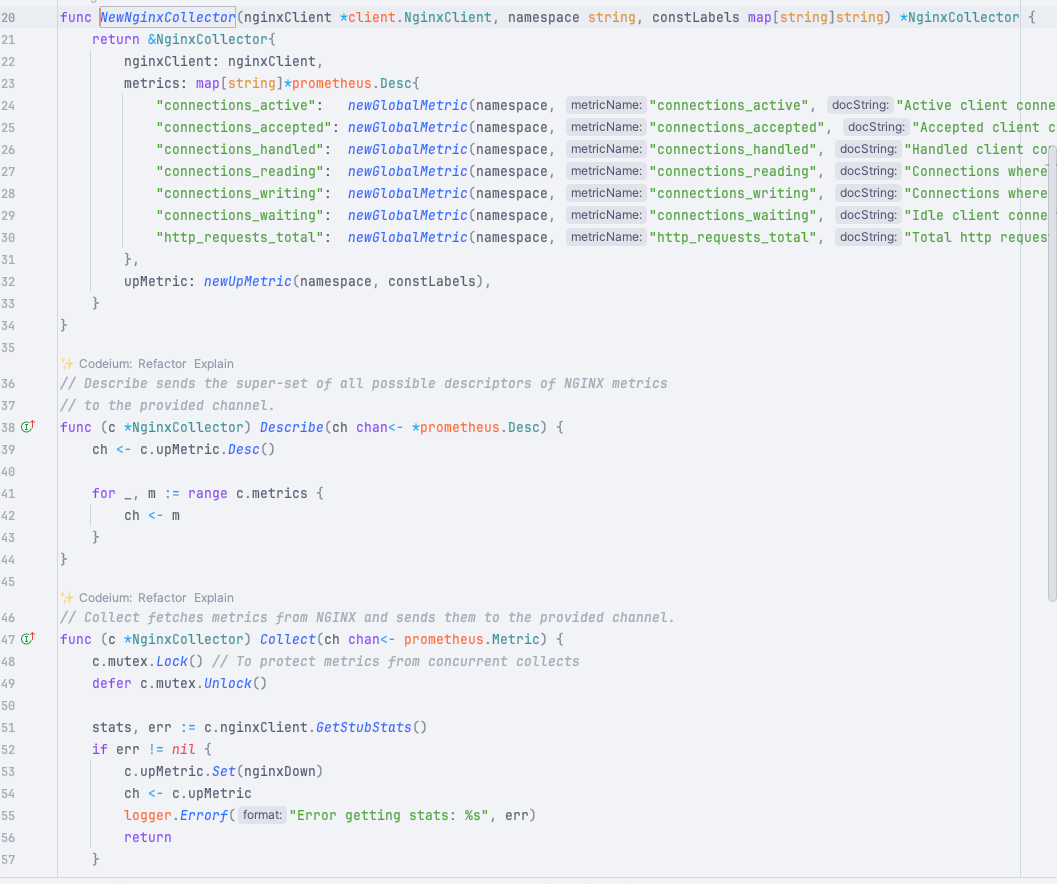
在 cprobe 中有一个核心的接口:
1 2 3 4 5 6
type Plugin interface { // ParseConfig is used to parse config ParseConfig(baseDir string, bs []byte) (any, error) // Scrape is used to scrape metrics, cfg need to be cast specific cfg Scrape(ctx context.Context, target string, cfg any, ss *types.Samples) error }