大模型应用开发必需了解的基本概念 背景AI/LLM 大模型最近几年毋庸置疑的是热度第一,虽然我日常一直在用 AI 提效,但真正使用大模型做一个应用的机会还是少。 最近正好有这么个机会,需要将公司内部的代码 repo 转换为一个 wiki,同时还可以基于项目内容进行对话了解更具体的内容。 实际效果大概和上半年很火的 deepwiki 类似。 而我们是想基于开源的 deepwiki-open进行开发,提供的功能都是类似的。 2025-12-23 AI #AI
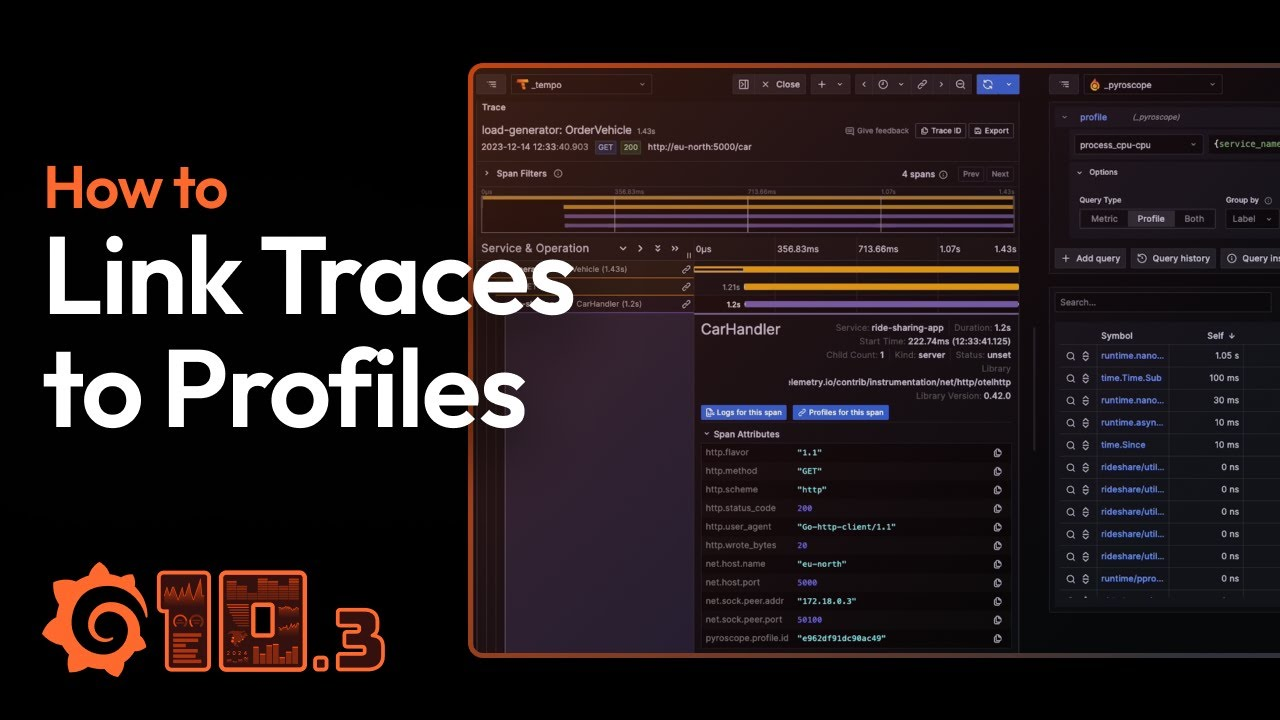
持续剖析超级增强:将 Trace/ Span 和 Profile 整合打通 最近在做持续剖析 Profile 与链路系统打通的工作,就查到了 grafana 在 24 年初写的这篇文章;觉得比较有参考意义,在这里分享给大家。 原文链接:https://grafana.com/blog/2024/02/06/combining-tracing-and-profiling-for-enhanced-observability-introducing-span-profil 2025-11-25 OB > OpenTelemetry #OpenTelemetry
StarRocks 如何监控 SQL StarRocks 监控中有一个很关键的指标,就是针对慢 SQL 的监控。 在 StarRocks 中审计日志记录了所有用户的查询和连接信息,理论上我们只需要对这些日志进行分析就可以得到相关的慢 SQL,高 CPU、高内存的 SQL 信息。 类似于这样的监控界面: 2025-11-12 OB > StarRocks #StarRocks
Git cherry-pick 使用小技巧 背景前段时间我在实现 StarRocks 的一个关于资源限制的特性,由于该功能需要基于最新的 3.5 tag 进行开发,所以我需要需要从 3.5 的 tag 里拉出一个分支(3.5-feature)开发完成后再向上游的 main 分支提交 PR。 2025-09-18 git #cherry-pick
在多语言的分布式系统中如何传递 Trace 信息 背景 前段时间有朋友问我关于 spring cloud 的应用在调用到 Go 的 API 之后出现 Trace 没有串联起来的问题。 完整的调用流程如下: 123456789101112131415┌──────┐ │Client│ └┬─────┘ ┌▽──────────────────┐│SpringCloud Gate 2025-08-13 OpenSource > OpenTelemetry #OpenSource
StarRocks 如何在本地搭建存算分离集群 之前写过一篇 StarRocks 开发环境搭建踩坑指北之存算分离篇讲解如何在本地搭建一个可以 debug 的存算分离版本。 但最近在本地调试一个场景,需要 CN 节点是以集群的方式启动,我还是按照老方法通过 docker 启动 CN,然后 export 端口的方式让 FE 进行绑定。 比如用以下两个命令可以启动两个 CN 节点。 1docker run -p 9060:9060 -p 8040:8 2025-08-01 OB > StarRocks #StarRocks
StarRocks 物化视图创建与刷新全流程解析 最近在为 StarRocks 的物化视图增加多表达式支持的能力,于是便把物化视图(MV)的创建刷新流程完成的捋了一遍。 之前也写过一篇:StarRocks 物化视图刷新流程和原理,主要分析了刷新的流程,以及刷新的条件。 这次从头开始,从 MV 的创建开始来看看 StarRocks 是如何管理物化视图的。 创建物化视图1234567891011CREATEMATERIALIZED VIEW mv_t 2025-06-27 OB #StarRocks
关于 Golang 的错误处理的讨论可以大结局了 原文链接:[ On | No ] syntactic support for error handling 关于 Go 语言最有争论的就是错误处理: 1234x, err := call()if err != nil { // handle err} if err != nil 类似于这样的代码非常多,淹没了其余真正有用的代码。这通常发生在进行大量API 2025-06-05 OB
我的 CodeReview 实战经验 背景Code Review 是大家日常开发过程中很常见的流程,当然也不排除一些团队为了快速上线,只要功能测试没问题就直接省去了 Code Review。 我个人觉得再忙的团队 Code Review 还是很有必要的(甚至可以事后再 Review),好处很多: 跳出个人开发的思维误区,更容易发现问题 增进团队交流,提高整体的技术氛围 团队水平检测器,不管是审核者还是被审核的,review 几次后 2025-05-21 OB #OpenSource
如何在本地打包 StarRocks 发行版 最近我们在使用 StarRocks 的时候碰到了一些小问题: 重启物化视图的时候会导致视图全量刷新,大量消耗资源。 - 修复 PR:https://github.com/StarRocks/starrocks/pull/57371 excluded_refresh_tables 参数与 MV 不在一个数据库的时候,无法生效。 修复 PR:https://github.com/StarRocks 2025-05-12 StarRocks #StarRocks