StarRocks 升级注意事项 前段时间升级了生产环境的 StarRocks,从 3.3.3 升级到了 3.3.9,期间还是踩了不少坑所以在这里记录下。 因为我们的集群使用的是存算分离的版本,也是使用官方提供的 operator 部署在 kubernetes 里的,所以没法按照官方的流程进入虚拟机手动启停对应的服务。 只能使用 operator 提供的方案手动修改对应组件的镜像版本,后续的升级操作交给 operator 去完 2025-03-14 OB #StarRocks
我的 2024 这些年我一直都是按照农历新年来写年终总结的,都说不出正月都是年,前些年一直都比较规律,今年确实是时间超了一些。 主要原因还是年末接了个活,需要在年初上线,导致这段时间都没太多时间写内容。 最近事情终于告一段落后才开始码字。 2025-03-03 OB
StarRocks 开发环境搭建踩坑指北之存算分离篇 前段时间碰到一个 StarRocks 物化视图的 bug: https://github.com/StarRocks/starrocks/issues/55301 但是这个问题只能在存算分离的场景下才能复现,为了找到问题原因我便尝试在本地搭建一个可以 Debug 的存算分离版本。 之前也分享过在本地 Debug StarRocks,不过那是存算一体的版本,而存算分离稍微要复杂一些。 这里提到的本 2025-01-20 OB > StarRocks #StarRocks
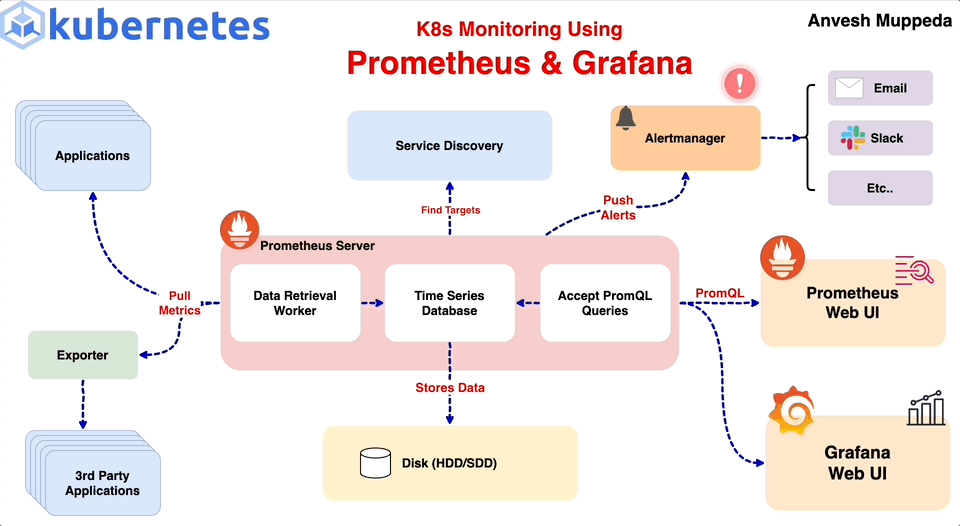
k8s 云原生应用如何接入监控 前段时间有朋友问我如何在 kubernetes 里搭建监控系统,恰好在公司也在维护内部的可观测平台,正好借这个机会整理下目前常见的自建监控方案。 一个完整的监控系统通常包含以下的内容: 指标暴露:将系统内部需要关注的指标暴露出去 指标采集:收集并存储暴露出来的指标 指标展示:以各种图表展示和分析收集到的数据 监控告警:当某些关键指标在一定时间周期内出现异常时,可以及时通知相关人员 对于 k8 2025-01-02 k8s > OB > kubernetes #kubernetes
Istio 安装过程中遇到的坑 安装 Istio最近这段时间一直在做服务网格(Istio)相关的工作,背景是我们准备自建 Istio,首先第一件事情就是要安装。 我这里直接使用官网推荐的 istioctl 进行安装: 123456789101112$ cat <<EOF > ./my-config.yamlapiVersion: install.istio.io/v1alpha1 kind: IstioOpe 2024-12-25 Istio > k8s #Istio
如何在平淡的工作中整理出有价值的简历 今天在 HackNews 上看到一个帖子:你们是否很难回忆起在工作中做了哪些贡献? 我觉得挺多人都有类似的问题,通常都是在需要面试或者内部晋升的时候才开始思考这些问题,这时候在想的话难免会有遗漏。 结合帖子里的回答我整理了以下以下方法。 2024-12-10 OB
如何选择可以搞钱的技术栈 前言之前在公司主要负责可观测性和 Pulsar 消息队列相关的内容,最近系统比较稳定,只需要做日常运维,所以就抽出时间逐步在接触 OLAP 相关的技术栈。 我们用的是 StarRocks,也是目前比较流行的 OLAP 数据库;在接触的这段时间以来,让我越发感觉到选对一个靠谱的技术方向的重要性。 2024-11-26 OB
推荐一些值得学习的开源项目和框架 今天收到球友的问题,让推荐一些值得看的开源项目,觉得 netty 这些太复杂了不太好上手。 确实如此,我们日常常用的 Spring、Netty 确实由于发展了多年,看起来比较头大。 下面我来推荐一些我看过同时觉得不错的项目(几乎都是我参与过的),由易到难,其中也会包含 Java 和 Go 的项目,包含主流的中间件和云原生项目。 2024-11-20 OpenSource #OpenSource
StarRocks 物化视图刷新流程和原理 前段时间给 StarRocks 的物化视图新增了一个特性,那也是我第一次接触 StarRocks,因为完全不熟悉这个数据库,所以很多东西都是从头开始了解概念。 为了能顺利的新增这个特性(具体内容可以见后文),我需要把整个物化视图的流程串联一遍,于是便有了这篇文章。 在开始之前简单了解下物化视图的基本概念: 简单来说,视图和 MySQL 这类传统数据库的概念类似,也是用于解决大量消耗性能的 SQL 2024-11-18 StarRocks #StarRocks
深入理解 StarRocks 的元数据管理 背景最近在排查 starrocks 线上的一个告警日志: 每隔一段时间都会打印 base-table 也就是物化视图的基表被删除了,但其实表还在,也没人去删除;我们就怀疑是否真的表被删除了(可能是 bug)。 与此同时还有物化视图 inactive 的日志,也怀疑如果视图是 inactive 之后会导致业务使用有问题。 为了确认这个日志是否对使用影响,就得需要搞清楚它出现的原因;于是我就着手从日 2024-11-11 StarRocks #StarRocks