对 AI 更友好的代码分割算法分析

背景
因为最近在基于 RAG 对我们的 code repo 做 AI 分析,其中有一个非常核心的流程就是需要将我们的代码库里的源码进行分割,分割之后会作为 chunk 供 RAG 查询;然后再将查询到的 chunk 提交给 LLM 做分析。
目前我们所使用的 deepwiki-open对代码的分析使用的是最通用的 text_splitter:
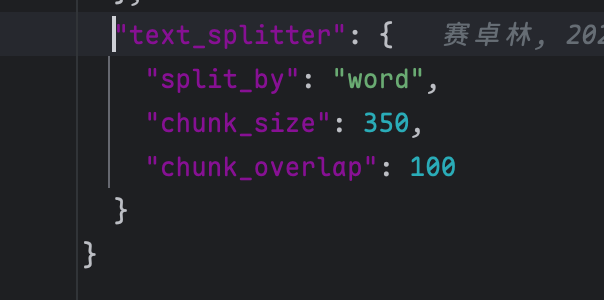
分割方法也是最简单的按照 word 进行分割,普通场景下 text_splitter 够用,但对于我们这种存代码的场景就需要使用特殊的 Spitter 了;主要问题是它不理解语言结构,容易把函数/类等语义单元切断,导致检索召回片段不完整、上下文丢失。
算法对比
1. 基础文本切分
简介: 最原始的方法。不管代码逻辑,直接按字符长度或者空格硬切。就像切西瓜不管瓜瓤结构,每一刀切固定的厚度。
- 优点:简单,适用于所有文本项目
- 缺点:不适合代码项目,经常把一个完整的函数拦腰截断,大模型读起来云里雾里。
代码示例:
1 | |
手搓 Tree-Sitter (参考Claude-context)
1 | |
原本是 TS 写的,核心是使用 tree-sitter 做 AST 分析之后进行拆分,只是会在解析 AST 失败的时候使用 LangChainCodeSplitter 作为兜底。
这部分没有找到现成的开源方案,于是我就按照 ts 代码翻译了一份 Python 的版本:
1 | |
| 方案 | 主要原理 | 代码友好度 | 适合场景 | 主要缺点 |
|---|---|---|---|---|
| 现有:deepwiki-open 的 TextSplitter(split_by=word) | 纯通用文本切分:按 word/长度 + overlap 切块 | 弱 | 快速起步;纯文本/注释类内容较多;对精度要求不高 | 容易把函数/类切断;chunk 语义不完整;对代码检索召回不稳 |
| claude-context,没有 Python 库,得自己实现。 使用了 LangChain CodeTextSplitter 兜底。 |
使用 tree-sitter 解析 AST,支持 chunk_size 和 overlap。 生成 chunk 后再处理是否超过 chunk_size,内存占用大于 code-spitter 相关代码 |
很强 | 多语言代码库 RAG、希望按函数/类分块 | 内存占用大于 code-spitter |
| wangxj03/code-splitter(rust 编写有提供 Python binding库) 参考了 benbrandt/text-splitter & LlamaIndex’s CodeSpiller(提供了 Python 库) |
用 tree-sitter 解析 AST,再按语法节点+ chunk 长度合并。 边遍历边合并,内存占用较小;相关代码。 直接将语法数按照 chunk 分割,没有处理 overlap; |
很强 | 多语言代码库 RAG、希望按函数/类分块 | 依赖 tree-sitter grammar;集成复杂度略高 没有处理 overlap,生成的上下文可能会不连续。 |
| LangChain CodeTextSplitter | 按语言特征分隔符(def/class/function等)切分(部分场景可结构化) 预设了一些语言的关键字。 |
中-强 | 想快速落地、LangChain 生态、主流语言 | 多数实现偏“规则/正则”,复杂嵌套不如 AST 稳 |
| benbrandt/text-splitter(语义/边界优先),rust 编写,有提供 Python binding 库。 | 用 tree-sitter 解析 AST。 | 强 | ||
| LlamaIndex CodeSplitter | 用 tree-sitter 解析 AST。只使用了最大字符分割,没有处理 overlap; | 强 | 没有处理 overlap; |
总结
我们对同一个 Java 源码文件分别使用了 claude-context 和 text-splitter进行了对比。
| 特性 | benbrandt:text-splitter-rust |
claude-context-ts / claude-py-impl |
|---|---|---|
| 行边界对齐 | 极佳。每个 Chunk 都从新行开始,在行末结束。 | 较差。经常在行中间甚至单词中间切断(如 esDO)。 |
| 语法完整性 | 高。尽量保持了方法签名或逻辑块的完整。 | 低。由于是基于字符/Token 硬切,导致代码语义破碎。 |
| 重叠策略 (Overlap) | 有意义的逻辑重叠。在方法交界处进行重叠。 | 机械重叠。简单的滑动窗口,不考虑代码逻辑。 |
| Embedding 质量 | 高。由于没有破碎单词,向量表示的语义更精准。 | 中。存在破碎的单词 |
最后我们选择了 benbrandt:text-splitter-rust 的版本(提供了 Python binding 库)。
但对某个代码 repo 分析的效果与许多因素有关,比如 LLM 大模型质量、Embeding 的质量、提示词是否合理;其中的 Code Splitter 算法只是较小的一个环节。
这类需求随着大模型的迭代也需要常用常新,后续也会继续迭代相关知识。
#Blog
对 AI 更友好的代码分割算法分析
http://crossoverjie.top/2026/01/14/AI/splitter-Algorithm-analyse/