为自己搭建一个分布式 IM 系统二【从查找算法聊起】

前言
最近这段时间确实有点忙,这篇的目录还是在飞机上敲出来了的。
言归正传,上周更新了 cim 第一版:为自己搭建一个分布式 IM(即时通讯) 系统;没想到反响热烈,最高时上了 GitHub Trending Java 版块的首位,一天收到了 300+ 的 star。
现在总共也有 1.3K+ 的 star,有几十个朋友参加了测试,非常感谢大家的支持。
在这过程中也收到一些 bug 反馈,feature 建议;因此这段时间我把一些影响较大的 bug 以及需求比较迫切的 feature 调整了,本次更新的 v1.0.1 版本:
- 客户端超时自动下线。
- 新增
AI模式。 - 聊天记录查询。
- 在线用户前缀模糊匹配。
下面谈下几个比较重点的功能。
客户端超时自动下线 这个功能涉及到客户端和服务端的心跳设计,比较有意思,也踩了几个坑;所以准备留到下次单独来聊。
AI 模式
大家应该还记得这个之前刷爆朋友圈的 估值两个一个亿的 AI 核心代码。
和我这里的场景再合适不过了。
于是我新增了一个命令用于一键开启 AI 模式,使用情况大概如下。

欢迎大家更新源码体验,融资的请私聊我🤣。
聊天记录
聊天记录也是一个比较迫切的功能。

使用命令 :q 关键字 即可查询与个人相关的聊天记录。
这个功能其实比较简单,只需要在消息发送及接收消息时保存即可。
但要考虑的一点是,这个保存消息是 IO 操作,不可避免的会有耗时;需要尽量避免对消息发送、接收产生影响。
异步写入消息
因此我把消息写入的过程异步完成,可以不影响真正的业务。
实现起来也挺简单,就是一个典型的生产者消费者模式。
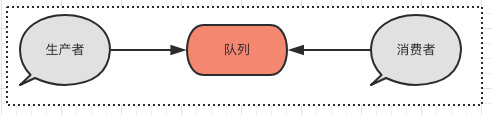
主线程收到消息之后直接写入队列,另外再有一个线程一直源源不断的从队列中取出数据后保存聊天记录。
大概的代码如下:
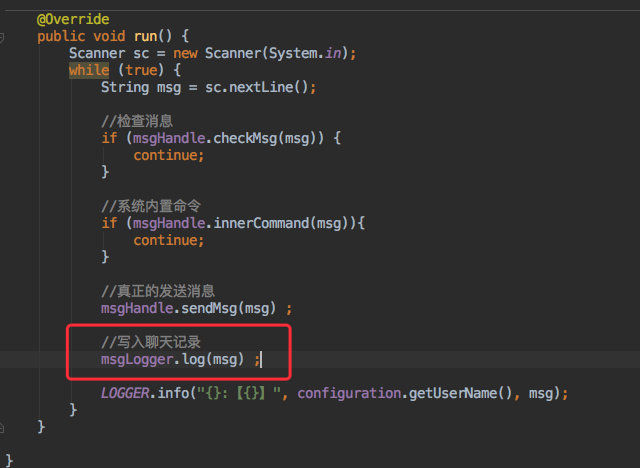
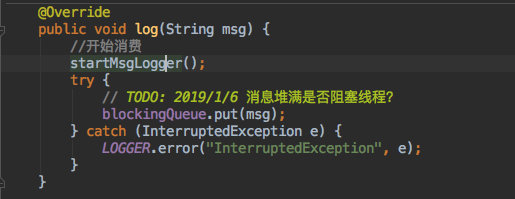
写入消息的同时会把消费消息的线程打开:
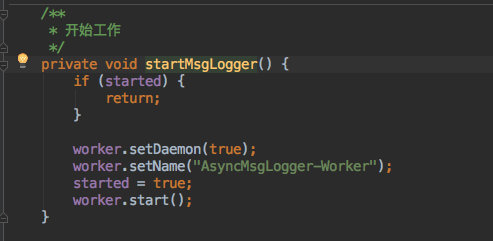
而最终存放消息记录的策略,考虑后还是以最简单的方式存放在客户端,可以降低复杂度。
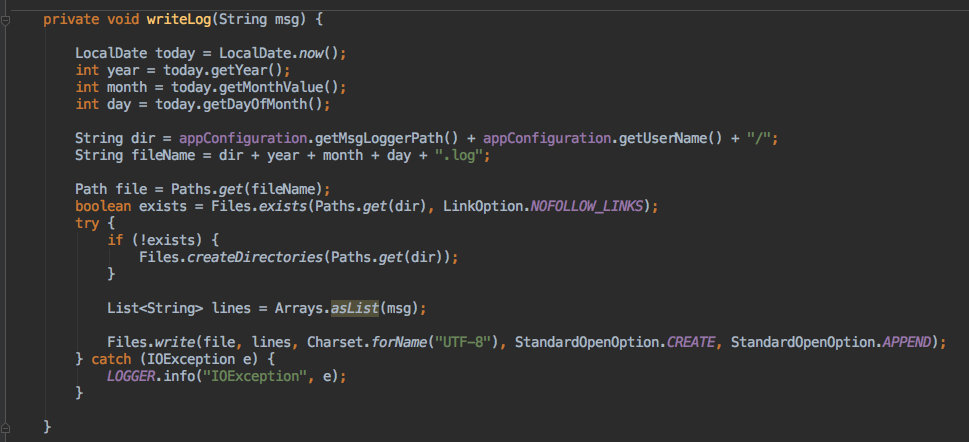
简单来说就是根据当前日期+用户名写入到磁盘里。
当客户端关闭时利用线程中断的方式停止了消费队列的线程。

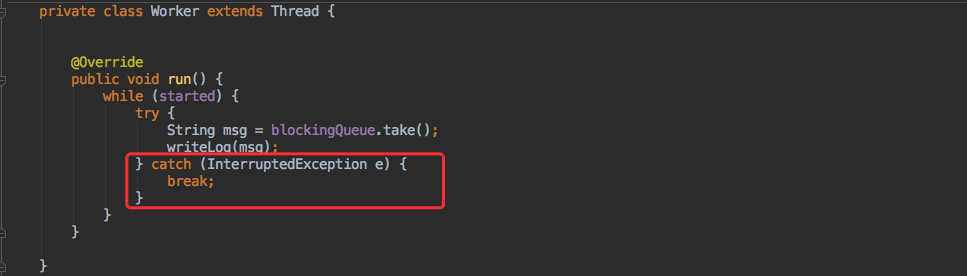
这点的设计其实和 logback 写日志的方式比较类似,感兴趣的可以去翻翻 logback 的源码,更加详细。
回调接口
至于收到其他客户端发来的消息时则是利用之前预留的消息回调接口来写入日志。
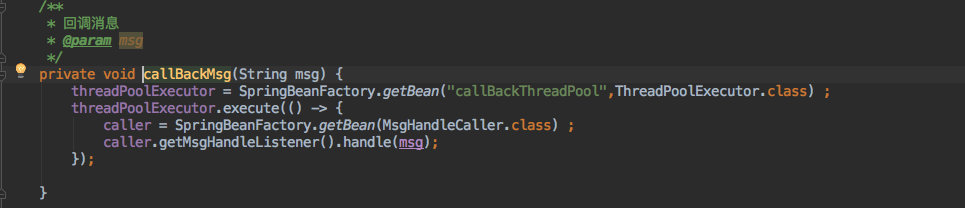
收到消息后会执行自定义的回调接口。
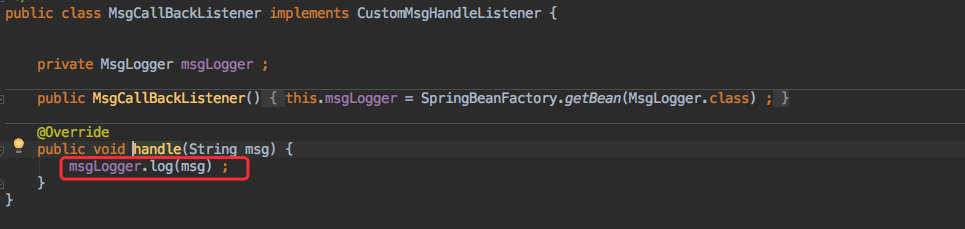
于是在这个回调方法中实现写入逻辑即可,当后续还有其他的消息处理逻辑时也能在这里直接添加。
当处理逻辑增多时最好是改为责任链模式,更加清晰易维护。
查找算法
接下来是本文着重要讨论的一个查找算法,准确的说是一个前缀模糊匹配的算法。
实现的效果如下:

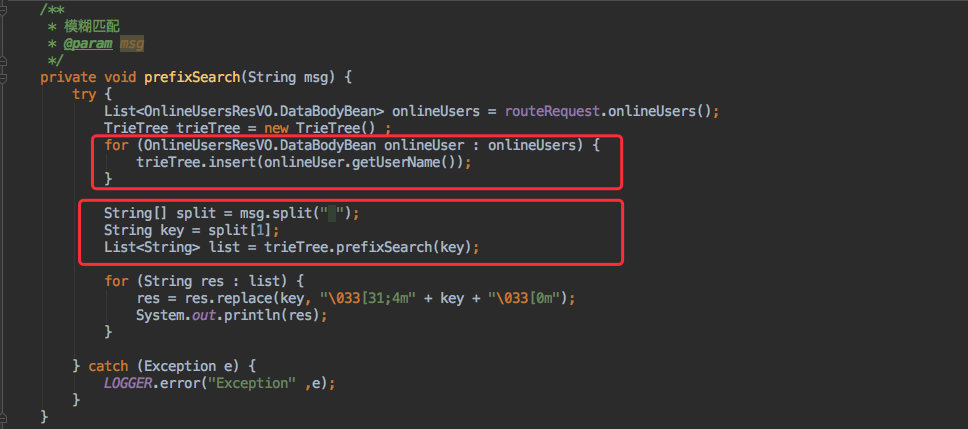
使用命令 :qu prefix 可以按照前缀的方式搜索用户信息。
当然在命令行中其实意义不大,但是在移动端中确是比较有用的。类似于微信按照用户名匹配:
因为后期打算出一个移动端 APP,所以就先把这个功能实现了。
从效果也看得出来:就是按照输入的前缀匹配字符串(目前只支持英文)。
在没有任何限制的条件下最快、最简单的实现方式可以直接把所有的字符串存放在一个容器中 (List、Set),查询时则挨个遍历;利用 String.startsWith("prefix") 进行匹配。
但这样会有几个问题:
- 存储资源比较浪费,不管是 list 还是 Set 都会有额外的损耗。
- 查询效率较低,需要遍历集合后再遍历字符串的
char数组(String.startsWith的实现方式)。
字典树
基于以上的问题我们可以考虑下:
假设我需要存放 java,javascript,jsp,php 这些字符串时在 ArrayList 中会怎么存放?
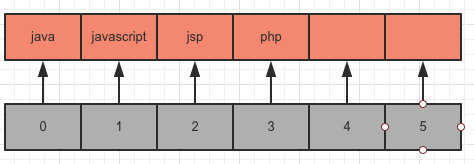
很明显,会是这样完整的存放在一个数组中;同时这个数组还可能存在浪费,没有全部使用完。
但其实仔细观察这些数据会发现有一些共同特点,比如 java,javascript 有共同的前缀 java;和 jsp 有共同的前缀 j。
那是否可以把这些前缀利用起来呢?这样就可以少存储一份。
比如写入 java,javascript 这两个字符串时存放的结构如下:
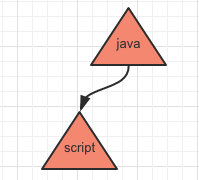
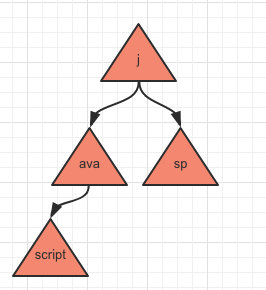
当再存入一个 jsp 时:
最后再存入 jsf 时:
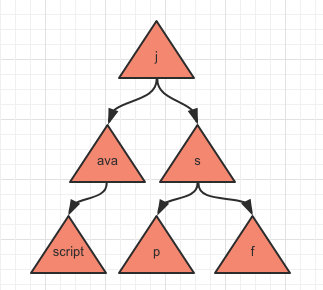
相信大家应该已经看明白了,按照这样的存储方式可以节省很多内存,同时查询效率也比较高。
比如查询以 jav 开头的数据,只需要从头结点 j 开始往下查询,最后会查询到 ava 以及 script 这两个个结点,所以整个查询路径所经历的字符拼起来就是查询到的结果java+javascript。
如果以 b 开头进行查询,那第一步就会直接返回,这样比在 list 中的效率高很多。
但这个图还不完善,因为不知道查询到啥时候算是匹配到了一个之前写入的字符串。
比如在上图中怎么知道
j+ava是一个我们之前写入的java这个字符呢。
因此我们需要对这种是一个完整字符串的数据打上一个标记:
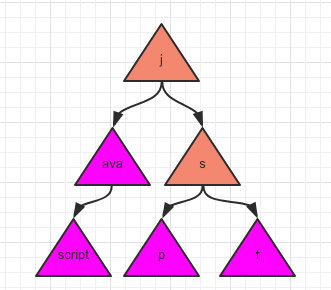
比如这样,我们将 ava、script、p、f 这几个节点都换一个颜色表示。表明查询到这个字符时就算是匹配到了一个结果。
而查到 s 这个字符颜色不对,代表还需要继续往下查。
比如输入关键字 js 进行匹配时,当它的查询路径走到 s 这里时判断到 s 的颜色不对,所以不会把 js 作为一个匹配结果。而是继续往下查,发现有两个子节点 p、f 颜色都正确,于是把查询的路径 jsp 和 jsf 都作为一个匹配结果。
而只输入 j,则会把下面所有有色的字符拼起来作为结果集合。
这其实就一个典型的字典树。
具体实现
下面则是具体的代码实现,其实算法不像是实现一个业务功能这样好用文字分析;具体还是看源码多调试就明白了。
谈下几个重点的地方吧:
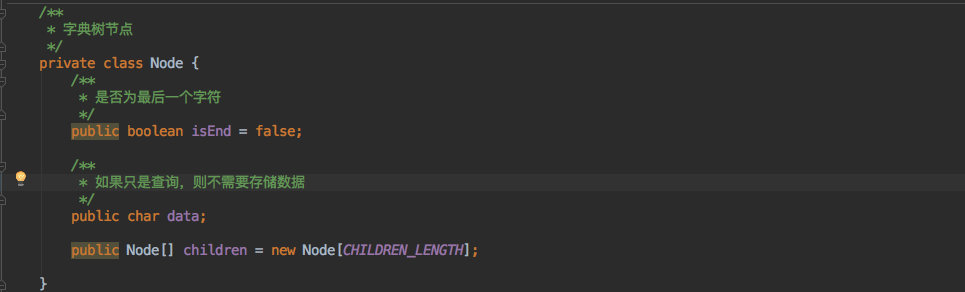
字典树的节点实现,其中的 isEnd 相当于图中的上色。
利用一个 Node[] children 来存放子节点。
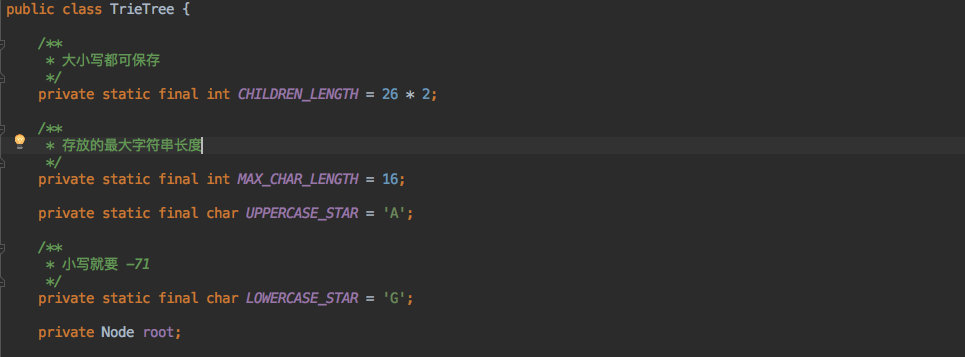
为了可以区分大小写查询,所以子节点的长度相当于是 26*2。
写入数据
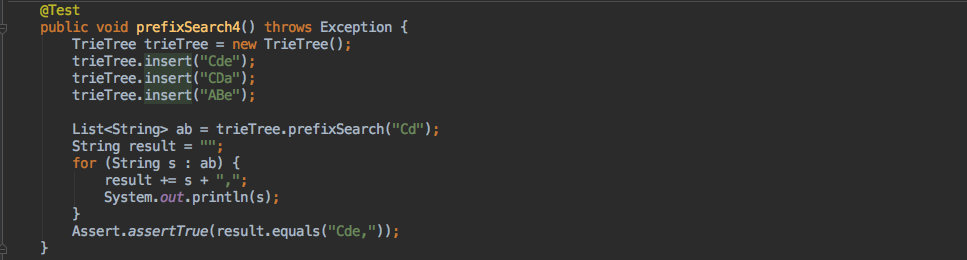
这里以一个单测为例,写入了三个字符串,那最终形成的数据结构如下:
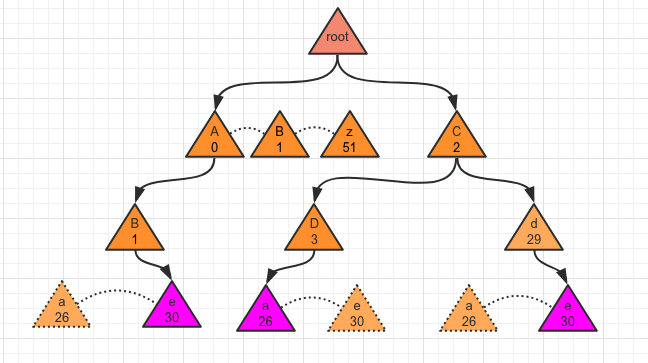
图中有与上图有几点不同:
- 每个节点都是一个字符,这样树的高度最高为52。
- 每个节点的子节点都是长度为 52 的数组;所以可以利用数组的下标表示他代表的字符值。比如 0 就是大 A,26 则是小 a,以此类推。
- 有点类似于之前提到的布隆过滤器,可以节省内存。
debug 时也能看出符合上图的数据结构:
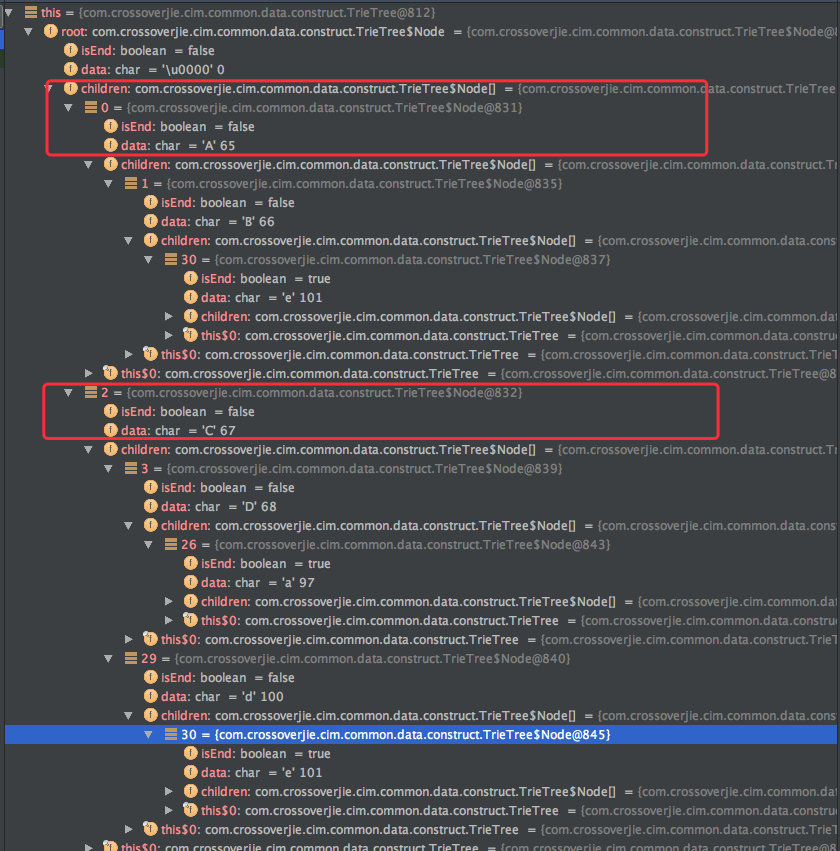
所以真正的写入步骤如下:
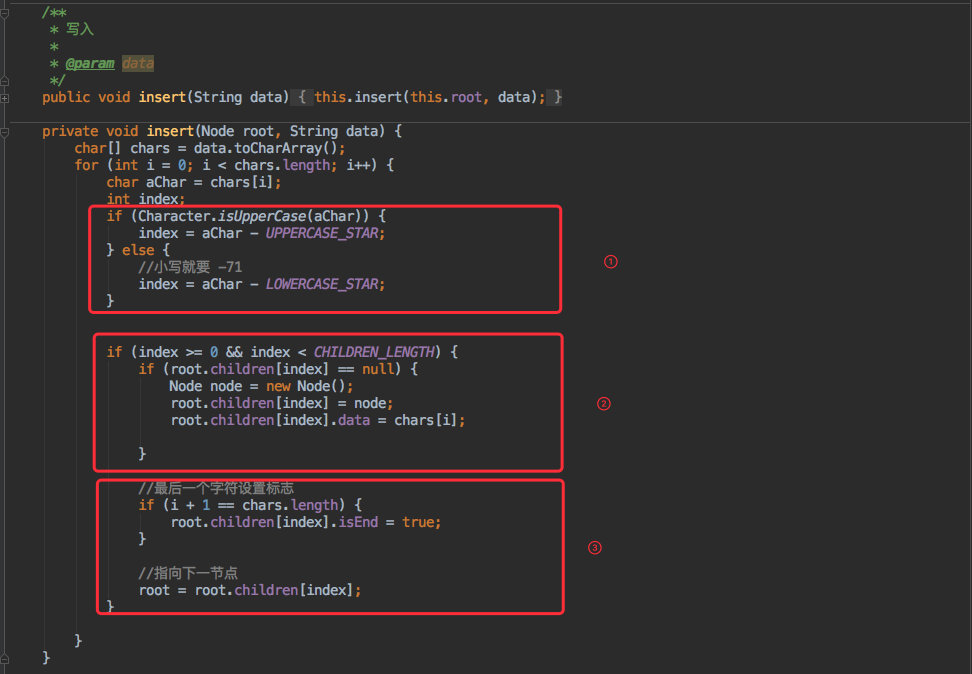
- 把字符串拆分为 char 数组,并判断大小写计算它所存放在数组中的位置
index。 - 将当前节点的子节点数组的 index 处新增一个节点。
- 如果是最后一个字符就将新增的节点置为最后一个节点,也就是上文的改变节点颜色。
- 最后将当前节点指向下一个节点方便继续写入。
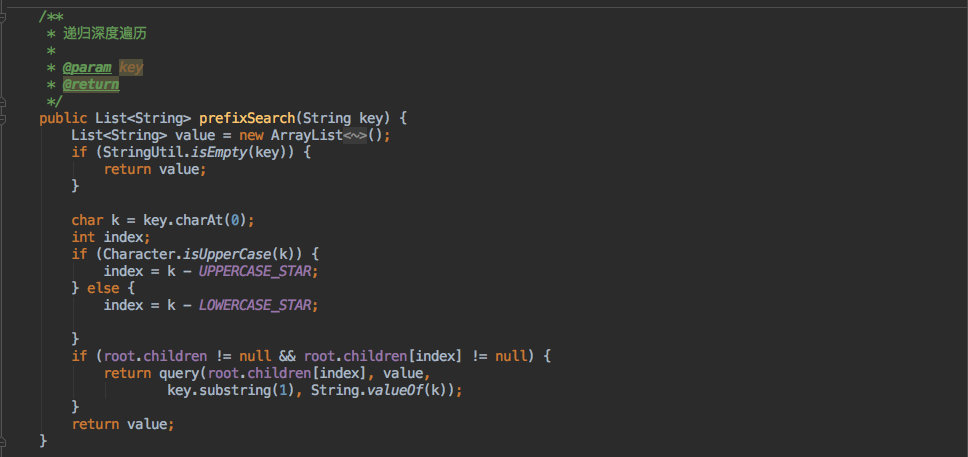
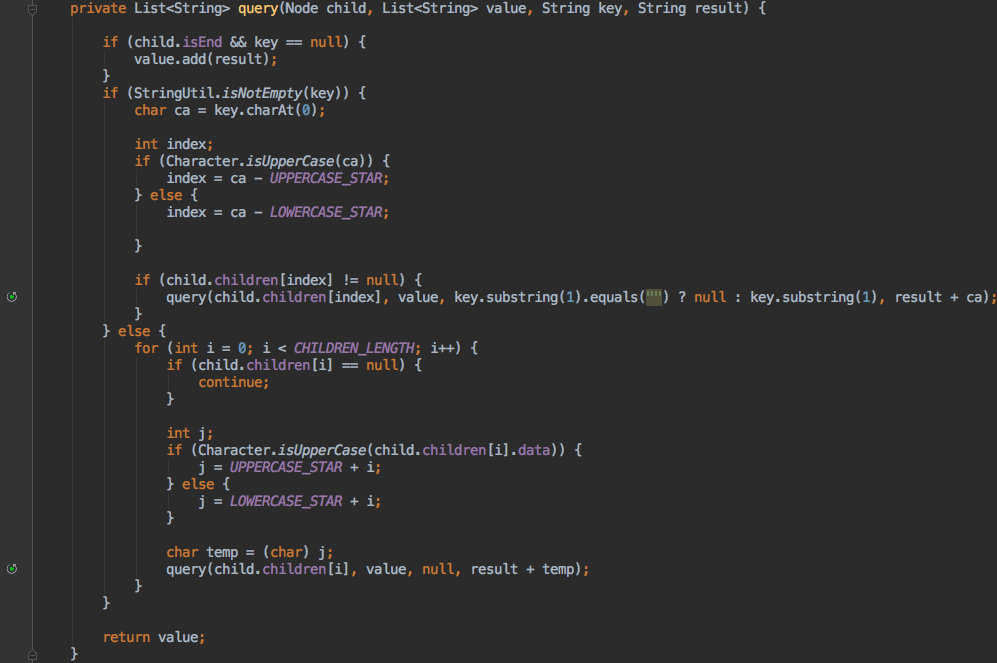
查询总的来说要麻烦一些,其实就是对树进行深度遍历;最终的思想看图就能明白。
所以在 cim 中进行模糊匹配时就用到了这个结构。
字典树的源码在此处:
其实利用这个结构还能实现判断某个前缀的单词是否在某堆数据里、某个前缀的单词出现的次数等。
总结
目前 cim 还在火热内测中(虽然群里只有20几人),感兴趣的朋友可以私聊我拉你入伙☺️

再没有新的 BUG 产生前会着重把这些功能完成了,不出意外下周更新 cim 的心跳重连等机制。
完整源码:
https://github.com/crossoverJie/cim
如果这篇对你有所帮助还请不吝转发。