sbc(五)Hystrix-服务容错与保护

前言
看过 应用限流的朋友应该知道,限流的根本目的就是为了保障服务的高可用。
本次再借助SpringCloud中的集成的Hystrix组件来谈谈服务容错。
其实产生某项需求的原因都是为了解决某个需求。当我们将应用进行分布式模块部署之后,各个模块之间通过远程调用的方式进行交互(RPC)。拿我们平时最常见的下单买商品来说,点击下单按钮的一瞬间可能会向发送的请求包含:
- 请求订单系统创建订单。
- 请求库存系统扣除库存。
- 请求用户系统更新用户交易记录。
这其中的每一步都有可能因为网络、资源、服务器等原因造成延迟响应甚至是调用失败。当后面的请求源源不断的过来时延迟的资源也没有的到释放,这样的堆积很有可能把其中一个模块拖垮,其中的依赖关系又有可能把整个调用链中的应用Over最后导致整个系统不可能。这样就会产生一种现象:雪崩效应。
之前讲到的限流也能起到一定的保护作用,但还远远不够。我们需要从各个方面来保障服务的高可用。
比如:
- 超时重试。
- 断路器模式。
- 服务降级。
等各个方面来保障。
使用Hystrix
SpringCloud中已经为我们集成了Netflix开源的Hystrix框架,使用该框架可以很好的帮我们做到服务容错。
Hystrix简介
下面是一张官方的流程图:
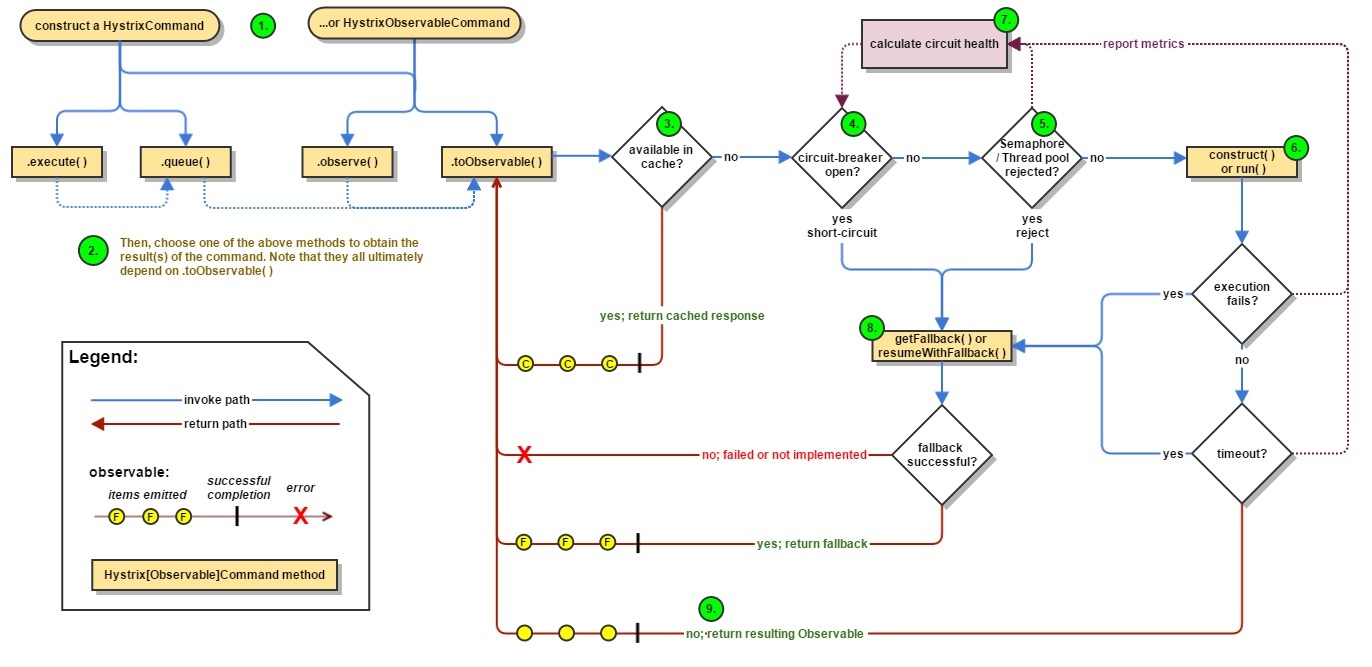
简单介绍下:
在远程调用时,将请求封装到HystrixCommand进行同步或是异步调用,在调用过程中判断熔断器是否打开、线程池或是信号量是否饱和、执行过程中是否抛出异常,如果是的话就会进入回退逻辑。并且整个过程中都会收集运行状态来控制断路器的状态。
不但如此该框架还拥有自我恢复功能,当断路器打开后,每次请求都会进入回退逻辑。当我们的应用恢复正常后也不能再进入回退逻辑吧。
所以hystrix会在断路器打开后的一定时间将请求发送到服务提供者,如果正常响应就关闭断路器,反之则继续打开,这样就能很灵活的自我修复了。
Feign整合Hystrix
在之前的章节中已经使用Feign来进行声明式调用了,并且在实际开发中也是如此,所以这次我们就直接用Feign来整合Hystrix。
使用了项目原有的sbc-user,sbc-order来进行演示,调用关系如下图:
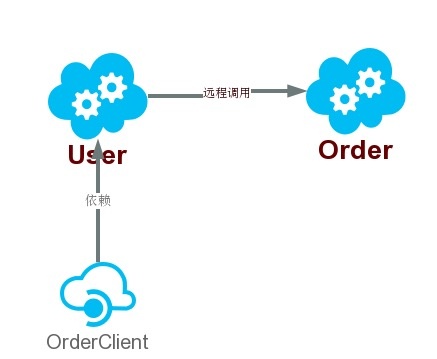
User应用通过Order提供出来的order-client依赖调用了Order中的创建订单服务。
其中主要修改的就是order-client,在之前的OrderServiceClient接口中增加了以下注解:
1 |
|
由于Feign已经默认整合了Hystrix所以不需要再额外加入依赖。
服务降级
对应的@FeignClient中的fallback属性则是服务容错中很关键的服务降级的具体实现,来看看OrderServiceFallBack类:
1 | public class OrderServiceFallBack implements OrderServiceClient { |
该类实现了OrderServiceClient接口,可以很明显的看出其中的getOrderNo()方法就是服务降级时所触发的逻辑。
光有实现还不够,我们需要将改类加入到Spring中管理起来。这样上文中@FeignClient的configuration属性就起到作用了,来看看对应的OrderConfig的代码:
1 |
|
其中new OrderServiceFallBack()并用了@Bean注解,等同于:
1 | <bean id="orderServiceFallBack" class="com.crossoverJie.order.feign.config.OrderServiceFallBack"> |
这样每当请求失败就会执行回退逻辑,如下图: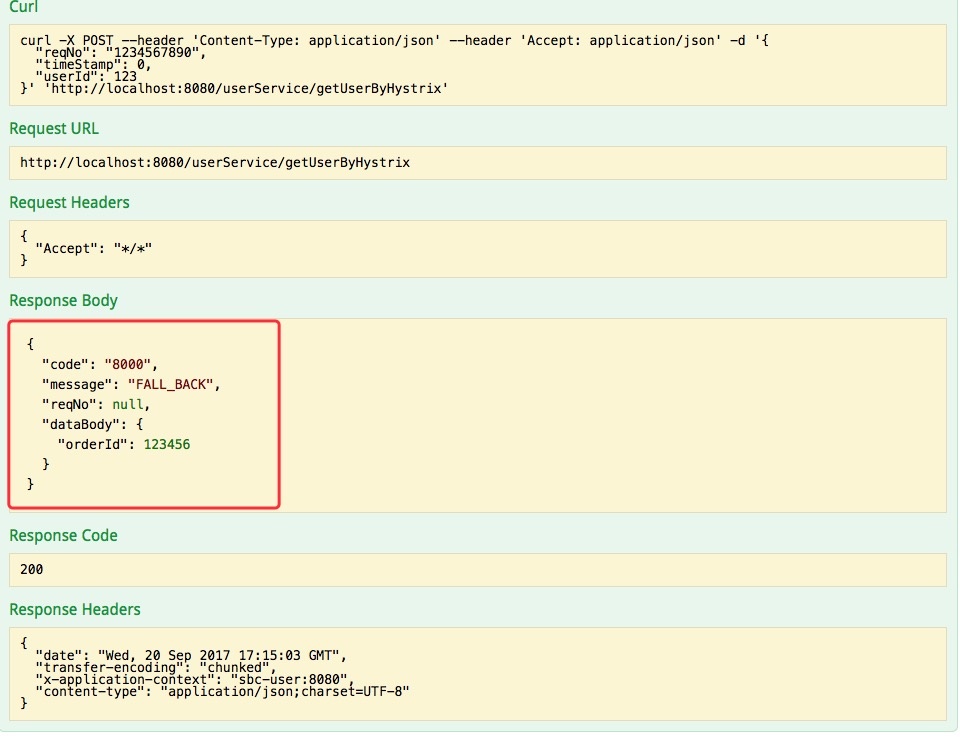
值得注意的是即便是执行了回退逻辑断路器也不一定打开了,我们可以通过应用的health端点来查看Hystrix的状态。
ps:想要查看该端点需要加入以下依赖:
1 | <dependency> |
就拿刚才的例子来说,先关闭Order应用,在Swagger访问下面这个接口,肯定是会进入回退逻辑:
1 |
|
查看health端点:
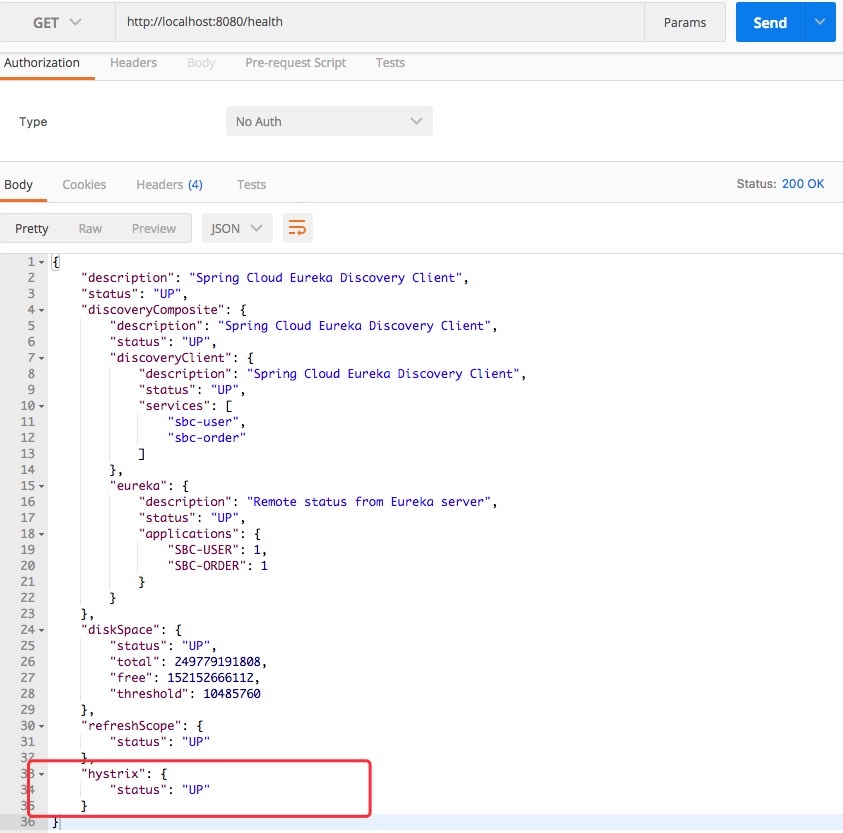
发现Hystrix的状态依然是UP状态,表明当前断路器并没有打开。
反复调用多次接口之后再次查看health端点: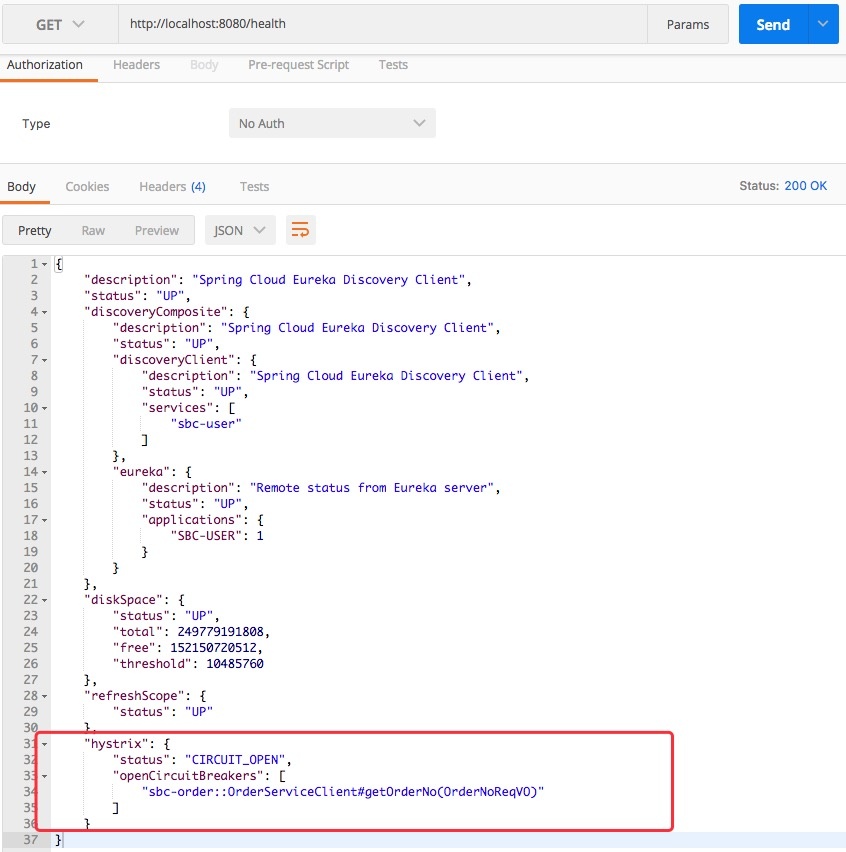
发现这个时候断路器已经打开了。
这是因为断路器只有在达到了一定的失败阈值之后才会打开。
输出异常
进入回退逻辑之后还不算完,大部分场景我们都需要记录为什么回退,也就是具体的异常。这些信息对我们后续的系统监控,应用调优也有很大帮助。
实现起来也很简单:
上文中在@FeignClient注解中加入的fallbackFactory = OrderServiceFallbackFactory.class属性则是用于处理回退逻辑以及包含异常信息:
1 | /** |
代码很简单,实现了FallbackFactory接口中的create()方法,该方法的入参就是异常信息,可以按照我们的需要自行处理,后面则是和之前一样的回退处理。
2017-09-21 13:22:30.307 ERROR 27838 --- [rix-sbc-order-1] c.c.o.f.f.OrderServiceFallbackFactory : fallback:java.lang.RuntimeException: com.netflix.client.ClientException: Load balancer does not have available server for client: sbc-order 。
Note:
fallbackFactory和fallback属性不可共用。
Hystrix监控
Hystrix还自带了一套监控组件,只要依赖了spring-boot-starter-actuator即可通过/hystrix.stream端点来获得监控信息。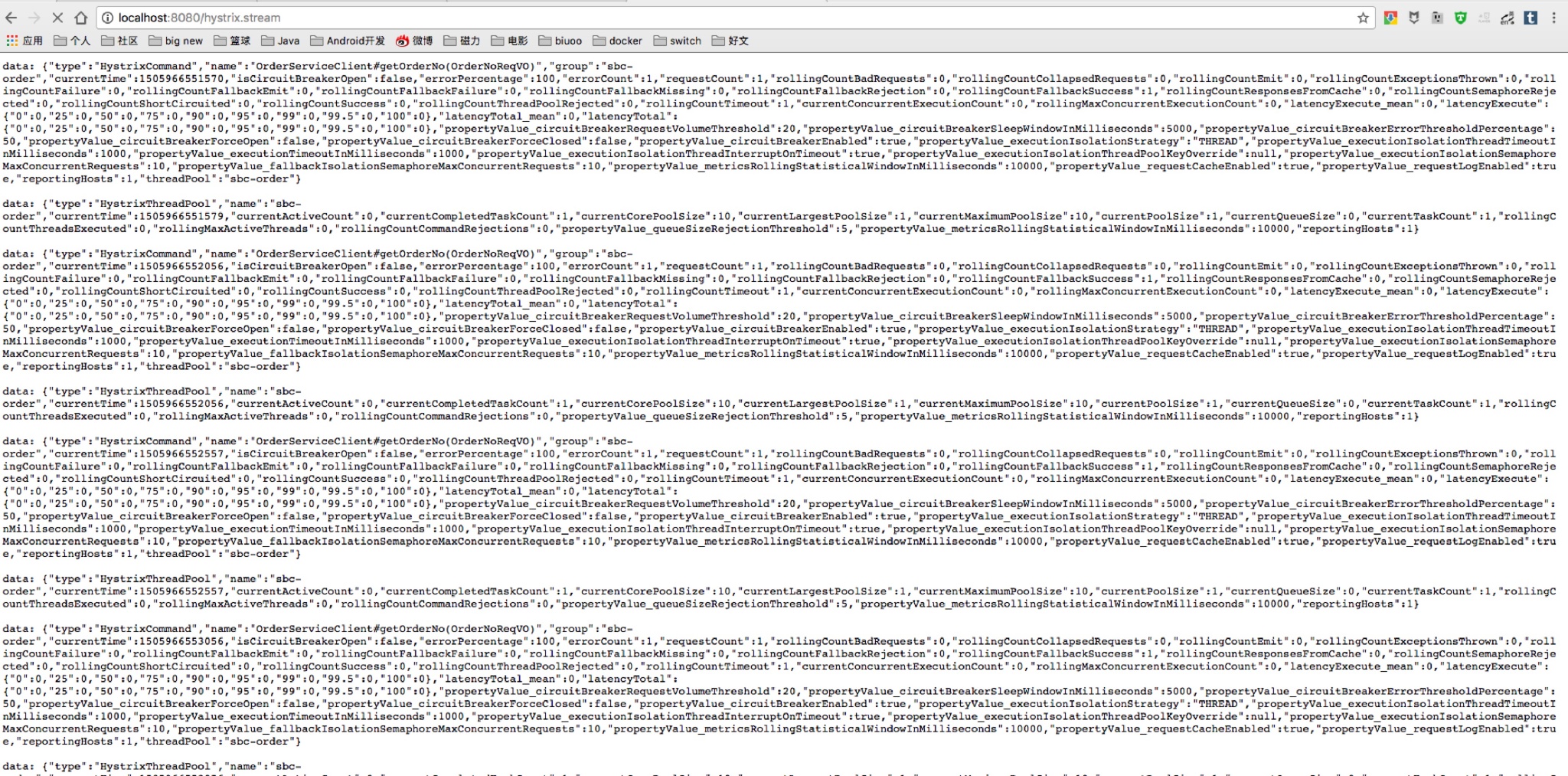
冰冷的数据肯定没有实时的图表来的直观,所以Hystrix也自带Dashboard。
Hystrix与Turbine聚合监控
为此我们新建了一个应用sbc-hystrix-turbine来显示hystrix-dashboard。
目录结构和普通的springboot应用没有差异,看看主类:
1 | //开启EnableTurbine |
- 其中使用
@EnableHystrixDashboard开启Dashboard @EnableTurbine开启Turbine支持。
以上这些注解需要以下这些依赖:
1 | <dependency> |
实际项目中,我们的应用都是多节点部署以达到高可用的目的,单个监控显然不现实,所以需要使用Turbine来进行聚合监控。
关键的application.properties配置文件:
1 | # 项目配置 |
其中turbine.appConfig配置我们需要监控的应用,这样当多节点部署的时候就非常方便了(同一个应用的多个节点spring.application.name值是相同的)。
将该应用启动访问http://ip:port/hystrix.stream:
由于我们的turbine和Dashboard是一个应用所以输入http://localhost:8282/turbine.stream即可。
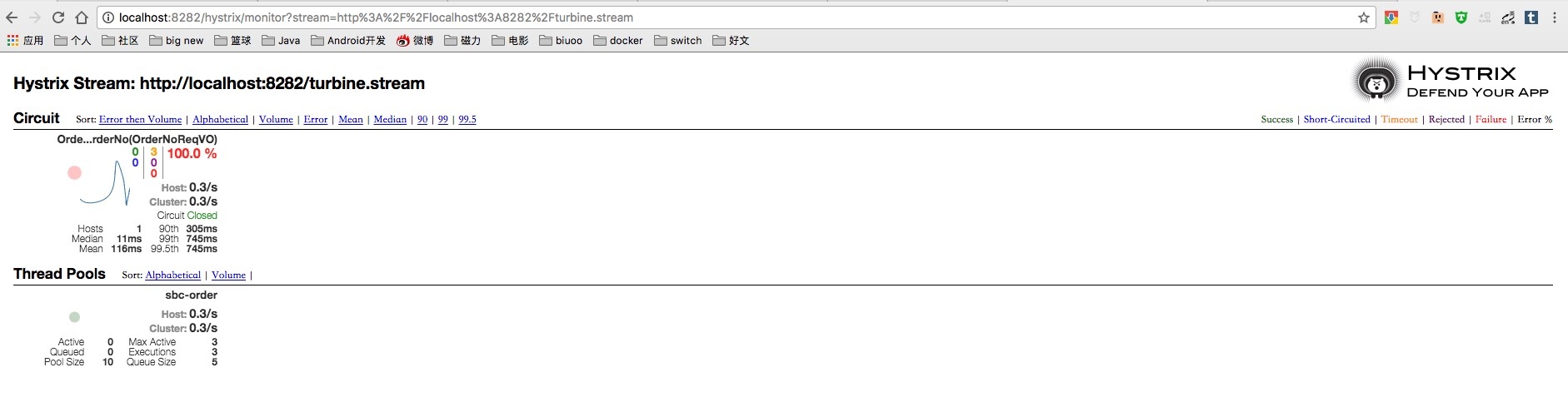
详细指标如官方描述: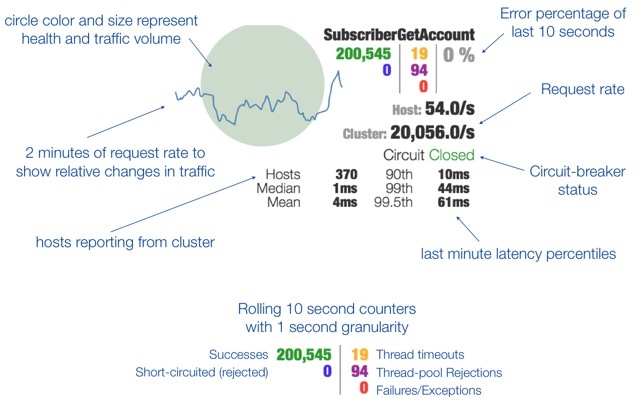
通过该面板我们就可以及时的了解到应用当前的各个状态,如果再加上一些报警措施就能帮我们及时的响应生产问题。
总结
服务容错的整个还是比较大的,博主也是摸着石头过河,关于本次的Hystrix只是一个入门版,后面会持续分析它的线程隔离、信号量隔离等原理。