一次线上问题排查所引发的思考

前言
之前或多或少分享过一些内存模型、对象创建之类的内容,其实大部分人看完都是懵懵懂懂,也不知道这些的实际意义。
直到有一天你会碰到线上奇奇怪怪的问题,如:
- 线程执行一个任务迟迟没有返回,应用假死。
- 接口响应缓慢,甚至请求超时。
- CPU 高负载运行。
这类问题并不像一个空指针、数组越界这样明显好查,这时就需要刚才提到的内存模型、对象创建、线程等相关知识结合在一起来排查问题了。
正好这次借助之前的一次生产问题来聊聊如何排查和解决问题。
生产现象
首先看看问题的背景吧:
我这其实是一个定时任务,在固定的时间会开启 N 个线程并发的从 Redis 中获取数据进行运算。
业务逻辑非常简单,但应用一般涉及到多线程之后再简单的事情都要小心对待。
果不其然这次就出问题了。
现象:原本只需要执行几分钟的任务执行了几个小时都没退出。翻遍了所有的日志都没找到异常。
于是便开始定位问题之路。
定位问题
既然没办法直接从日志中发现异常,那就只能看看应用到底在干嘛了。
最常见的工具就是 JDK 自带的那一套。
这次我使用了 jstack 来查看线程的执行情况,它的作用其实就是 dump 当前的线程堆栈。
当然在 dump 之前是需要知道我应用的 pid 的,可以使用 jps -v 这样的方式列出所有的 Java 进程。
当然如果知道关键字的话直接使用 ps aux|grep java 也是可以的。
拿到 pid=1523 了之后就可以利用 jstack 1523 > 1523.log 这样的方式将 dump 文件输出到日志文件中。
如果应用简单不复杂,线程这些也比较少其实可以直接打开查看。
但复杂的应用导出来的日志文件也比较大还是建议用专业的分析工具。
我这里的日志比较少直接打开就可以了。
因为我清楚知道应用中开启的线程名称,所以直接根据线程名就可以在日志中找到相关的堆栈:
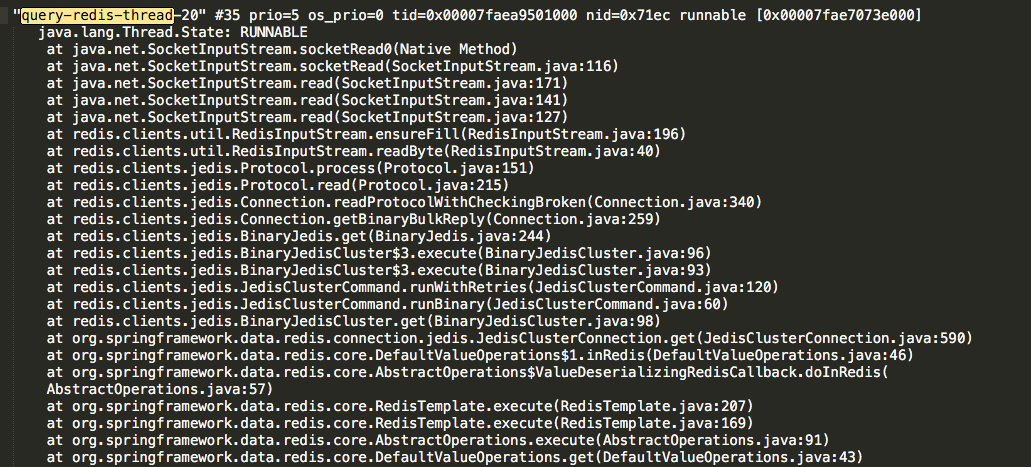
所以通常建议大家线程名字给的有意义,在排查问题时很有必要。
其实其他几个线程都和这里的堆栈类似,很明显的看出都是在做 Redis 连接。
于是我登录 Redis 查看了当前的连接数,发现已经非常高了。
这样 Redis 的响应自然也就变慢了。
接着利用 jps -v 列出了当前所以在跑的 Java 进程,果不其然有好几个应用都在查询 Redis,而且都是并发连接,问题自然就找到了。
解决办法
所以问题的主要原因是:大量的应用并发查询 Redis,导致 Redis 的性能降低。
既然找到了问题,那如何解决呢?
- 减少同时查询 Redis 的应用,分开时段降低 Redis 的压力。
- 将 Redis 复制几个集群,各个应用分开查询。但是这样会涉及到数据的同步等运维操作,或者由程序了进行同步也会增加复杂度。
目前我们选择的是第一个方案,效果很明显。
本地模拟
上文介绍的是线程相关问题,现在来分析下内存的问题。
以这个类为例:
1 | public class HeapOOM { |
启动参数如下:
1 | -Xms20m |
为了更快的突出内存问题将堆的最大内存固定在 20M,同时在 JVM 出现 OOM 的时候自动 dump 内存到 /Users/xx/Documents(不配路径则会生成在当前目录)。
执行之后果不其然出现了异常:
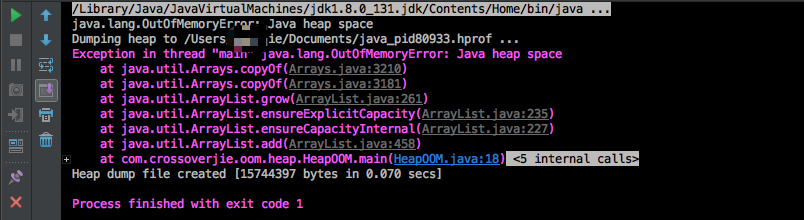
同时对应的内存 dump 文件也生成了。
内存分析
这时就需要相应的工具进行分析了,最常用的自然就是 MAT 了。
我试了一个在线工具也不错(文件大了就不适合了):
上传刚才生成的内存文件之后:
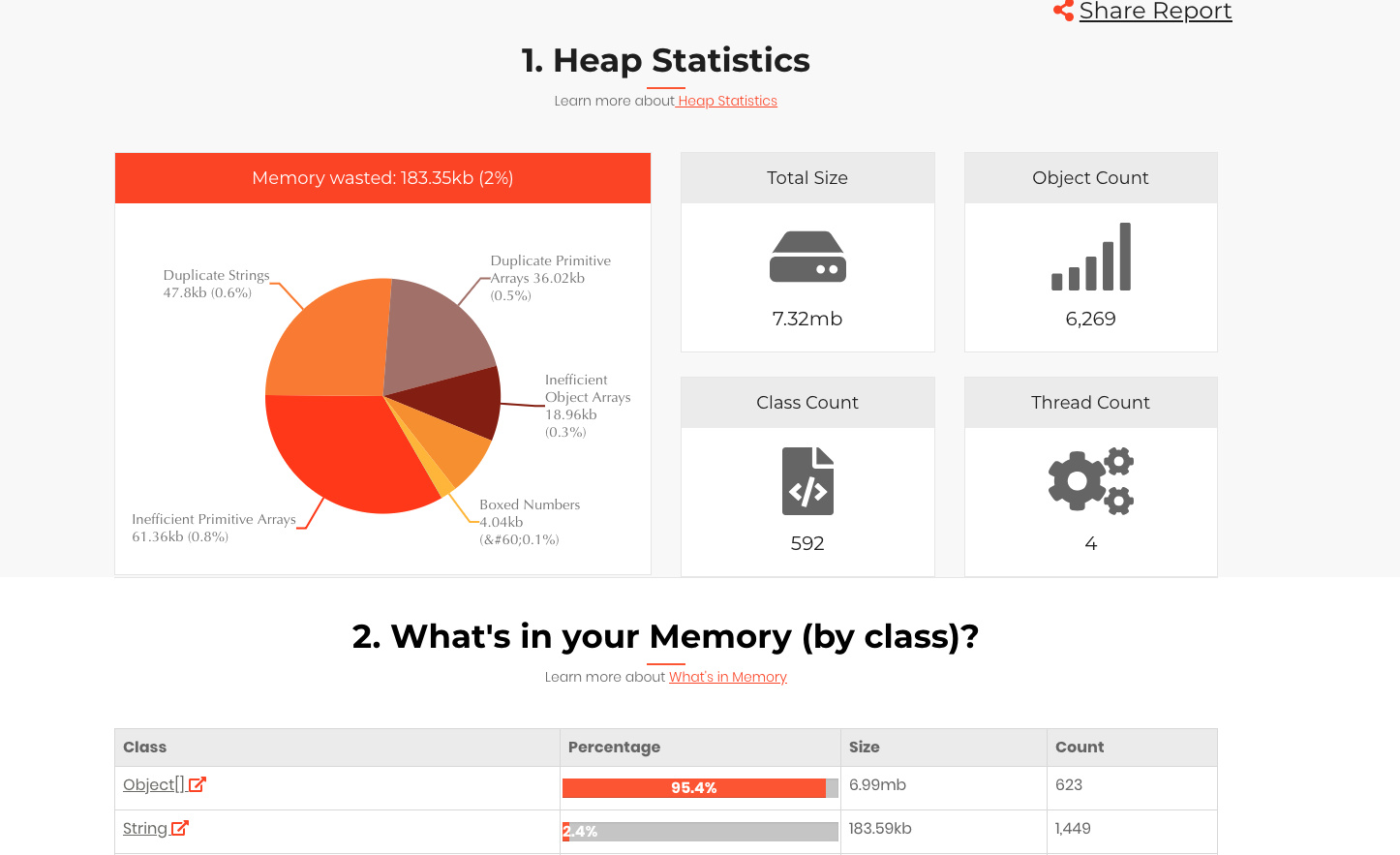
因为是内存溢出,所以主要观察下大对象:
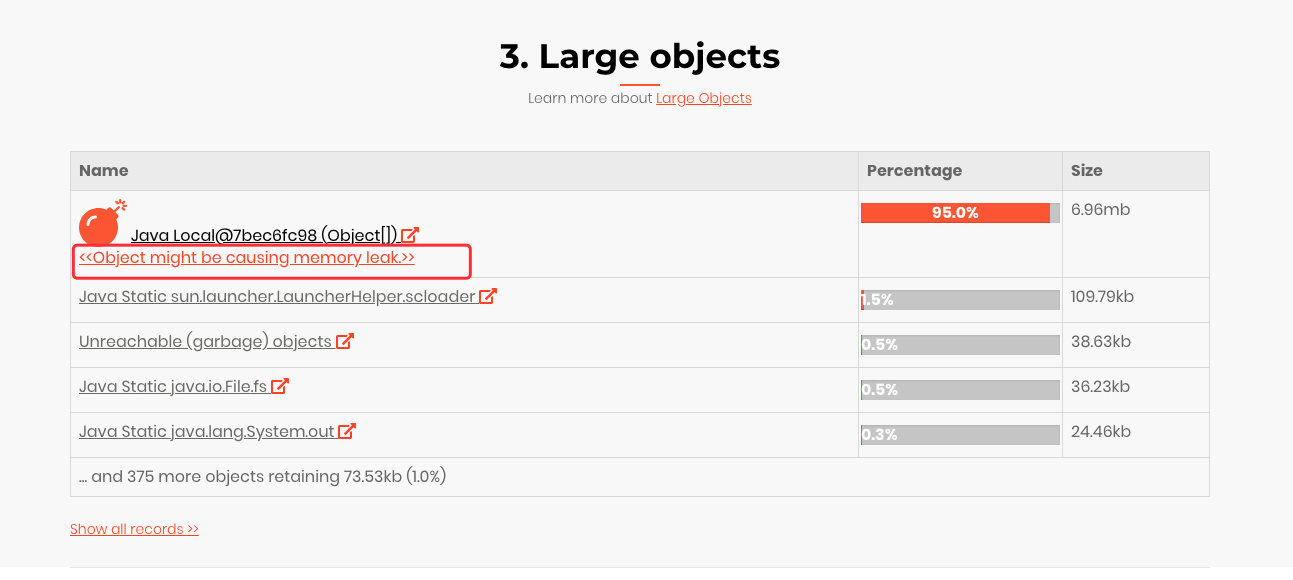
也有相应提示,这个很有可能就是内存溢出的对象,点进去之后:

看到这个堆栈其实就很明显了:
在向 ArrayList 中不停的写入数据时,会导致频繁的扩容也就是数组复制这些过程,最终达到 20M 的上限导致内存溢出了。
更多建议
上文说过,一旦使用了多线程,那就要格外小心。
以下是一些日常建议:
- 尽量不要在线程中做大量耗时的网络操作,如查询数据库(可以的话在一开始就将数据从从 DB 中查出准备好)。
- 尽可能的减少多线程竞争锁。可以将数据分段,各个线程分别读取。
- 多利用
CAS+自旋的方式更新数据,减少锁的使用。 - 应用中加上
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp参数,在内存溢出时至少可以拿到内存日志。 - 线程池监控。如线程池大小、队列大小、最大线程数等数据,可提前做好预估。
- JVM 监控,可以看到堆内存的涨幅趋势,GC 曲线等数据,也可以提前做好准备。
总结
线上问题定位需要综合技能,所以是需要一些基础技能。如线程、内存模型、Linux 等。
当然这些问题没有实操过都是纸上谈兵;如果第一次碰到线上问题,不要慌张,反而应该庆幸解决之后你又会习得一项技能。
号外
最近在总结一些 Java 相关的知识点,感兴趣的朋友可以一起维护。
欢迎关注公众号一起交流: