一份针对于新手的多线程实践--进阶篇

前言
在上文《一份针对于新手的多线程实践》留下了一个问题:
这只是多线程其中的一个用法,相信看到这里的朋友应该多它的理解更进一步了。
再给大家留个阅后练习,场景也是类似的:
在 Redis 或者其他存储介质中存放有上千万的手机号码数据,每个号码都是唯一的,需要在最快的时间内把这些号码全部都遍历一遍。
有想法感兴趣的朋友欢迎在文末留言参与讨论🤔🤨。
网友们的方案
我在公众号以及其他一些平台收到了大家的回复,果然是众人拾柴火焰高啊。


感谢每一位参与的朋友。
其实看了大家的方案大多都想到了数据肯定要分段,因为大量的数据肯定没法一次性 load 到内存。
但怎么加载就要考虑清楚了,有些人说放在数据库中通过分页的方式进行加载,然后将每页的数据丢到一个线程里去做遍历。
其实想法挺不错的,但有个问题就是:
这样肯定会导致有一个主线程去遍历所有的号码,即便是分页查询的那也得全部查询一遍,效率还是很低。
即便是分页加载号码用多线程,那就会涉及到锁的问题,怎么保证每个线程读取的数据是互不冲突的。
但如果存储换成 Redis 的 String 结构这样就更行不通了。
遍历数据方案
有没有一种利用多线程加载效率高,并且线程之间互相不需要竞争锁的方案呢?
下面来看看这个方案:
首先在存储这千万号码的时候我们把它的号段单独提出来并冗余存储一次。
比如有个号码是 18523981123 那么就还需要存储一个号段:1852398。
这样当我们有以下这些号码时:
18523981123 18523981124 18523981125 13123874321 13123874322 13123874323
我们就还会维护一个号段数据为:
1852398 1312387
这样我想大家应该明白下一步应当怎么做了吧。
在需要遍历时:
- 通过主线程先把所有的号段加载到内存,即便是千万的号码号段也顶多几千条数据。
- 遍历这个号段,将每个号段提交到一个
task线程中。 - 由这个线程通过号段再去查询真正的号码进行遍历。
- 最后所有的号段都提交完毕再等待所有的线程执行完毕即可遍历所有的号码。
这样做的根本原因其实是避免了线程之间加锁,通过号段可以让每个线程只取自己那一部分数据。
可能会有人说,如果号码持续增多导致号段的数据也达到了上万甚至几十万这怎么办呢?
那其实也是同样的思路,可以再把号段进行拆分。
比如之前是 1852398 的号段,那我继续拆分为 1852 。
这样只需要在之前的基础上再启动一个线程去查询子号段即可,有点 fork/join 的味道。
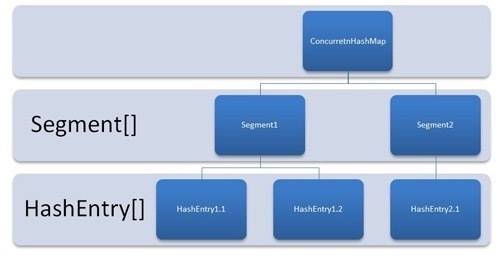
这样的思路其实也和 JDK1.7 中的 ConcurrentHashMap 类似,定位一个真正的数据需要两次定位。
分布式方案
上面的方案也是由局限性的,毕竟说到底还是一个单机应用。没法扩展;处理的数据始终是有上限。
这个上限就和服务器的配置以及线程数这些相关,说的高大上一点其实就是垂直扩展增加单机的处理性能。
因此随着数据量的提升我们肯定得需要通过水平扩展的方式才能达到最好的性能,这就是分布式的方案。
假设我现在有上亿的数据需要遍历,但我当前的服务器配置只能支撑一个应用启动 N 个线程 5 分钟跑5000W 的数据。
于是我水平扩展,在三台服务器上启动了三个独立的进程。假设一个应用能跑 5000W ,那么理论上来说三个应用就可以跑1.5亿的数据了。
但这个的前提还是和上文一样:每个应用只能处理自己的数据,不能出现加锁的情况(这样会大大的降低性能)。
所以我们得对刚才的号段进行分组。
先通过一张图来直观的表示这个逻辑:
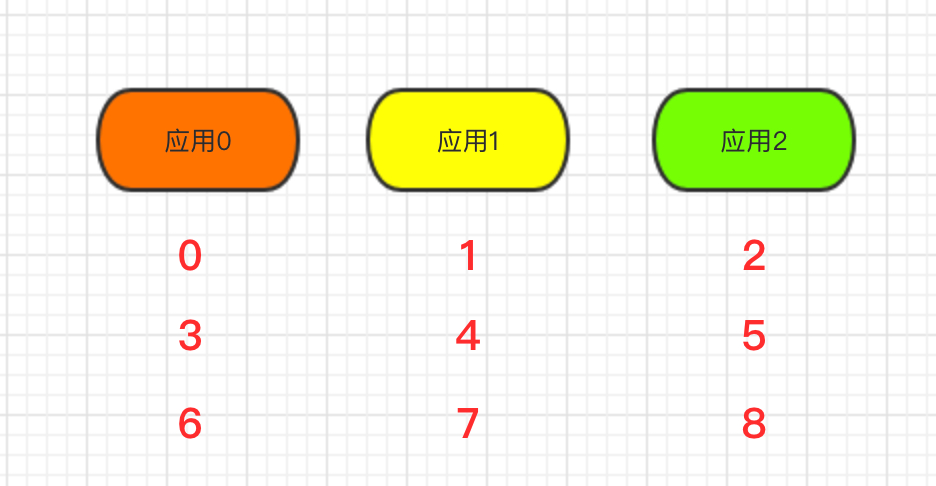
假设现在我有 9 个号段,那么我就得按照图中的方式把数据隔离开来。
第一个数据给应用0,第二个数据给应用1,第三个数据给应用2。后面的数据以此类推(就是一个简单的取模运算)。
这样就可以将号段均匀的分配给不同的应用来进行处理,然后每个应用再按照上文提到的将分配给自己的号段丢到线程池中由具体的线程去查询、遍历即可。
分布式带来的问题
这样看似没啥问题,但一旦引入了分布式之后就不可避免的会出现 CAP 的取舍,这里不做过多讨论,感兴趣的朋友可以自行搜索。
首先要解决的一个问题就是:
这三个应用怎么知道它自己应该取哪些号段的数据呢?比如 0 号应用就取 0 3 6(这个相当于号段的下标),难道在配置文件里配置嘛?
那如果数据量又增大了,对应的机器数也增加到了 5 台,那自然 0 号应用就不是取 0 3 6 了(取模之后数据会变)。
所以我们得需要一个统一的调度来分配各个应用他们应当取哪些号段,这也就是数据分片。
假设我这里有一个统一的分配中心,他知道现在有多少个应用来处理数据。还是假设上文的三个应用吧。
在真正开始遍历数据的时候,这个分配中心就会去告诉这三个应用:
你们要开始工作了啊,0 号应用你的工作内容是 0 3 6,1 号应用你的工作内容是 1 4 7,2 号应用你的工作内容是 2 5 8。
这样各个应用就知道他们所应当处理的数据了。
当我们新增了一个应用来处理数据时也很简单,同样这个分配中心知道现在有多少台应用会工作。
他会再拿着现有的号段对 4(3+1台应用) 进行取模然后对数据进行重新分配,这样就可以再次保证数据分配均匀了。
只是分配中心如何知道有多少应用呢,其实也简单,只要中心和应用之间通信就可以了。比如启动的时候调用分配中心的接口即可。
上面提到的这个分配中心其实就是一个常见的定时任务的分布式调度中心,由它来统一发起调度,当然分片只是它其中的一个功能而已(关于调度中心之后有兴趣再细说)。
总结
本次探讨了多线程的更多应用方式,如要是如何高效的运行。最主要的一点其实就是尽量的避免加锁。
同时对分布式水平扩展谈了一些处理建议,本次也是难得的一行代码都没贴,大家感兴趣的话在后面更新相关代码。
也欢迎大家留言讨论。😄
你的点赞与转发是最大的支持。