分享一些 Kafka 消费数据的小经验

前言
之前写过一篇《从源码分析如何优雅的使用 Kafka 生产者》 ,有生产者自然也就有消费者。
建议对 Kakfa 还比较陌生的朋友可以先看看。
就我的使用经验来说,大部分情况都是处于数据下游的消费者角色。也用 Kafka 消费过日均过亿的消息(不得不佩服 Kakfa 的设计),本文将借助我使用 Kakfa 消费数据的经验来聊聊如何高效的消费数据。
单线程消费
以之前生产者中的代码为例,事先准备好了一个 Topic:data-push,3个分区。
先往里边发送 100 条消息,没有自定义路由策略,所以消息会均匀的发往三个分区。
先来谈谈最简单的单线程消费,如下图所示:
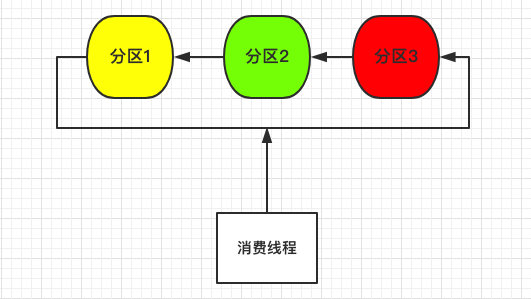
由于数据散列在三个不同分区,所以单个线程需要遍历三个分区将数据拉取下来。
单线程消费的示例代码:
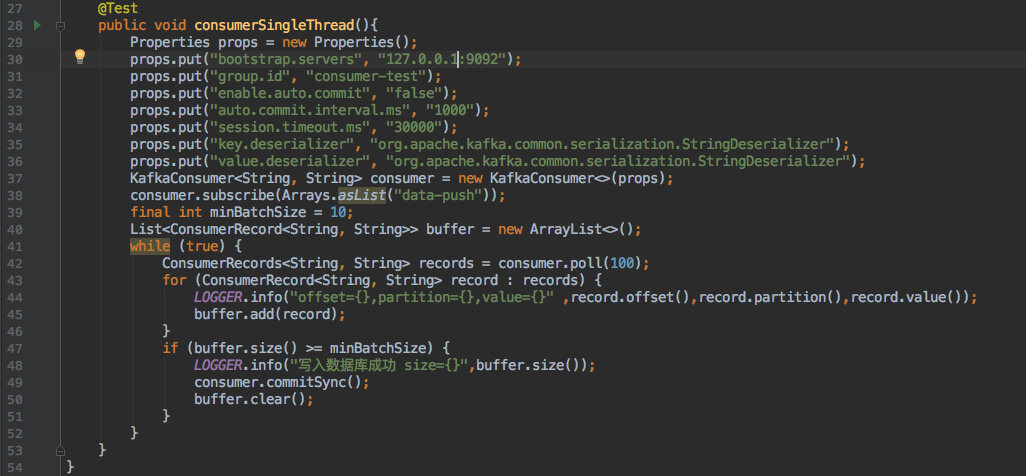
这段代码大家在官网也可以找到:将数据取出放到一个内存缓冲中最后写入数据库的过程。
先不讨论其中的 offset 的提交方式。
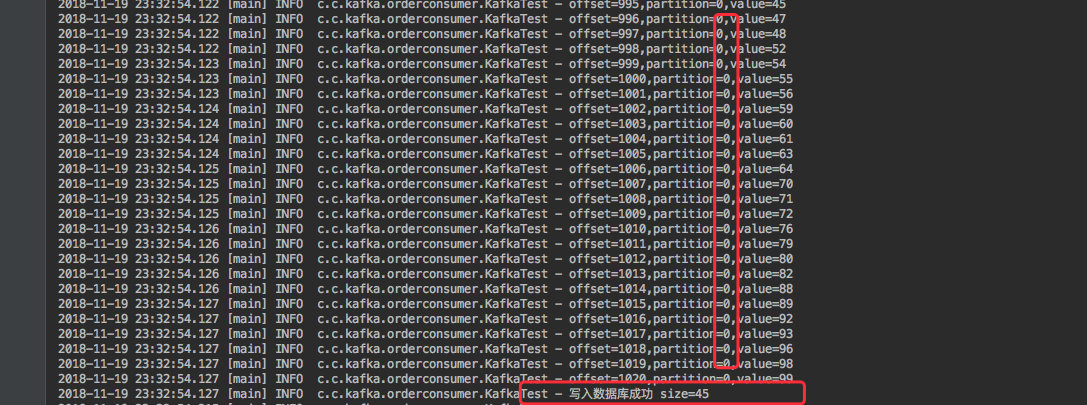
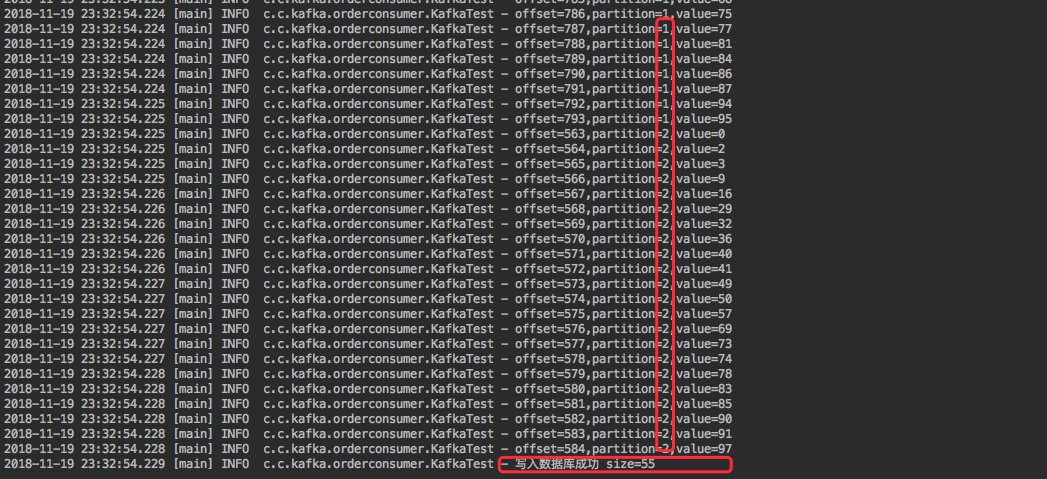
通过消费日志可以看出:
取出的 100 条数据确实是分别遍历了三个分区。
单线程消费虽然简单,但存在以下几个问题:
- 效率低下。如果分区数几十上百个,单线程无法高效的取出数据。
- 可用性很低。一旦消费线程阻塞,甚至是进程挂掉,那么整个消费程序都将出现问题。
多线程消费
既然单线程有诸多问题,那是否可以用多线程来提高效率呢?
在多线程之前不得不将消费模式分为两种进行探讨:消费组、独立消费者。
这两种消费模式对应的处理方式有着很大的不同,所以很有必要单独来讲。
独立消费者模式
先从独立消费者模式谈起,这种模式相对于消费组来说用的相对小众一些。
看一个简单示例即可知道它的用法:
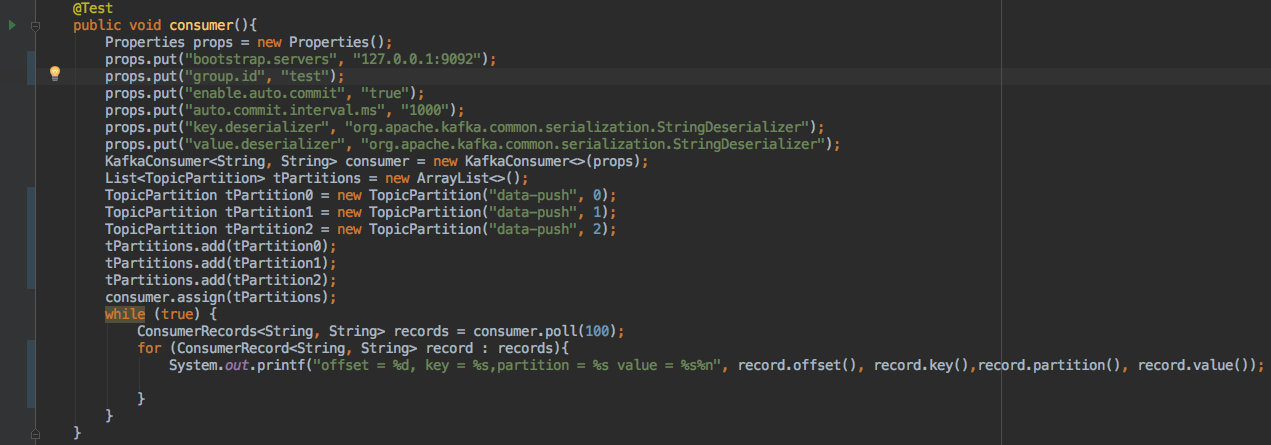
值得注意的是:独立消费者可以不设置 group.id 属性。
也是发送100条消息,消费结果如下:
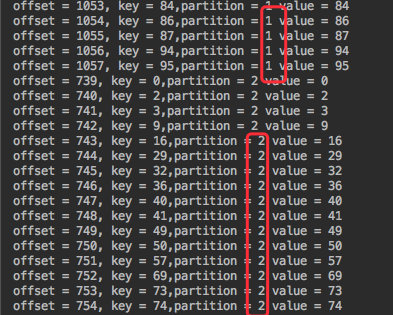
通过 API 可以看出:我们可以手动指定需要消费哪些分区。
比如 data-push Topic 有三个分区,我可以手动只消费其中的 1 2 分区,第三个可以视情况来消费。
同时它也支持多线程的方式,每个线程消费指定分区进行消费。
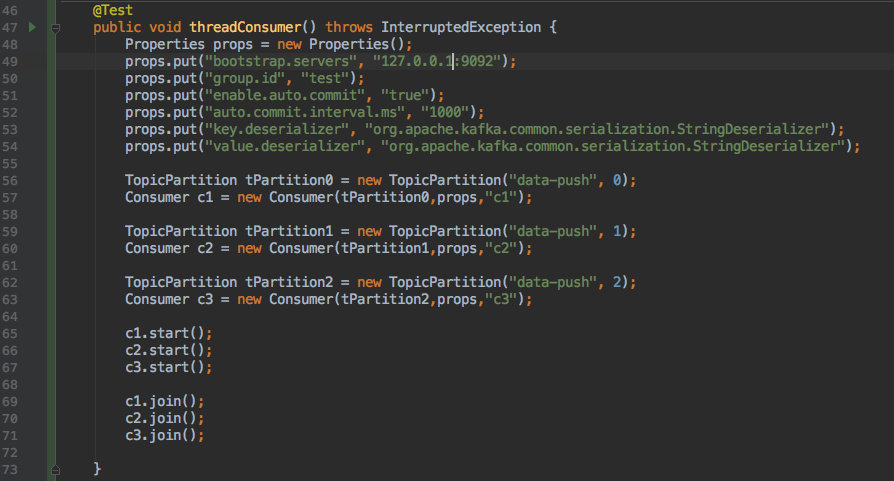
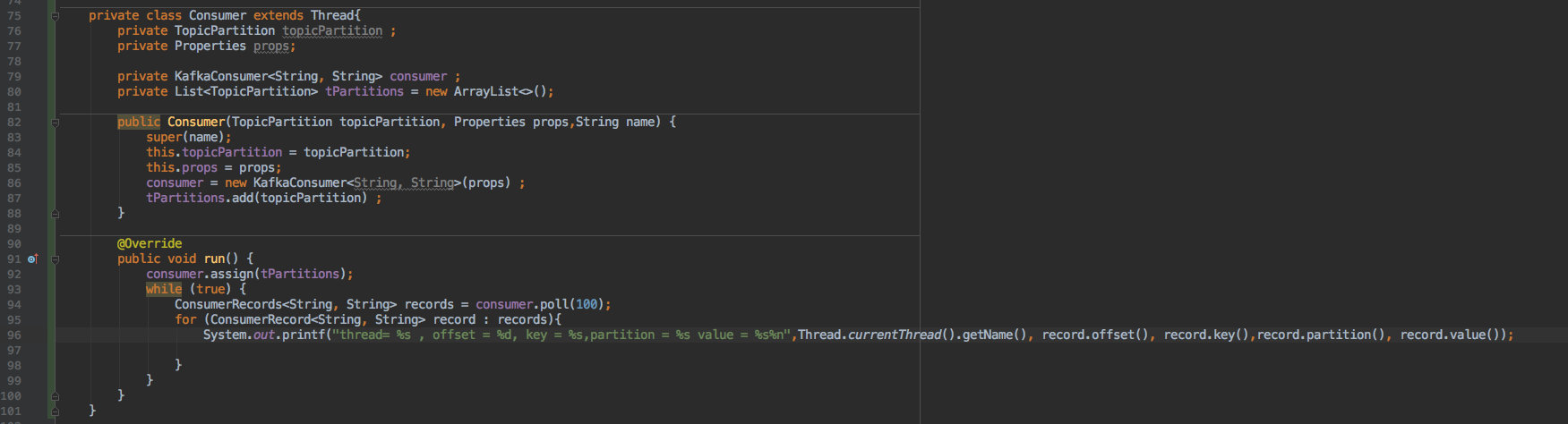
为了直观,只发送了 10 条数据。
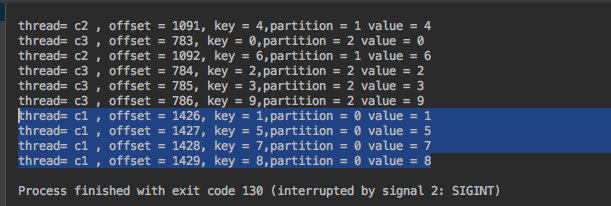
根据消费结果可以看出:
c1 线程只取 0 分区;c2 只取 1 分区;c3 只取 2 分区的数据。
甚至我们可以将消费者多进程部署,这样的消费方式如下:
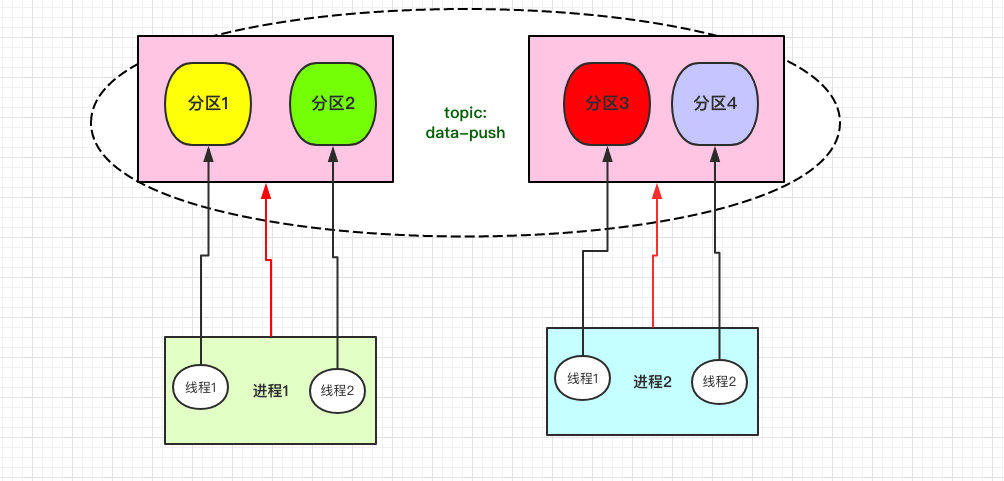
假设 Topic:data-push 的分区数为 4 个,那我们就可以按照图中的方式创建两个进程。
每个进程内有两个线程,每个线程再去消费对应的分区。
这样当我们性能不够新增 Topic 的分区数时,消费者这边只需要这样水平扩展即可,非常的灵活。
这种自定义分区消费的方式在某些场景下还是适用的,比如生产者每次都将某一类的数据只发往一个分区。这样我们就可以只针对这一个分区消费。
但这种方式有一个问题:可用性不高,当其中一个进程挂掉之后;该进程负责的分区数据没法转移给其他进程处理。
消费组模式
消费组模式应当是使用最多的一种消费方式。
我们可以创建 N 个消费者实例(new KafkaConsumer()),当这些实例都用同一个 group.id 来创建时,他们就属于同一个消费组。
在同一个消费组中的消费实例可以收到消息,但一个分区的消息只会发往一个消费实例。
还是借助官方的示例图来更好的理解它。
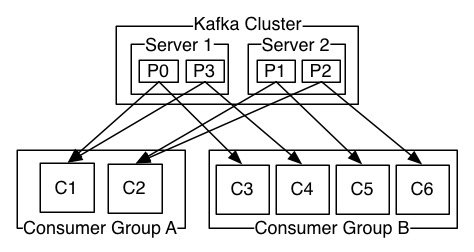
某个 Topic 有四个分区 p0 p1 p2 p3,同时创建了两个消费组 groupA,groupB。
- A 消费组中有两个消费实例
C1、C2。 - B 消费组中有四个消费实例
C3、C4、C5、C6。
这样消息是如何划分到每个消费实例的呢?
通过图中可以得知:
- A 组中的 C1 消费了 P0 和 P3 分区;C2 消费 P1、P2 分区。
- B 组有四个实例,所以每个实例消费一个分区;也就是消费实例和分区是一一对应的。
需要注意的是:
这里的消费实例简单的可以理解为
new KafkaConsumer,它和进程没有关系。
比如说某个 Topic 有三个分区,但是我启动了两个进程来消费它。
其中每个进程有两个消费实例,那其实就相当于有四个实例了。
这时可能就会问 4 个实例怎么消费 3 个分区呢?
消费组自平衡
这个 Kafka 已经帮我做好了,它会来做消费组里的 Rebalance。
比如上面的情况,3 个分区却有 4 个消费实例;最终肯定只有三个实例能取到消息。但至于是哪三个呢,这点 Kakfa 会自动帮我们分配好。
看个例子,还在之前的 data-push 这个 Topic,其中有三个分区。
当其中一个进程(其中有三个线程,每个线程对应一个消费实例)时,消费结果如下:
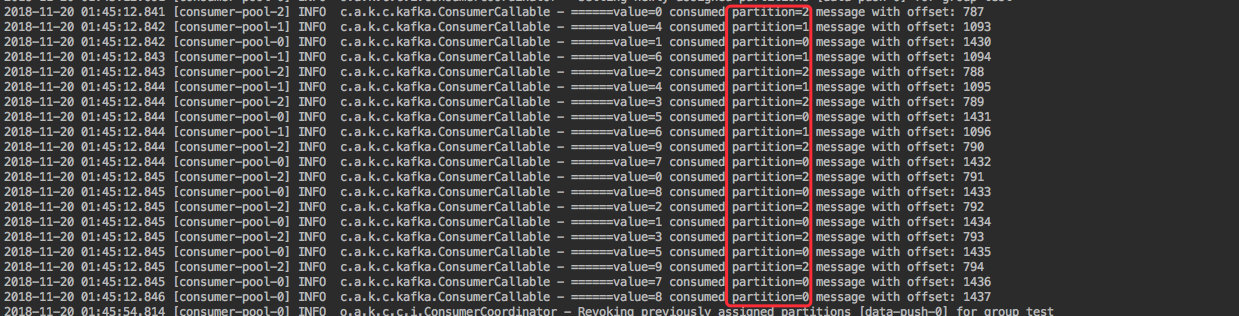
里边的 20 条数据都被这个进程的三个实例消费掉。
这时我新启动了一个进程,程序和上面那个一模一样;这样就相当于有两个进程,同时就是 6 个实例。
我再发送 10 条消息会发现:
进程1 只取到了分区 1 里的两条数据(之前是所有数据都是进程1里的线程获取的)。

同时进程2则消费了剩下的 8 条消息,分别是分区 0、2 的数据(总的还是只有三个实例取到了数据,只是分别在不同的进程里)。

当我关掉进程2,再发送10条数据时会发现所有数据又被进程1里的三个线程消费了。

通过这些测试相信大家已经可以看到消费组的优势了。
我们可以在一个消费组中创建多个消费实例来达到高可用、高容错的特性,不会出现单线程以及独立消费者挂掉之后数据不能消费的情况。同时基于多线程的方式也极大的提高了消费效率。
而当新增消费实例或者是消费实例挂掉时 Kakfa 会为我们重新分配消费实例与分区的关系就被称为消费组 Rebalance。
发生这个的前提条件一般有以下几个:
- 消费组中新增消费实例。
- 消费组中消费实例 down 掉。
- 订阅的 Topic 分区数发生变化。
- 如果是正则订阅 Topic 时,匹配的 Topic 数发生变化也会导致
Rebalance。
所以推荐使用这样的方式消费数据,同时扩展性也非常好。当性能不足新增分区时只需要启动新的消费实例加入到消费组中即可。
总结
本次只分享了几个不同消费数据的方式,并没有着重研究消费参数、源码;这些内容感兴趣的话可以在下次分享。
文中提到的部分源码可以在这里查阅:
https://github.com/crossoverJie/JCSprout
欢迎关注公众号一起交流: