Pulsar压测及优化

前言
这段时间在做 MQ(Pulsar)相关的治理工作,其中一个部分内容关于消息队列的升级,比如:
- 一键创建一个测试集群。
- 运行一批测试用例,覆盖我们线上使用到的功能,并输出测试报告。
- 模拟压测,输出测试结果。
本质目的就是想直到新版本升级过程中和升级后对现有业务是否存在影响。
一键创建集群和执行测试用例比较简单,利用了 helm 和 k8s client 的 SDK 把整个流程串起来即可。
压测
其实稍微麻烦一点的是压测,Pulsar 官方本身是有提供一个压测工具;只是功能相对比较单一,只能对某批 topic 极限压测,最后输出测试报告。
最后参考了官方的压测流程,加入了一些实时监控数据,方便分析整个压测过程中性能的变化。
客户端 timeout
随着压测过程中的压力增大,比如压测时间和线程数的提高,客户端会抛出发送消息 timeout 异常。
1 | org.apache.pulsar.client.api.PulsarClientException$TimeoutException: |
而这个异常在生产业务环境的高峰期偶尔也出现过,这会导致业务数据的丢失;所以正好这次被我复现出来后想着分析下产生的原因以及解决办法。
源码分析客户端
既然是客户端抛出的异常所以就先看从异常点开始看起,其实整个过程和产生的原因并不复杂,如下图:
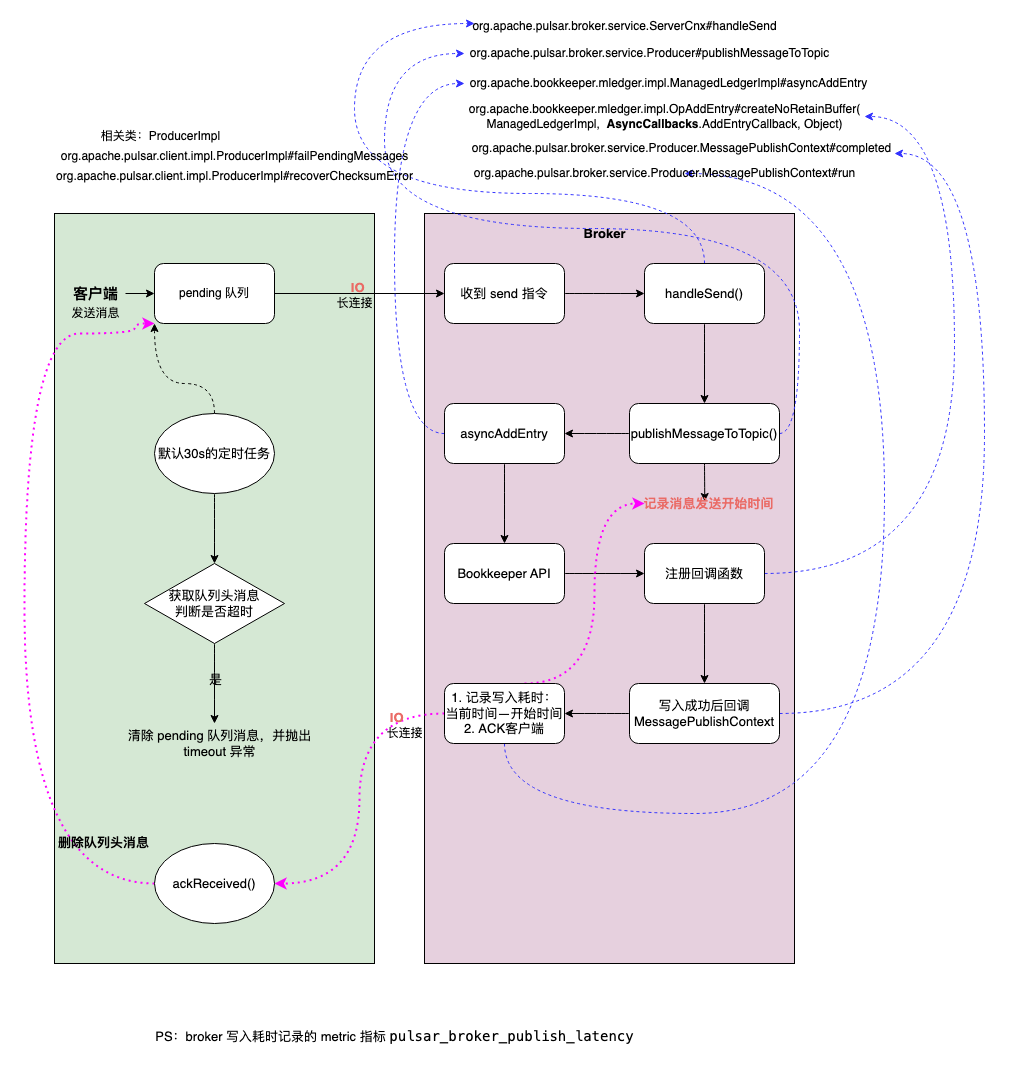
客户端流程:
- 客户端 producer 发送消息时先将消息发往本地的一个 pending 队列。
- 待 broker 处理完(写入 bookkeeper) 返回 ACK 时删除该 pending 队列头的消息。
- 后台启动一个定时任务,定期扫描队列头(头部的消息是最后写入的)的消息是否已经过期(过期时间可配置,默认30s)。
- 如果已经过期(头部消息过期,说明所有消息都已过期)则遍历队列内的消息依次抛出
PulsarClientException$TimeoutException异常,最后清空该队列。
服务端 broker 流程:
- 收到消息后调用 bookkeeper API 写入消息。
- 写入消息时同时写入回调函数。
- 写入成功后执行回调函数,这时会记录一条消息的写入延迟,并通知客户端 ACK。
- 通过 broker metric 指标
pulsar_broker_publish_latency可以获取写入延迟。
从以上流程可以看出,如果客户端不做兜底措施则在第四步会出现消息丢失,这类本质上不算是 broker 丢消息,而是客户端认为当时 broker 的处理能力达到上限,考虑到消息的实时性从而丢弃了还未发送的消息。
性能分析
通过上述分析,特别是 broker 的写入流程得知,整个写入的主要操作便是写入 bookkeeper,所以 bookkeeper 的写入性能便关系到整个集群的写入性能。
极端情况下,假设不考虑网络的损耗,如果 bookkeeper 的写入延迟是 0ms,那整个集群的写入性能几乎就是无上限;所以我们重点看看在压测过程中 bookkeeper 的各项指标。
CPU
首先是 CPU: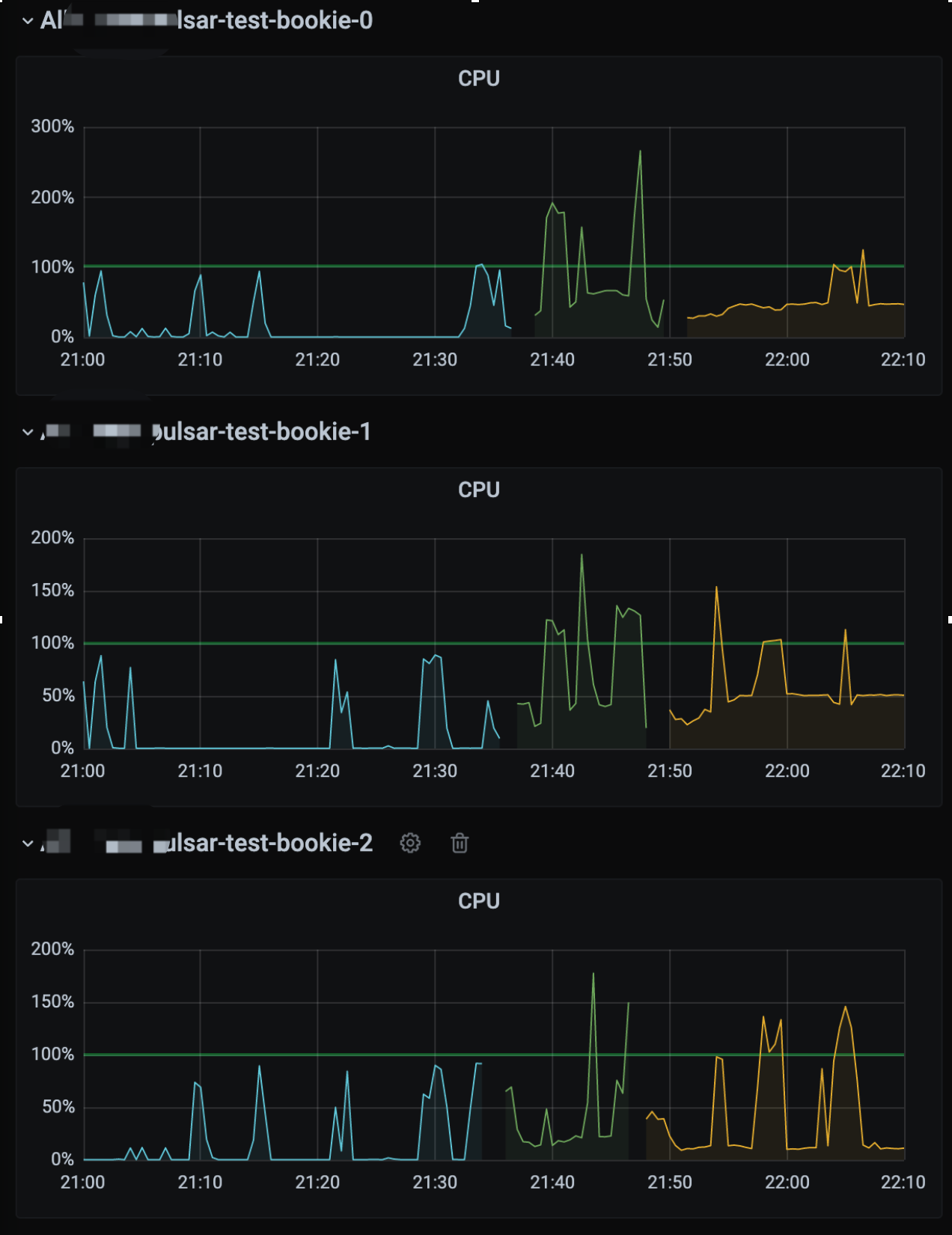
从图中可以看到压测过程中 CPU 是有明显增高的,所以我们需要找到压测过程中 bookkeeper 的 CPU 大部分损耗在哪里?
这里不得不吹一波阿里的 arthas 工具,可以非常方便的帮我们生成火焰图。
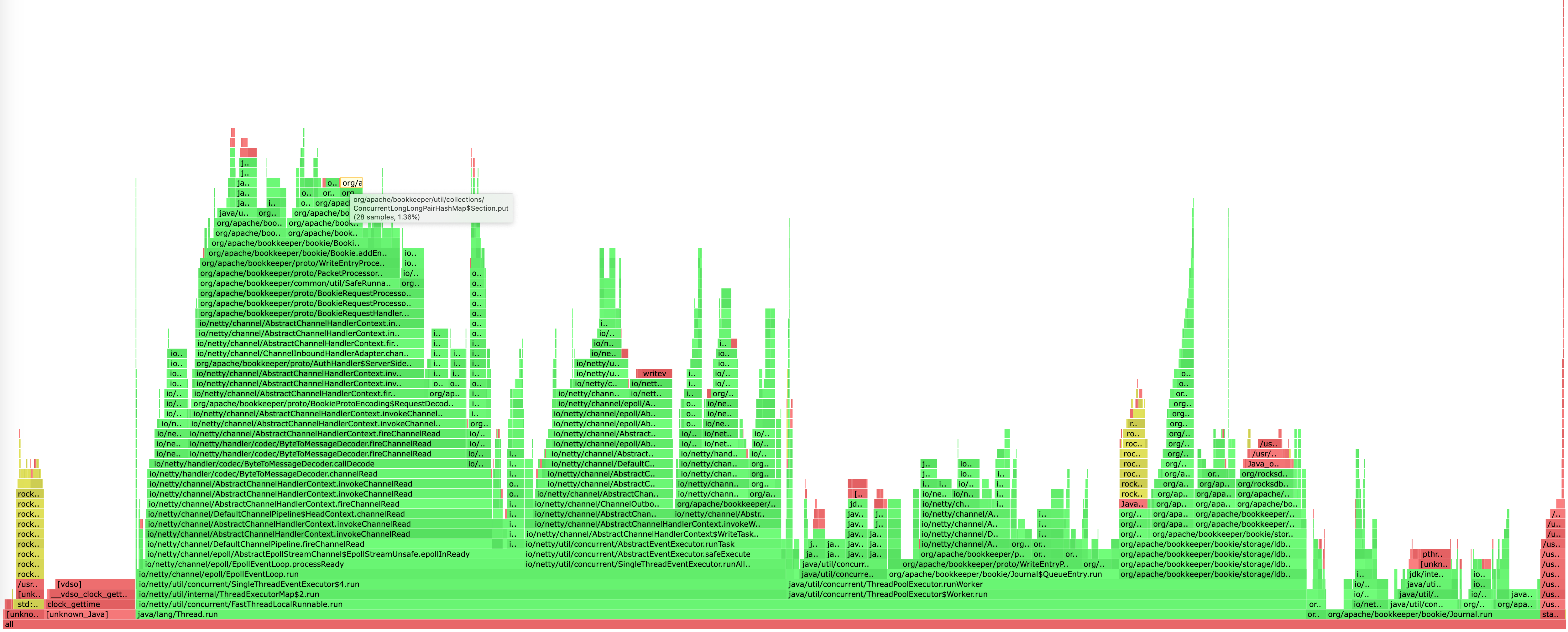
分析火焰图最简单的一个方法便是查看顶部最宽的函数是哪个,它大概率就是性能的瓶颈。
在这个图中的顶部并没有明显很宽的函数,大家都差不多,所以并没有明显损耗 CPU 的函数。
此时在借助云厂商的监控得知并没有得到 CPU 的上限(limit 限制为 8核)。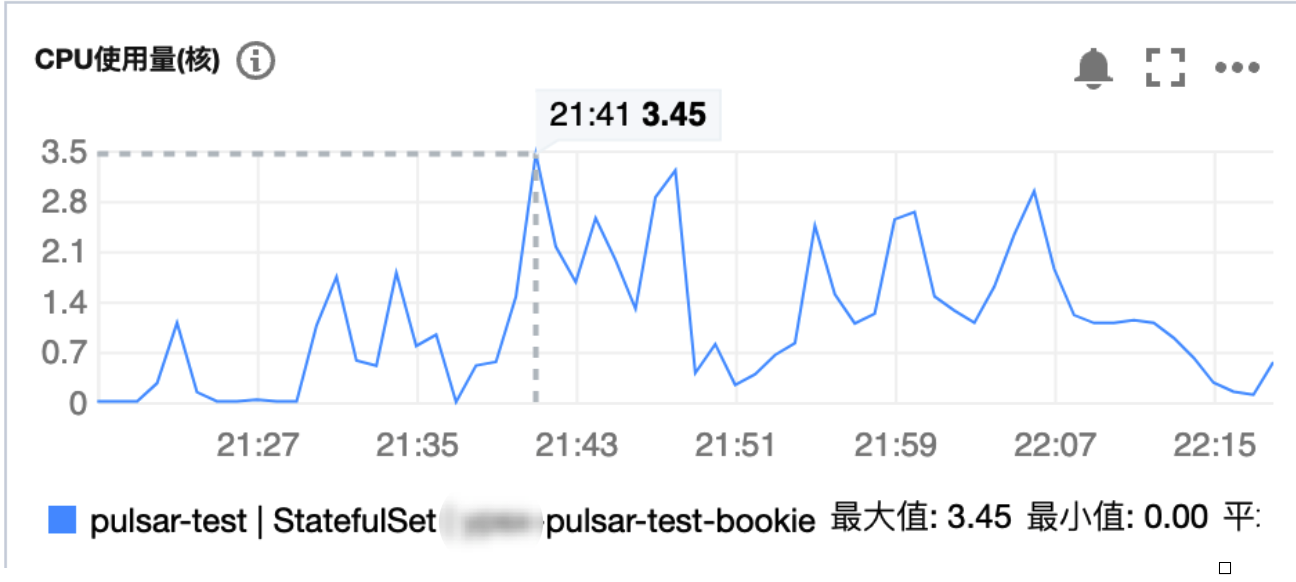
使用 arthas 过程中也有个小坑,在 k8s 环境中有可能应用启动后没有成功在磁盘写入 pid ,导致查询不到 Java 进程。
1 | $ java -jar arthas-boot.jar |
此时可以直接 ps 拿到进程 ID,然后在启动的时候直接传入 pid 即可。
1 | $ java -jar arthas-boot.jar 1 |
通常情况下这个 pid 是 1。
磁盘
既然 CPU 没有问题,那就再看看磁盘是不是瓶颈;
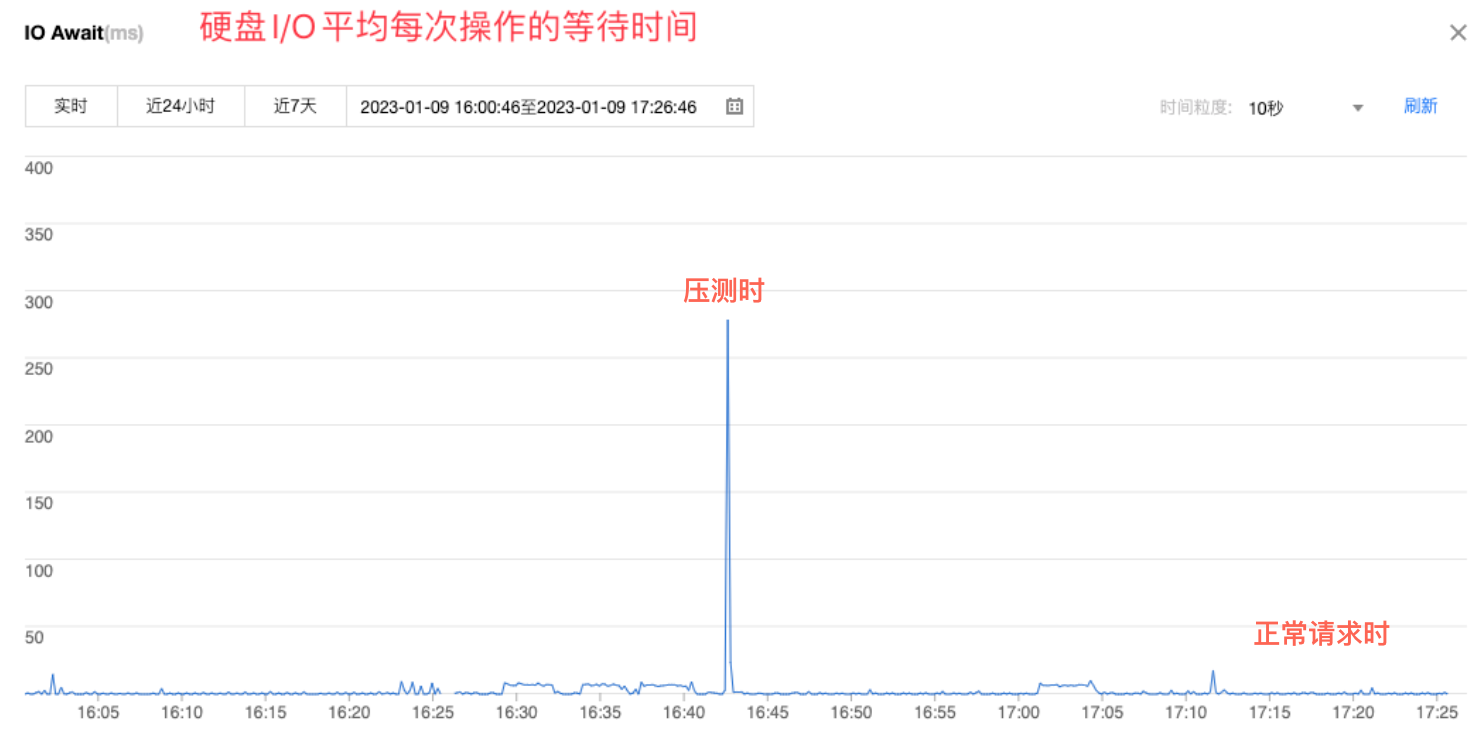
可以看到压测时的 IO 等待时间明显是比日常请求高许多,为了最终确认是否是磁盘的问题,再将磁盘类型换为 SSD 进行测试。
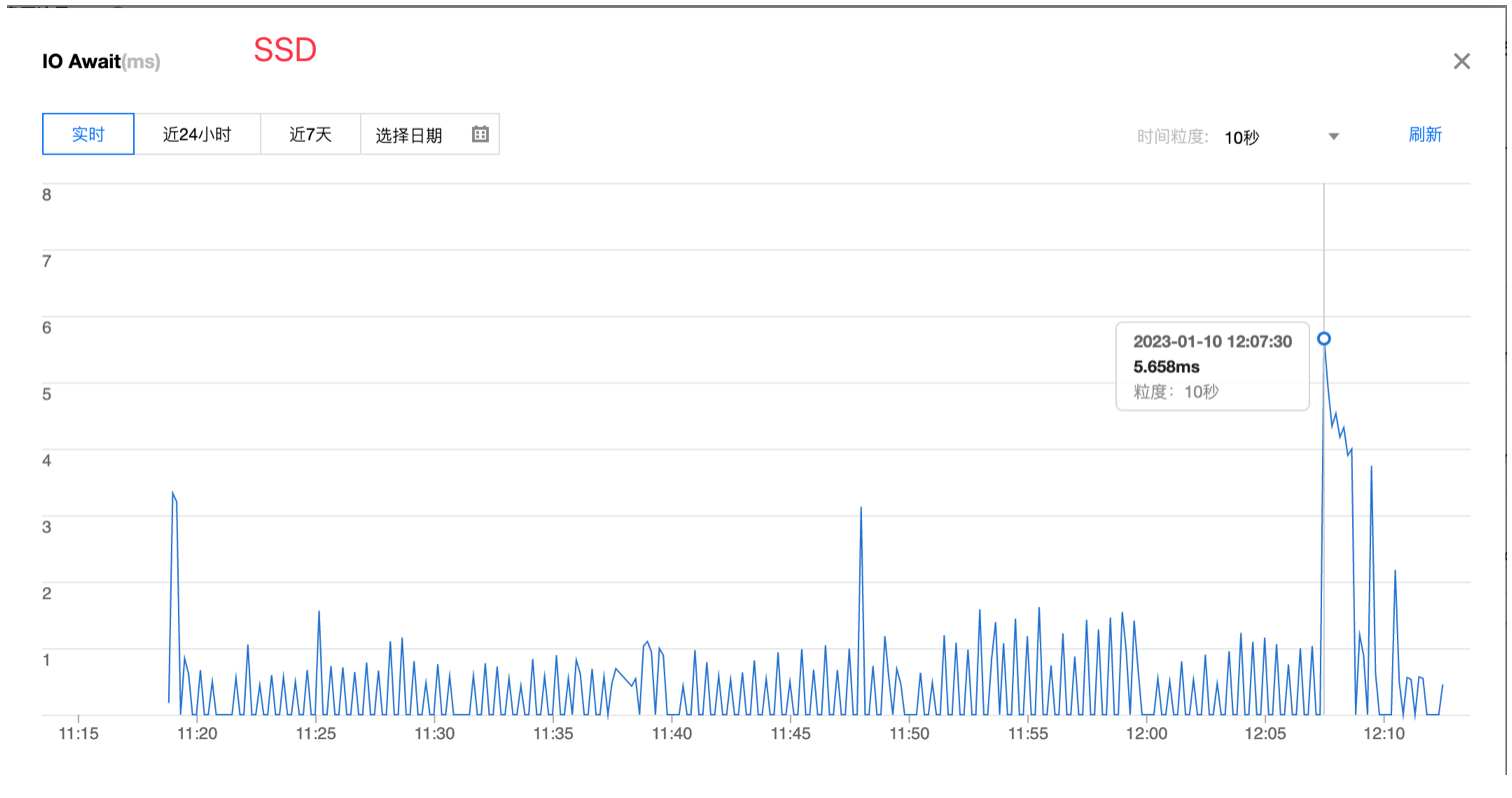
果然即便是压测,SSD磁盘的 IO 也比普通硬盘的正常请求期间延迟更低。
既然磁盘 IO 延迟降低了,根据前文的分析理论上整个集群的性能应该会有明显的上升,因此对比了升级前后的消息 TPS 写入指标:
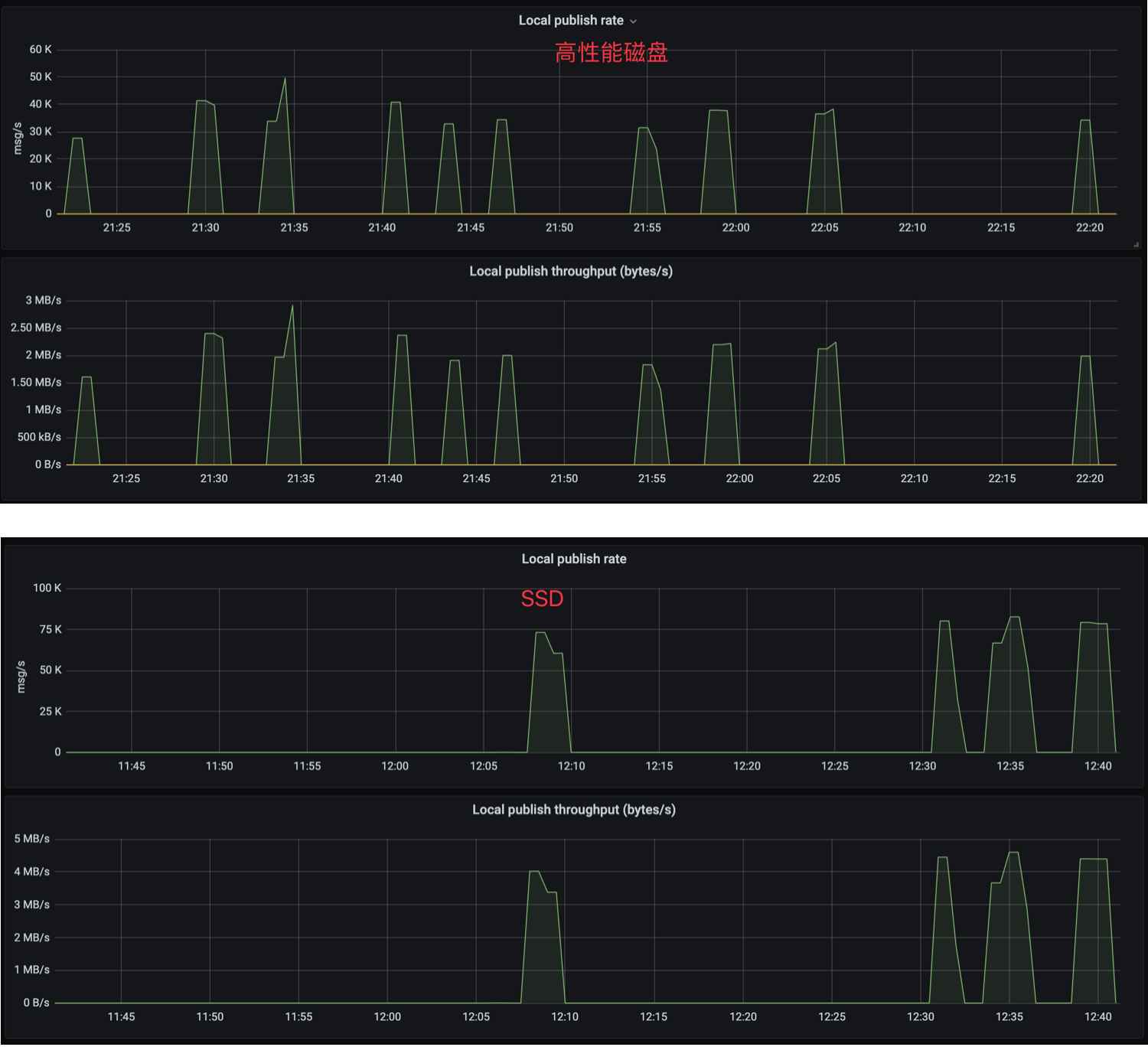
升级后每秒的写入速率由 40k 涨到 80k 左右,几乎是翻了一倍(果然用钱是最快解决问题的方式);
但即便是这样,极限压测后依然会出现客户端 timeout,这是因为无论怎么提高服务端的处理性能,依然没法做到没有延迟的写入,各个环节都会有损耗。
升级过程中的 timeout
还有一个关键的步骤必须要覆盖:模拟生产现场有着大量的生产者和消费者接入收发消息时进行集群升级,对客户端业务的影响。
根据官方推荐的升级步骤,流程如下:
- Upgrade Zookeeper.
- Disable autorecovery.
- Upgrade Bookkeeper.
- Upgrade Broker.
- Upgrade Proxy.
- Enable autorecovery.
其中最关键的是升级 Broker 和 Proxy,因为这两个是客户端直接交互的组件。
本质上升级的过程就是优雅停机,然后使用新版本的 docker 启动;所以客户端一定会感知到 Broker 下线后进行重连,如果能快速自动重连那对客户端几乎没有影响。
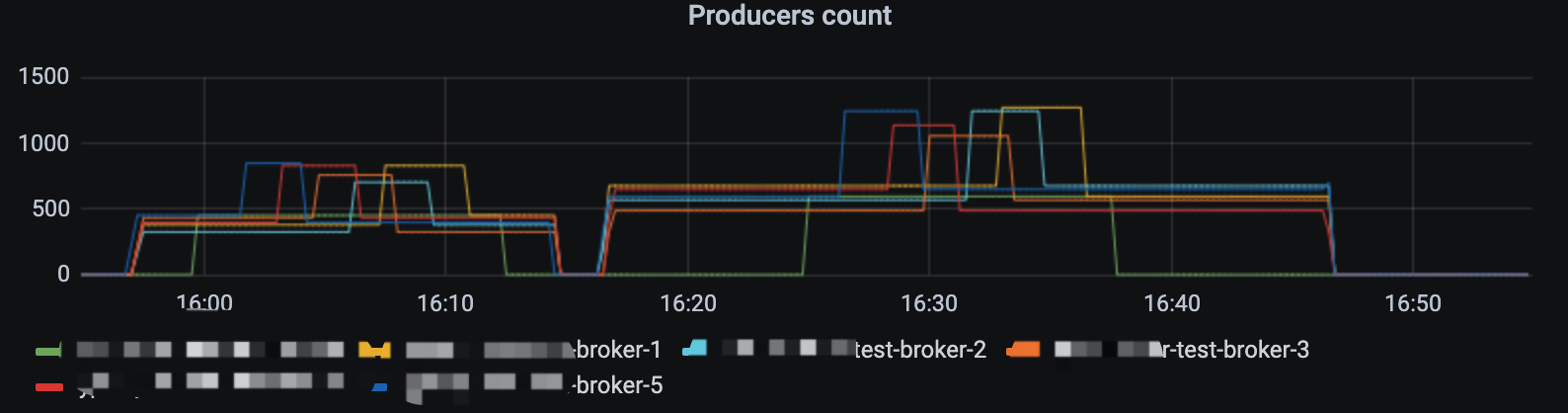
在我的测试过程中,2000左右的 producer 以 1k 的发送速率进行消息发送,在 30min 内完成所有组件升级,整个过程客户端会自动快速重连,并不会出现异常以及消息丢失。
而一旦发送频率增加时,在重启 Broker 的过程中便会出现上文提到的 timeout 异常;初步看起来是在默认的 30s 时间内没有重连成功,导致积压的消息已经超时。
经过分析源码发现关键的步骤如下: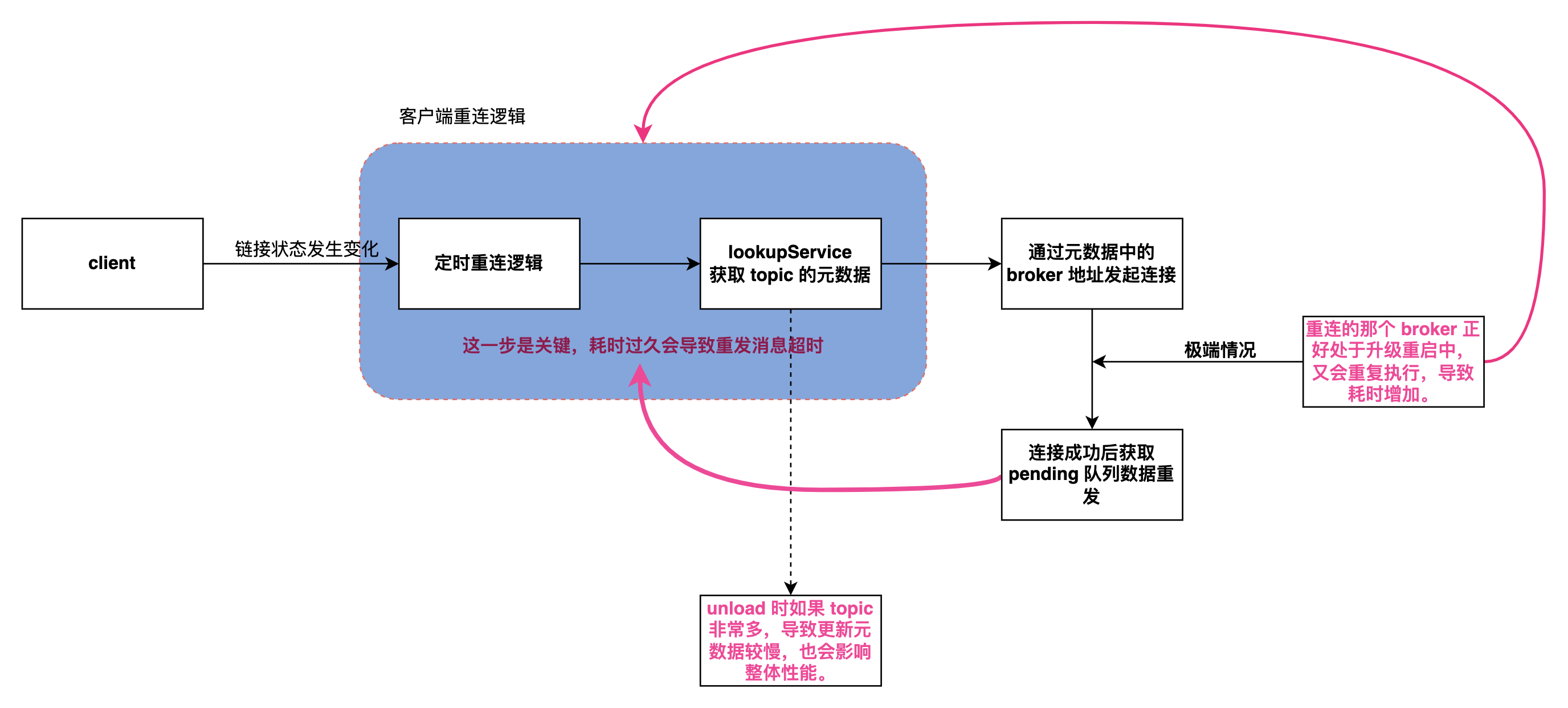
客户端在与 Broker 的长连接状态断开后会自动重连,而重连到具体哪台 Broker 节点是由 LookUpService 处理的,它会根据使用的 topic 获取到它的元数据。
理论上这个过程如果足够快,对客户端就会越无感。
在元数据中包含有该 topic 所属的 bundle 所绑定的 Broker 的具体 IP+端口,这样才能重新连接然后发送消息。
bundle 是一批 topic 的抽象,用来将一批 topic 与 Broker 绑定。
而在一个 Broker 停机的时会自动卸载它所有的 bundle,并由负载均衡器自动划分到在线的 Broker 中,交由他们处理。
这里会有两种情况降低 LookUpSerive 获取元数据的速度:
因为所有的 Broker 都是 stateful 有状态节点,所以升级时是从新的节点开始升级,假设是broker-5,假设升级的那个节点的 bundle 切好被转移 broker-4中,客户端此时便会自动重连到 4 这个Broker 中。
此时客户端正在讲堆积的消息进行重发,而下一个升级的节点正好是 4,那客户端又得等待 bundle 成功 unload 到新的节点,如果恰好是 3 的话那又得套娃了,这样整个消息的重发流程就会被拉长,直到超过等待时间便会超时。
还有一种情况是 bundle 的数量比较多,导致上面讲到的 unload 时更新元数据到 zookeeper 的时间也会增加。
所以我在考虑 Broker 在升级过程中时,是否可以将 unload 的 bundle 优先与
Broker-0进行绑定,最后全部升级成功后再做一次负载均衡,尽量减少客户端重连的机会。
解决方案
如果我们想要解决这个 timeout 的异常,也有以下几个方案:
- 将 bookkeeper 的磁盘换为写入时延更低的 SSD,提高单节点性能。
- 增加 bookkeeper 节点,不过由于 bookkeeper 是有状态的,水平扩容起来比较麻烦,而且一旦扩容再想缩容也比较困难。
- 增加客户端写入的超时时间,这个可以配置。
- 客户端做好兜底措施,捕获异常、记录日志、或者入库都可以,后续进行消息重发。
- 为 bookkeeper 的写入延迟增加报警。
- Spring 官方刚出炉的 Pulsar-starter 已经内置了 producer 相关的 metrics,客户端也可以对这个进行监控报警。
以上最好实现的就是第四步了,效果好成本低,推荐还没有实现的都尽快 try catch 起来。
整个测试流程耗费了我一两周的时间,也是第一次全方位的对一款中间件进行测试,其中也学到了不少东西;不管是源码还是架构都对 Pulsar 有了更深入的理解。